202303mysql面试题梳理
202303mysql面试题梳理
1. 索引篇
- MySQL 支持哪些存储引擎,这些存储引擎之间的区别是什么
存储引擎就是存储数据,建立索引,更新查询数据等技术的实现方式。存储引擎是基于表的,不是基于数据库的,所以存储引擎也可以看作表类型。主要支持并且比较常用的存储引擎是InnoDB和MyISAM,比较一下两者:
MyISAM不支持事务(transaction),也不支持外键:
- 事务的作用主要就是保证一系列的语句封装到一块,共同成功还是共同失败,一般就是start transaction,然后最后commit;
- 外键的作用主要就是保持数据一致性 完整性,比如example1里面包含student_id、course_id、grade,example2里面包含id、student_id、course_id这几个,example2里面的stu_id和course_id就可以称为example2表的外键,1表是父表,2表是子表,这两个表形成关联,必须子表数据删除后,才能删除父表。然后还可以约束数据完整性,比如:事件触发器类型:RESTRIC(限制在子表有关联的情况下,父表不能更新);CASCAD(父表在更新或者删除的时候,同时更新或者删除子表中对应的记录);SET NULL(父表在更新删除的时候,子表中对应字段设置为NULL)
锁上,InnoDB使用行级锁,MyISAM使用表级锁:
- 行级锁就是说,对数据库表中的每一行数据进行锁定,从而实现对该行数据的独占访问:当一个用户正在使用某一行数据的时候,其他用户只能等待该用户完成操作,才能对该行数据进行操作,能更好支持并发操作
- 表级锁就是对整张表进行锁定,从而对整张表进行独占访问,这个系统资源消耗更小,但是就无法支持并发操作了
- 行级锁比表级锁更适合高并发的场景,但是也相应的增加了开销
一些老版本mysql的InnoDB存储引擎不支持全文索引,这个全文索引我的理解就是类似倒排索引那种
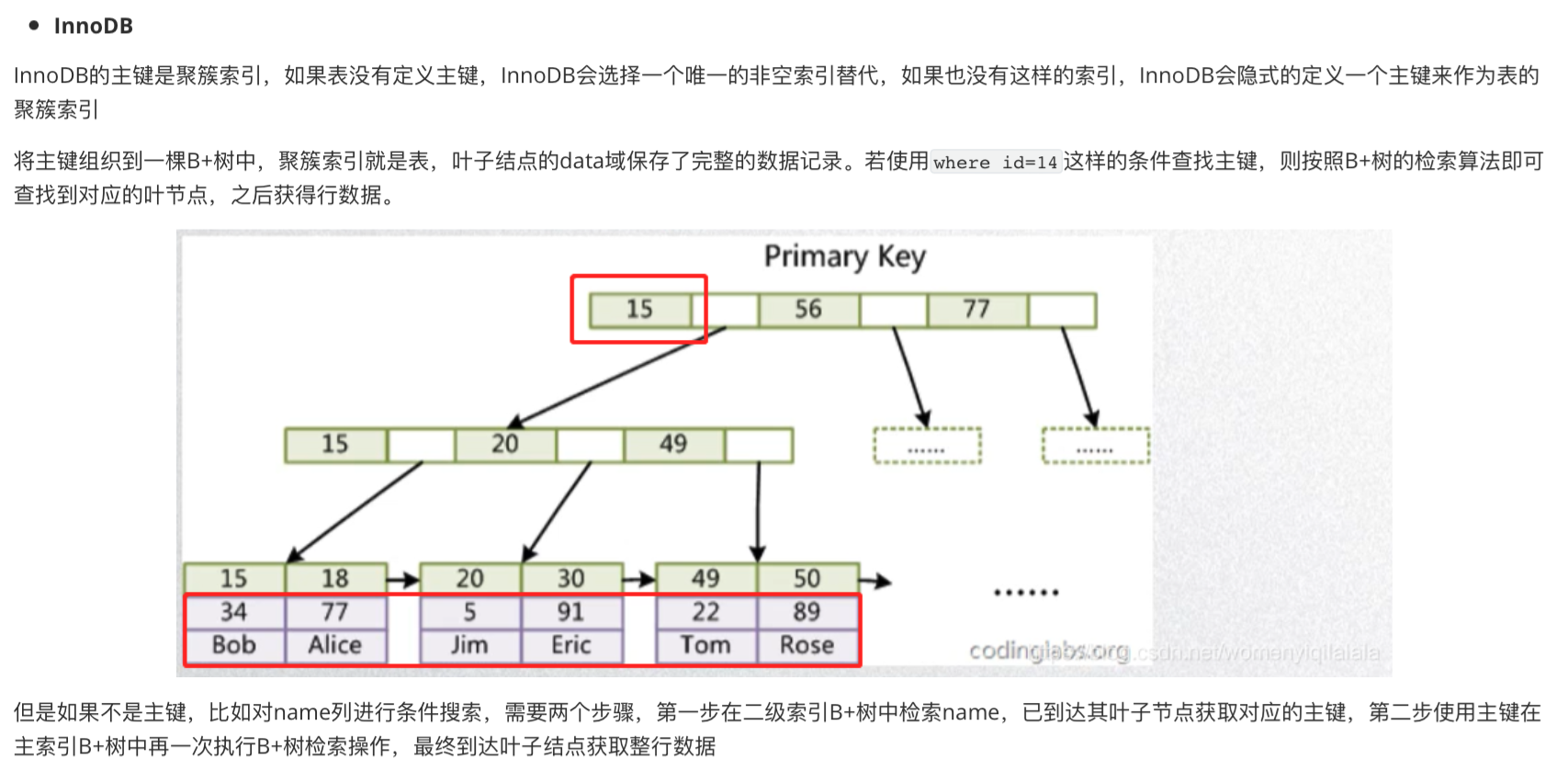
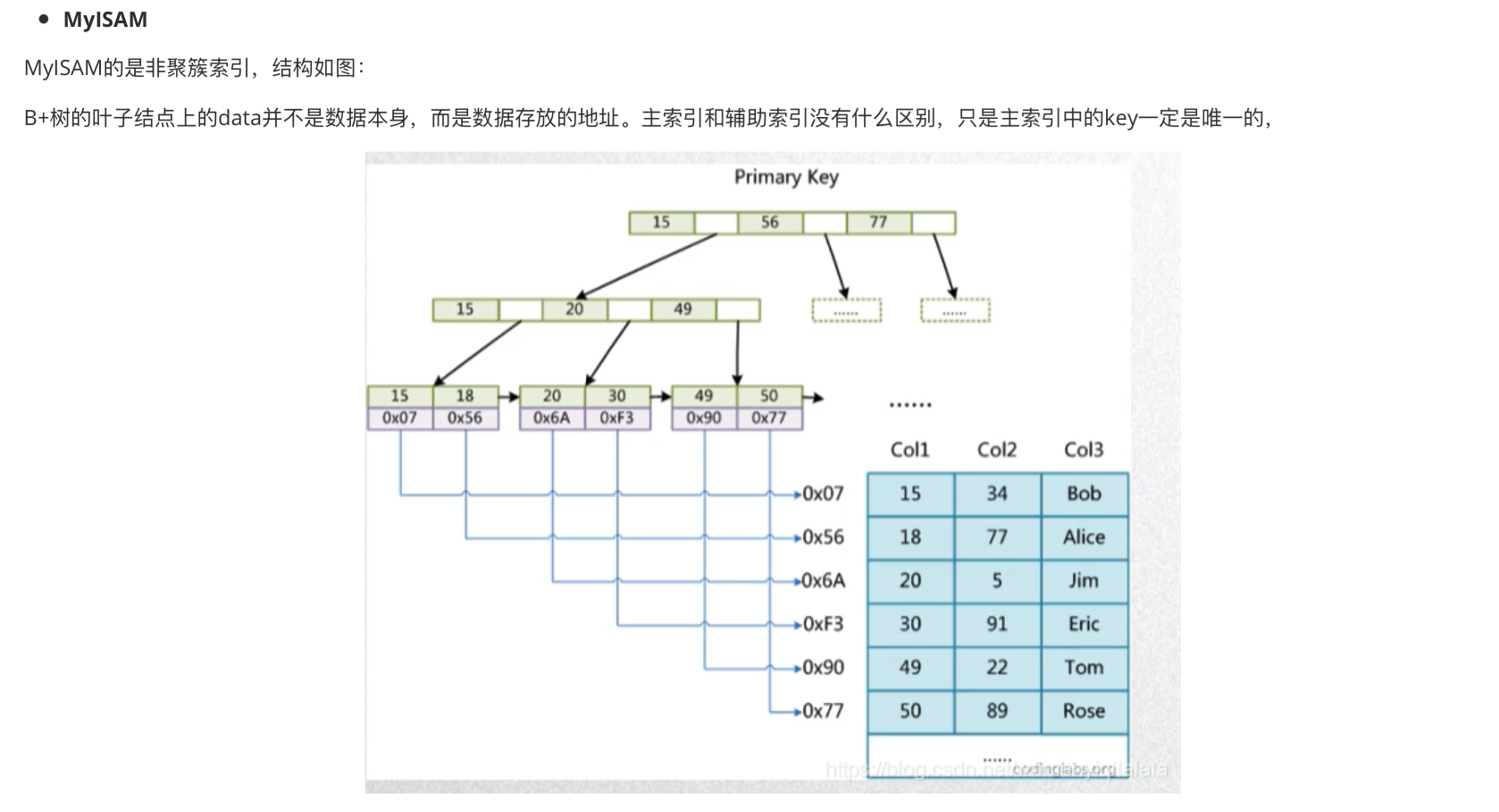
- 聚簇索引,非聚簇索引是什么
mysql中innodb存储引擎数据结构是B+树,聚簇索引叶子结点的值就是Mysql的数据行,普通索引叶子节点的值存的就是主键值
B+树是存储结构,聚簇索引和非聚簇索引则是存储的方式
- 很简单一句话:找到了索引就找到了需要的数据,这个索引就是聚簇索引
- 非聚簇索引:索引的存储和数据是分离的,找到了索引,要根据索引上的值再次回表查询
只有主键是聚簇索引
- 非聚簇索引不一定会回表查询
不一定,这涉及到查询语句所要求的字段是否全部命中了索引,如果全部命中了索引,那么就不必再进行回表查询。
举个简单的例子,假设我们在员工表的年龄上建立了索引,那么当进行select age from employee where age < 20的查询时,在索引的叶子节点上,已经包含了age信息,不会再次进行回表查询。
- 建立联合索引(a,b,c),where c=5是否会用到索引,为什么?索引有哪些失效场景?
用不到,联合索引有最左匹配原则,(a) (a,b) (a,b,c)
索引失效的场景:模 型 数 空 运 最 快
模糊查询:like查询’%’以通配符开头这样的,索引失效
型:对于varchar类型的字段,查询的时候用number,
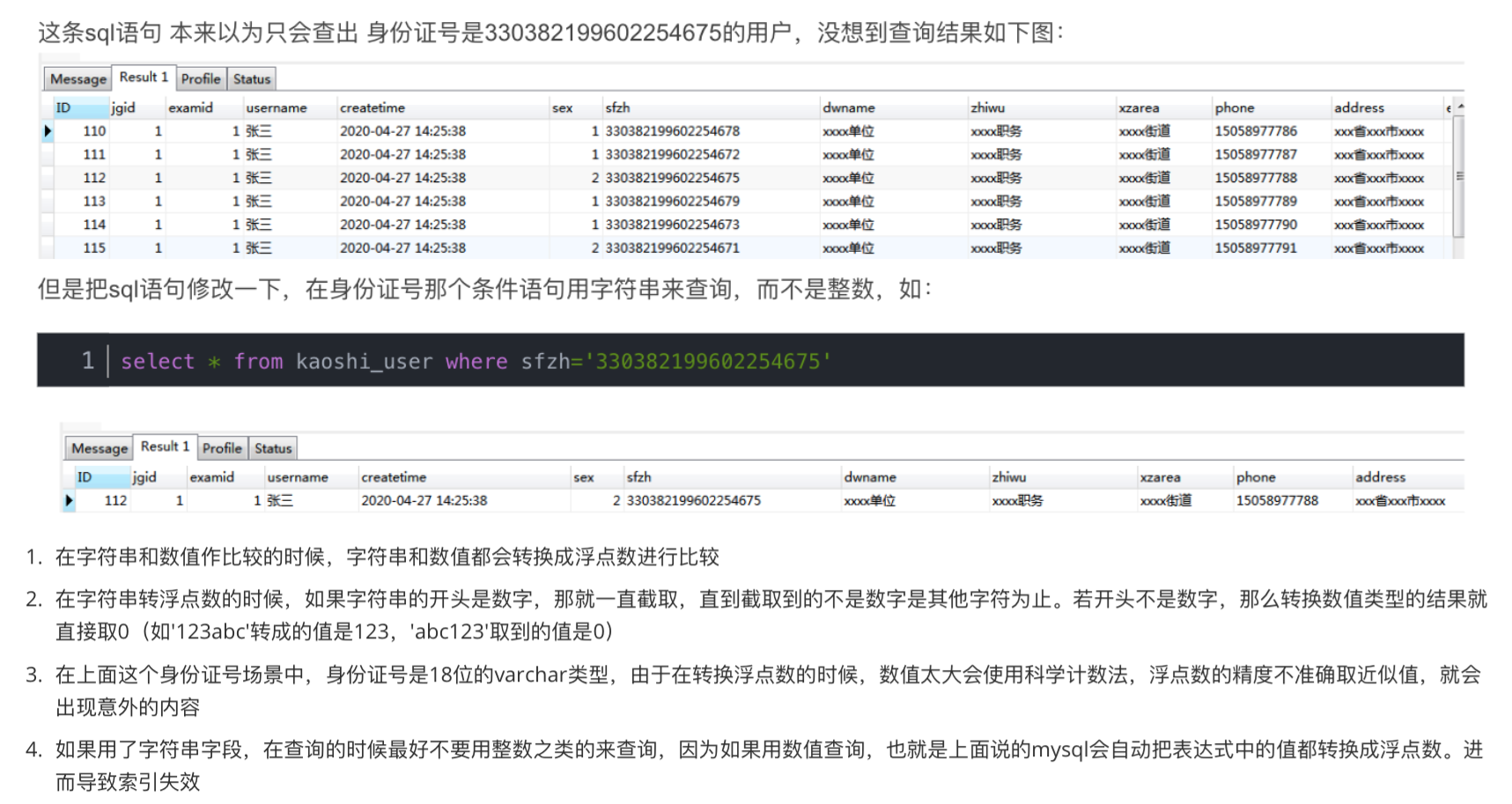
数:函数的意思,比如DATE这些的,或者就是建立函数的索引
空:null,要限制索引的列是not null
运:运算 + - * /这样的
最:最左匹配
- 对于性别字段是否需要建立索引?
性别字段重复性很强,只能建立非聚簇索引 -> 查到索引值和聚簇索引值 -> 需要回表查询,由于回表查询的存在,反而比较慢,维护索引也有额外的开销
这个地方是非绝对的,如果比如三类[1,2,3]非均衡分布,1% 2% 97%,经常查看那1% 2%的数据,建立索引来回表就比较值得了
索引的区分度问题,可以计算字段的区分度,来不把全部的这个长度建立索引
mysql中非聚簇索
2. 事务篇
- 什么是数据库的事务?
数据库的事务是指一组数据库操作语句,它们被视为一个不可分割的工作单元,要么全部执行成功,要么全部执行失败。
- 数据库的四个特性是什么,举个例子
原子性A、一致性C、隔离性I、持续性D
原子性:一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间的某个环节,如果执行失败,会被回滚到事务开始前的状态,就像事务从来没被执行过一样
一致性:事务数据操作前后满足完整性约束,A B开始各有1000块钱,A转给B200块钱,这时候A800 B1200,加起来还是一样的
隔离性:数据库允许多个并发事务同时数据进行读写和修改,隔离性则是有几个隔离等级
持续性:一旦事务处理结束后,数据修改永久的,即使系统故障也不会丢失
- 事务的并行执行,会带来的问题?以及Mysql默认的隔离级别是什么?
三大问题:脏读、不可重复读、幻读,严重性也是脏读>不可重复读>幻读
1)脏读:一个事务「读到」了另一个「未提交事务修改过的数据」,就脏读了
假设AB两个事务同时处理,A事务先读到余额然后再执行更新,但是A事务还没有提交,这个时候B来读读到了A这个未提交状态的,这个时候A回滚了,B读到的数据就是过期的或者说未被提交的数据,也就是脏读
2)不可重复读:在一个事务内多次读同一个数据,前后两次读到数据不一样的情况,就是发生了「不可重复读」
在A事务的期间,B事务修改了一个值并提交,这个时候A事务前后两次读了同一个
3)幻读(主要是针对记录数量) :在一个事务内多次查询符合一个条件的记录数量,前后两次记录数量不一样,就意味着产生了幻读,A操作着操作着,B改了并提交了
以上问题引出事务的隔离级别:
- 串行化:会对记录加上读写锁,在多个事务对这条记录惊醒操作的时候,如果冲突了,后访问的事务必须等前一个事务完成了再操作
- 可重复读:一个事务执行过程中看到的数据,一直跟这个事务启动的时候看到的数据是一致的
- 读已提交:一个事务提交之后,变更才能被其他事务看到
- 读未提交:一个事务还没被提交的时候,他做的变更就能被其他事务看到