MySQL查漏补缺-1
MySQL查漏补缺-1
1. 牛客网面经1
Reference:https://www.nowcoder.com/discuss/424298860043907072
1.1 MySQL所支持的多种存储引擎(主要是MyISAM和InnoDB)
比较常见支持的存储引擎包含:MyISAM(不支持事务和外键)、InnoDB(唯一支持事务,唯一支持外键)、MEMORY(内存型)、MERGE、ARCHIVE等
1.1.1 引入
存储引擎就是存储数据,建立索引,更新查询数据等等技术的实现方式。存储引擎是基于表的,而不是基于库的。所以存储引擎也可被称为表类型。MySQL支持的存储引擎包含:MyISAM、InnoDB、MEMORY、MERGE、ARCHIVE等
如果创建表时不指定,系统就会使用默认的存储引擎InnoDB,可以根据业务的需求选择不同的存储引擎
可以使用show engines;来查看有哪些存储引擎可供使用
在创建表的时候可以使用ENGINE关键字来指定新建表的存储引擎
1 | |
常见搜索引擎对比如下:
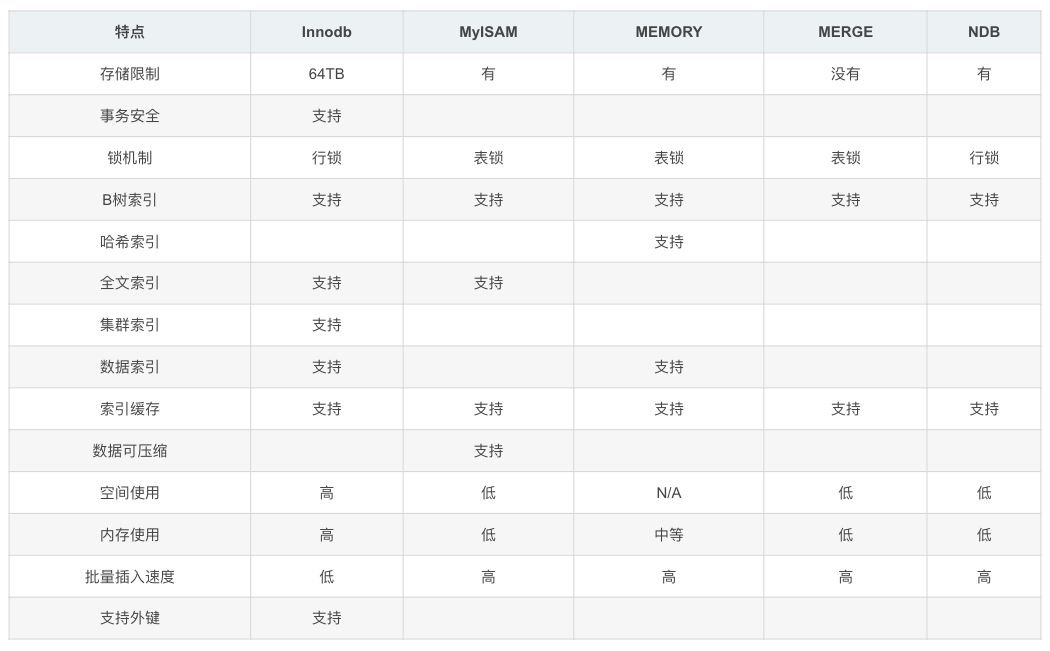
1.1.2 MyISAM
相比较InnoDB而言,不支持事务、也不支持外键
- 事务
其中事务是这样的一个流程,类似把多个封装到一块的样子
1 | |
MySQL中InnoDB事务默认是自动提交,如果用户想要设置事务的自动提交方式,可以通过更改AUTOCOMMIT的值来实现。
AUTOCOMMIT的值设置为1表示开启事务自动提交,设置为0表示关闭事务自动提交,如果想要查看当前会话的AUTOCOMMIT值,可以使用如下语句:
1 | |
关闭可以使用如下语句:
1 | |
- 外键
作用:保持数据一致性,完整性,多个表是不让改还是一起改,由事件触发器决定
事件触发器类型:RESTRIC(限制在子表有关联的情况下,父表不能更新);CASCAD(父表在更新或者删除的时候,同时更新或者删除子表中对应的记录);SET NULL(父表在更新删除的时候,子表中对应字段设置为NULL)
就比如创建了两个表:
example1里面包含stu_id学号、course_id课程号、grade分数
example2里面包含id、stu_id学号、course_id课程号,然后建立外键
这里把example2中的stu_id和course_id称为example2表的外键,example1是父表,example2是子表,两个表形成关联,必须子表的数据删除后,才能删除附表中的对应数据(必须先删除外键存在的表,外键在其他表中是主键)
1 | |
事件触发限制,在外键上带上事件触发限制,这里CASCADE就是跟随外键改动的意思:
1 | |
如果对父表的数据进行修改(UPDATE、DELETE),那么子表的数据会同步
1.1.3 InnoDB
是一个健壮的事务型存储引擎:事务控制、自动灾难恢复、外键约束
相对来说写的效率会更差一些,并且会占用更多的磁盘空间保留数据和索引
1.2 MyISAM vs InnoDB 索引相关
MyISAM不支持事务,而InnoDB支持。InnoDB的AUTOCOMMIT默认是打开的,即每条SQL语句会默认被封装成一个事务,自动提交,这样会影响速度,最好是把多条SQL语句放在begin和commit之间组成事务提交。
InnoDB数据支持行锁定,MyISAM只支持表锁定。即是说MyISAM同一个表上的读锁和写锁是互斥的,MyISAM并发读写时如果等待队列中既有读请求又有写请求,默认写请求的优先级高,即使读请求先到。所以MyISAM不适合于有大量查询和修改并存的情况,那样查询进程会长时间阻塞。因为MyISAM是锁表,所以某项读操作比较耗时会使其他写进程饿死。 一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限。这也是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;
InnoDB支持外键,MyISAM不支持
一些版本的InnoDB不支持全文索引(类似那种ES的倒排索引),不过这个感觉用处比较小?
没有where的COUNT语句,MyISAM要比InnoDB快,因为MyISAM内置了计数器。
InnoDB下 主键是聚簇索引
MyISAM下 主键不是聚簇索引
1.2.1 聚簇索引、非聚簇索引
https://zhuanlan.zhihu.com/p/142139541
https://blog.csdn.net/admin_yjh/article/details/105501680
MySQL的InnoDB索引数据结构是B+树:
主键索引叶子结点的值,存储的就是MySQL的数据行
普通索引叶子结点的值,存储的是主键值
这是了解聚簇索引和非聚簇索引的前提
- 什么是聚簇索引?
很简单一句话:找到了索引就找到了需要的数据,那么这个索引就是聚簇索引,所以主键就是聚簇索引,修改聚簇索引其实就是修改主键
- 什么是非聚簇索引?
索引的存储和数据时分离的,也就是说找到了索引但没找到数据,需要根据索引上的值再次回表查询。非聚簇索引也叫辅助索引
- 一个例子
1 | |
第一种,直接根据主键查询获取所有字段数据,此时主键是聚簇索引,因为主键对应的索引叶子结点存储了id=1的所有字段的值
1 | |
第二种,根据编号查询编号和名称, 编号本身是一个唯一索引,但查询的列包含了学生编号和学生名称,当命中编号索引时,该索引的节点的数据存储的是主键ID,需要根据主键ID重新查询一次,素以这种情况下no不是聚簇索引
1 | |
第三种,我们根据编号查询编号(有时候需要校验是否存在),命中编号索引直接返回编号,需要的数据就是该索引,不需要回表查询,这种场景下no是聚簇索引(或者也可以称为覆盖索引,应该是不会叫成聚簇索引的)
1 | |
1.2.2 聚簇索引与主键的选择
https://blog.csdn.net/womenyiqilalala/article/details/103835639
B+树是存储结构,而聚簇索引、非聚簇索引则是说明存储的方式
B+树作为一种存储结构,在InnoDB和MyISAM中都可以用的上
- InnoDB
InnoDB的主键是聚簇索引,如果表没有定义主键,InnoDB会选择一个唯一的非空索引替代,如果也没有这样的索引,InnoDB会隐式的定义一个主键来作为表的聚簇索引
将主键组织到一棵B+树中,聚簇索引就是表,叶子结点的data域保存了完整的数据记录。若使用where id=14这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。

但是如果不是主键,比如对name列进行条件搜索,需要两个步骤,第一步在二级索引B+树中检索name,已到达其叶子节点获取对应的主键,第二步使用主键在主索引B+树中再一次执行B+树检索操作,最终到达叶子结点获取整行数据
- MyISAM
MyISAM的是非聚簇索引,结构如图:
B+树的叶子结点上的data并不是数据本身,而是数据存放的地址。主索引和辅助索引没有什么区别,只是主索引中的key一定是唯一的,

1.3 索引相关
1.3.1 建立联合索引(a,b,c),使用条件where c=5查询是否会用到索引?
https://blog.csdn.net/m0_37683670/article/details/85860111
联合索引中存在最左匹配原则
如果有一个2列的索引(a,b),则已经对(a), (a,b)上建立了索引
如果有一个3列的索引(a,b,c),则已经对(a), (a,b), (a,b,c)上建立了索引
如果只查询b,应该就会索引失效了,转向全表扫描吧
1.3.2 索引失效
模 型 数 空 运 最 快
模:模糊查询的意思,like的模糊查询以%开头,索引失效,因为不知道前面有多少个字符
1 | |
型:代表数据类型,如字段类型varchar,where条件用number,索引也会失效
1 | |
这里其实也能查到,那么为什么能查到呢?
https://blog.csdn.net/Koikoi12/article/details/121165440

在字符串和数值作比较的时候,字符串和数值都会转换成浮点数进行比较
在字符串转浮点数的时候,如果字符串的开头是数字,那就一直截取,直到截取到的不是数字是其他字符为止。若开头不是数字,那么转换数值类型的结果就直接取0(如’123abc’转成的值是123,’abc123’取到的值是0)
在上面这个身份证号场景中,身份证号是18位的varchar类型,由于在转换浮点数的时候,数值太大会使用科学计数法,浮点数的精度不准确取近似值,就会出现意外的内容
如果用了字符串字段,在查询的时候最好不要用整数之类的来查询,因为如果用数值查询,也就是上面说的mysql会自动把表达式中的值都转换成浮点数。进而导致索引失效
数:是函数的意思,对索引的字段使用内部函数,索引也会失效。这种情况下应该建立基于函数的索引,比如下面这样会失效,create_time设置索引,就无法使用函数:
1 | |
空:是null的意思。索引不存储空值,如果不限制索引列是not null,数据库会认为索引列有可能存在空值,所以不会按照索引进行计算
运:是运算的意思,对索引列进行+ - * /等运算的时候,会导致索引失效,比如
1 | |
最:最左原则,在复合索引中索引列的顺序至关重要,如果不是按照索引的最左列开始查找,则无法使用索引
快:全表扫描更快的意思,如果数据库预计使用全表扫描比索引快,则不适用索引
1.3.3 性别字段是否需要建立索引
性别这种重复性很强的字段,不需要建立索引
性别字段因为可重复,所以只能建立非聚簇索引,然而因为非聚簇索引叶子结点存储的事索引值和聚簇索引值,需要回表查询
所以在性别这种辨别度较低的字段上建立索引,索引树可能只有两个节点(各存了一半的这个key),跟线性查找没有太大的区别,并且因为回表的存在,导致聚簇索引书和非聚簇索引树来回切换,查询比较慢,而且维护索引还需要额外的开销
但也不是绝对的规则,如果其中一种的分布很少(不均衡分布),而且查询的非常频繁,可以对该字段进行索引
比如有一个枚举字段[1,2,3], 在上百万行数据中,1占1%, 2占%2, 3占%97,然后业务经常需要查询1和2的数据,那么就可以在该字段进行索引。访问索引的开销比较值得了
1.4 区分度
什么是区分度:有时候需要为字段创建索引的时候,如果字段太长了,为整个字段创建索引的话,太浪费存储空间了,所以需要计算出字段区分度,选择合适的索引长度
计算字段文本区分度的公式
1 | |
1 | |
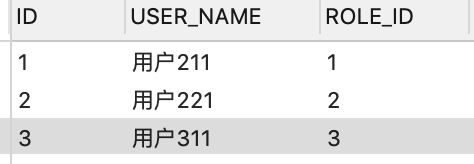
以这个测试数据为例,