acl2021-CLEVE论文阅读
acl2021-CLEVE论文阅读
1. abstract
事件抽取(event extraction)通过从预训练语言模型中微调中受益匪浅。然而现有的预训练方法没有涉及对事件的特征进行建模,导致所开发的事件抽取模型无法充分利用大规模无监督数据。为此,我们提出了CLEVE,这是一个用于事件抽取的对比学习预训练框架,用于更好的从大型无监督数据中学习事件知识,以及使用自动解析器获得的语义结构(例如AMR)
「AMR (Abstract Meaning Representation,抽象意义表示) 是自然语言处理中的一种语义表示形式,旨在将自然语言的语义转化为计算机可处理的形式。它是一种图形表示形式,其中每个节点表示句子中的一个词或短语,而每个边表示它们之间的关系。
AMR 可以帮助计算机理解句子的语义,包括句子中的实体、动作和事件,并将它们转化为计算机可理解的结构。它能够处理语言的歧义和多义性,并提供更加准确和一致的语义表示。AMR 还能够被用于问答系统、机器翻译和文本摘要等应用中。」
CLEVE分别包含用于学习事件语义的文本编码器和用于学习事件结构的图编码器。具体地,
文本编码器通过自监督对比学习来学习事件语义表示,以表示与那些不相关的词更接近的相同事件的词。
图编码器通过对解析的事件相关语义结构进行图对比预训练来学习事件结构表示。
然后,这两种互补的表示一起工作,以改进传统的有监督事件抽取和无监督的自由事件抽取,这需要在没有任何标记数据的情况下联合提取事件和发现事件模式。
在ACE2005和MAVEN数据集上的实验表明,CLEVE取得了显著的改进,尤其是在具有挑战性的无监督环境中。
2. Introduction
事件抽取是一项长期存在的关键信息提取任务,旨在从费结构化文本中提取事件结构。
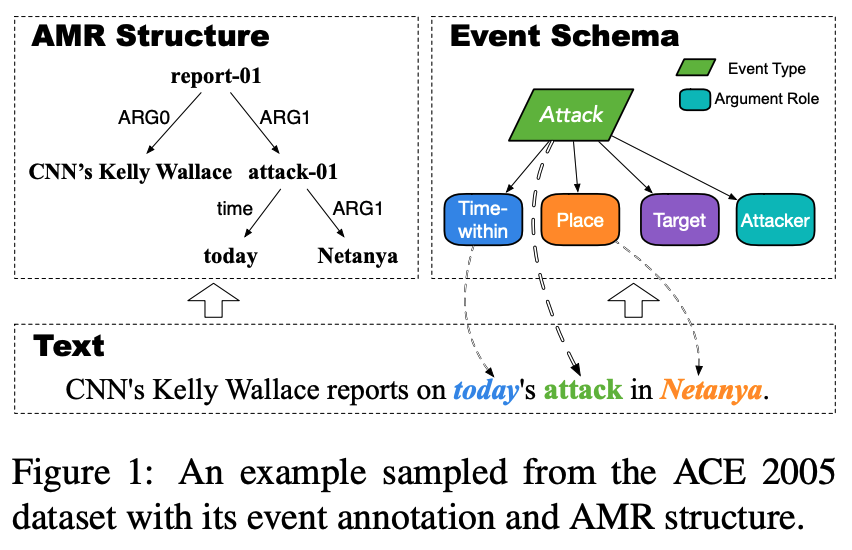
如图1所示,它包含用于识别事件触发器(单词attack)和分类事件类型(Attack)的事件检测任务,以及用于识别充当事件自变量的实体(today和Netanya),并分类其自变量角色(time within和place),通过显式地捕捉文本中的事件结构,事件抽取可以作用于各种下游任务,例如信息检索和知识库填充。
现在的事件抽取方法主要遵循监督学习范式来训练高级神经网络,使用人工标注的数据集和预定义的事件图式。这些方法在许多公共数据集上表现比较好例如ACE2005,但他们仍然存在数据稀缺和可推广性有限的问题。由于标记事件数据和定义事件模式特别昂贵且费力,现有的事件抽取数据集通常只包含数千个实例,并且涵盖有限的事件类型。因此,他们不足以训练大型神经模型,也不足以开发可以推广到不断出现的新事件类型的方法。
受最近针对NLP任务的预训练语言模型(PLMs)成功的启发,一些开创性的工作视图微调事件抽取的通用预训练语言模型,例如BERT。得益于从大规模无监督数据中学习到的强大通用语言理解能力,这些基于PLM的方法在各种公共基准中取得了最先进的性能。
尽管利用无监督数据进行预训练已经逐渐成为事件抽取和NLP社区的共识,但仍然缺乏一种面向事件建模的预训练方法来充分利用大规模无监督数据中丰富的事件知识,这里的关键挑战是为事件的不同语义和复杂结构找到合理的自监督信号。幸运的是之前的工作表明,句子语义结构,如抽象语义表示AMR,包含与事件相关的广泛而多样的语义和结构信息。如图1所示,解析后的AMR结构不仅涵盖了标注事件Attack,还涵盖了未定义的事件Report
这里是不是说利用了ACE2005数据集中的其他标记,把这个当做自监督学习的基准
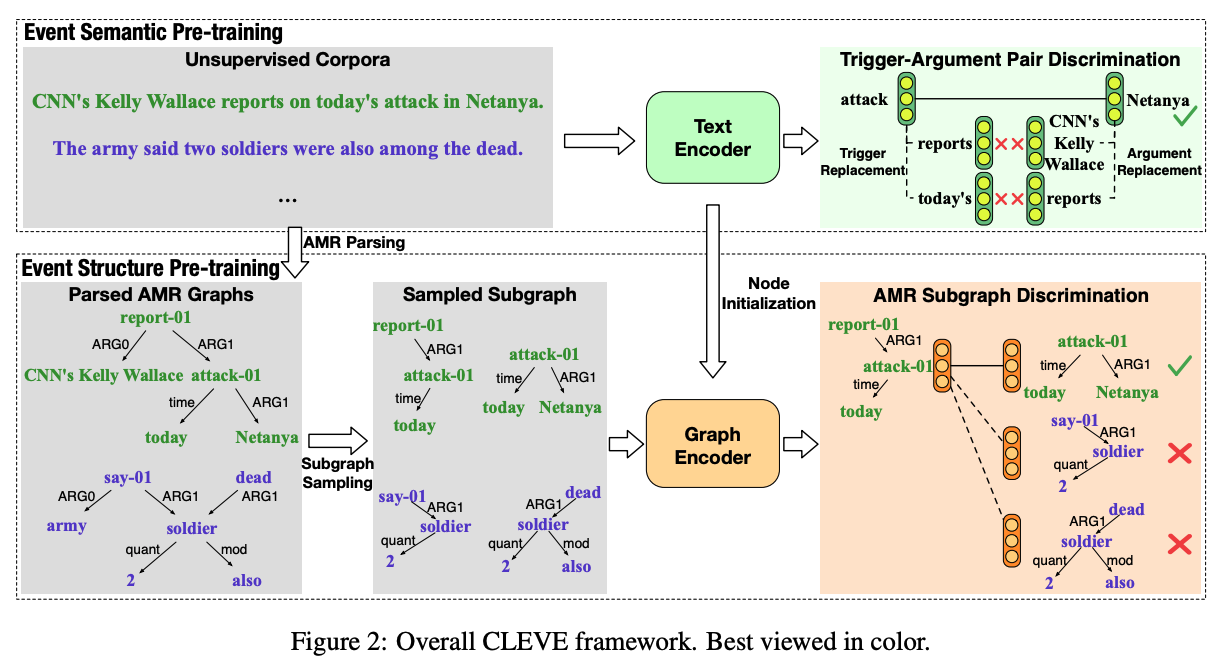
考虑到使用自动解析器可以很容易地获得大规模无监督数据集的AMR结构,我们提出了CLEVE,这是一种面向事件的对比预训练框架,利用AMR结构来构建自监督信号。CLEVE由两个组件组成,包括用于学习事件语义的文本编码器和用于学习事件结构信息的图编码器。具体来说,为了学习有效的事件语义表示,我们使用PLM作为文本编码器,并鼓励AMR结构中由ARG、时间、位置”边Edge“连接的词对的表示,在语义空间中比其他不相关的词更接近,因为这些通常指的是相同事件的触发参数对。这是通过对比学习完成的,将连接的单词对作为正样本,将不相关的单词作为负样本。此外,考虑到事件结构也有助于提取事件和推广到新的事件图式,我们需要学习可转移的事件结构表示。因此,我们进一步引入了图神经网络作为图编码器,将AMR结构编码为结构表示。以AMR子图判别为目标,在解析的大型无监督语料库的AMR结构上对图编码器进行对比预训练。
连接的词比不连接的词语义表征更接近,这块是不是有点问题,或者说不全面
通过在下游EE数据集上微调两个预先训练的模型,并联合使用这两种表示,CLEVE可以使遭受数据稀缺的传统监督EE受益。同时,预训练的表示也可以直接帮助提取事件并发现新的事件模式,而不需要任何已知的事件模式或注释实例,从而获得更好的可推广性。这是一个具有挑战性的无监督设置,名为“自由事件提取”(Huang et al.,2016)。在广泛使用的ACE 2005和大型MAVEN数据集上的实验表明,CLEVE可以在这两种设置中实现显著改进。
3. Methodology
整个CLEVE的框架如图2所示,对比学习的框架由两个部分组成:事件语义预训练和事件结构预训练。
3.1 预处理Preprocessing
CLEVE依赖于AMR结构来构建广泛而多样的自监督信号,用于从大规模无监督语料库中学习事件知识。为此,我们使用自动AMR解析器将无监督语料库中的句子解析为AMR结构。每个AMR结构都是一个有向无环图,概念作为节点,语义关系作为边。此外,每个节点通常只对应于最多一个单词,一个由多个单词组成的实体会被表示为一个由节点列表组成的图,这些节点通过name和op(连接操作符)边连接在一起。考虑到预训练实体表示自然有利于事件参数提取,我们在事件语义和结构预训练期间,将这些列表合并为表示多词实体的单个节点(如CNN’s Kelly Wallace)。公式化来说:

3.2 Event Semantic Pre-training
为了在大型无监督语料库中对不同的事件语义进行建模,并学习上下文化的事件语义表示,我们采用PLM作为文本编码器,并对其进行训练,目的是区分各种触发参数对。
3.2.1 Text Encoder
a multi-layer Transformer as the text encoder,use the last layer’s hidden vectors as token representations
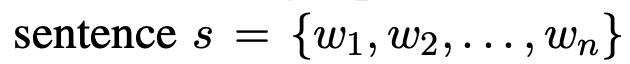
对于一个 ,可能一个node有多个词表示(we use different marker pairs for different nodes)
,可能一个node有多个词表示(we use different marker pairs for different nodes)

由于我们的事件语义预训练侧重于建模事件语义,我们从训练有素的通用PLM开始预训练,以获得通用语言理解能力。CLEVE对模型架构是不可知的,可以使用任何通用PLM,如BERT(Devlin et al.,2019)和RoBERTa(Liu et al.,2017)。
3.2.2 Trigger-Argument Pair Discrimination
我们设计了触发自变量对判别作为事件语义预训练的对比预训练任务。基本思想是在相同的事件中学习比不相关的单词更接近的单词表示。我们注意到,在AMR结构中由ARG、时间和位置边缘连接的单词与事件中的触发器参数对非常相似,即唤起事件的关键词和参与事件的实体例如,在图1中,“Netanya”是“攻击”事件的论据,而断开连接的“CNN的Kelly Wallace”则不是。
