五、Redis缓存设计
五、Redis缓存设计
https://zhuanlan.zhihu.com/p/346651831
https://xiaolincoding.com/redis/base/redis_interview.html#redis-%E7%BC%93%E5%AD%98%E8%AE%BE%E8%AE%A1
1. 什么是缓存雪崩、缓存击穿、缓存穿透?
Redis作为目前最广泛的缓存,在使用的时候还存在着一些问题,这里主要说一下所面临的缓存雪崩、缓存击穿、缓存穿透问题
1.1 缓存雪崩
1.1.1 什么是缓存雪崩?
当某一个时刻出现大规模缓存失效的情况,那么就会导致大量的请求直接打在数据库上面,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导致数据库宕机。这时候如果运维马上又重启数据库,马上又会有新的流量把数据库打死。这就是缓存雪崩
理解一下缓存的作用,缓存在用户请求到mysql层之前的那块,一般针对接口来做缓存
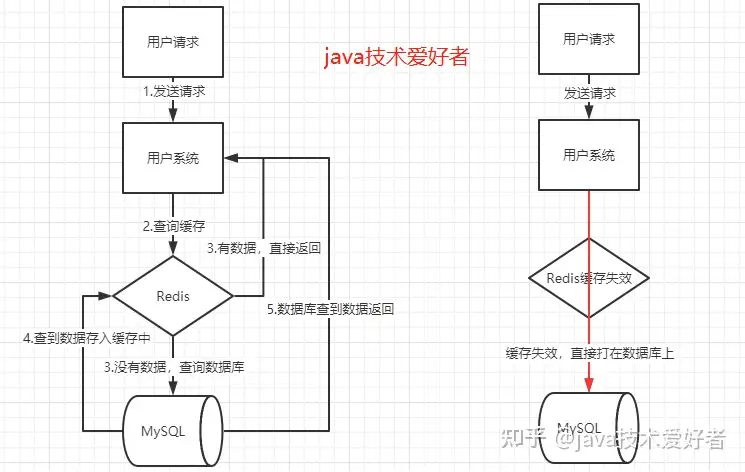
1.1.2 分析
造成缓存雪崩的关键在于同一时间大规模的key失效。为什么会出现这个问题呢?有几种可能:
- Redis宕机
- 采用了相同的过期时间
1.1.3 解决方案
- 在原有的失效时间上加一个随机值,比如1-5分钟随机,这样就避免了因为采用相同的过期时间导致的缓存雪崩
- 使用熔断机制。当流浪到达一定的阈值时,就直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上。至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果
- 提高数据库的容灾能力,可以使用分库分表,读写分离的策略
- 防止redis宕机,搭建redis集群,提高redis容灾性
1.2 缓存击穿
1.2.1 什么是缓存击穿?
其实跟缓存雪崩有点类似,缓存雪崩时大规模的key失效。而缓存击穿是一个热点的key,有大并发集中对其进行访问,突然间这个key失效了,导致大并发全部打在数据库上,导致数据库压力剧增,这种现象就叫做缓存击穿
1.2.2 分析
关键在于某个热点的key失效了,导致大并发集中打在数据库上。
- 是否可以考虑热点key不设置过期时间
- 是否可以考虑降低打在数据库上的请求量
1.2.3 解决方案
- 业务允许的话,对于热点的key可以设置永不过期的key
- 使用互斥锁,缓存失效的情况,只有拿到锁可以查询数据库,降低了同一时刻打在数据库上的请求,防止数据库打死。当然系统性能会变差
1.3 缓存穿透
1.3.1 什么是缓存穿透?
我们使用redis大部分情况都是通过key查询对应的值,假如发送的请求传进来的key是不存在redis中的,那么就查不到缓存,查不到缓存就会去数据库查询。
假如有大量这样的请求,这些请求就像“穿透”了缓存一样直接打在数据库上,这种现象就叫做缓存穿透。
1.3.2 分析
关键在于redis查不到key值,这和缓存击穿有根本的区别,区别在于缓存穿透的请求是key在redis中是不存在的(而不是失效了)
假如有黑客传进大量的不存在的key,那么大量的请求打在数据库上是很致命的问题
所以日常开发中要对参数做好校验,一些非法的参数,不可能存在的key就直接返回错误的提示,要对调用方保持这种“不信任”的心态
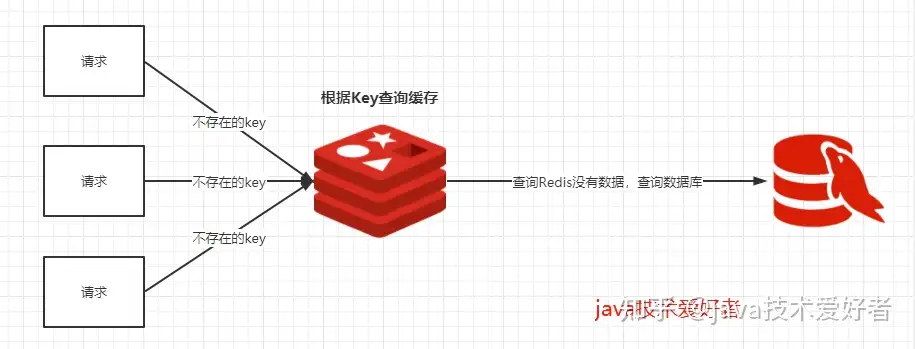
1.3.3 解决方案
- 把无效的key存进redis中,如果redis查不到数据,数据库也查不到,我们把这个key值保存进redis,设置value=“null”,当下次再通过这个key查询的时候就不需要再查询数据库。但是这个方式肯定是有问题的,可能会一直随机key
- 使用布隆过滤器。布隆过滤器的作用是某个key不存在就一定不存在,说某个key存在那么很大可能是存在(有一定的误判率)。于是可以在缓存前面加一层布隆过滤器,在我们查询的时候先去布隆过滤器查询key是否存在,如果不存在就直接返回
1.3.4 知识补充——布隆过滤器
布隆过滤器可以用于检索一个元素是否在一个集合中
hash冲突,所以说某个key在的时候,可能是hash冲突了,有一定误判率
1.4 xiaolincoding中的缓存穿透解释
当发生缓存雪崩或者击穿的时候,数据库中还是保存了应用要访问的数据,一旦缓存回复相应的数据,就可以减轻数据库的压力
而缓存穿透则是,用户访问的数据既不在缓存中、也不在数据库中,导致请求在访问缓存的时候,发现缓存缺失,再去访问数据库数据库也没有要访问的数据,没办法构建缓存数据,来服务后续的请求。那么当有大量请求到来的时候,数据库压力骤增
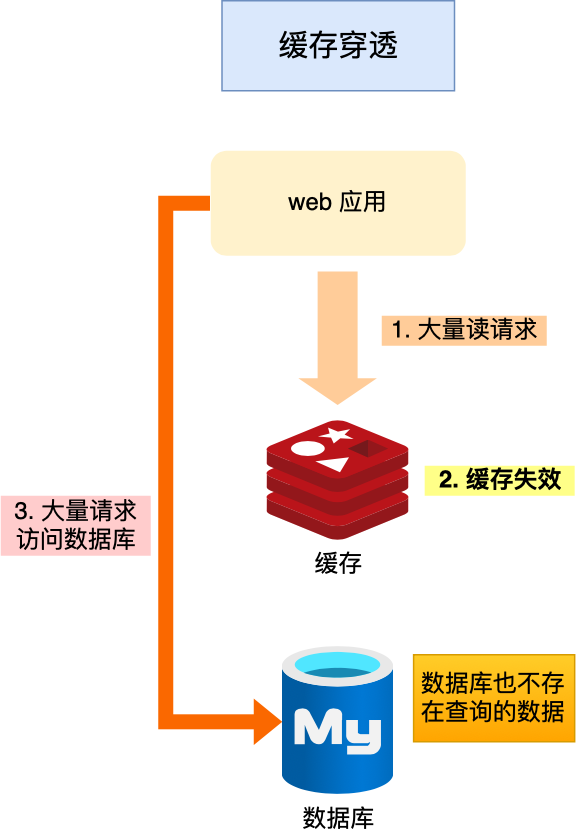
缓存穿透的发生一般有这两种情况:
- 业务误操作,缓存中的数据和数据库中的数据都被误删除了,所以导致缓存和数据库中都没有数据
- 黑客恶意攻击,故意访问大量不存在数据的业务
应对缓存穿透的方案,常见的方案有三种:
- 非法请求的限制:在API入口处判断请求参数是否合理、请求字段是否都存在了等等
- 设置空值或者默认值:当线上业务发现缓存穿透的时候,可以针对查询的数据,在缓存中设置一个空值或者默认值,就不会继续去查数据库了
- 使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断是否存在:在写入数据库的时候,使用bloom filter做标记,请求到来确认缓存失效的时候,通过查询bloom filter来判断数据是否存在,不存在就不用通过查询数据库判断了(redis本身是可以支持布隆过滤器的)
2. 如何设计一个缓存策略,可以动态缓存热点数据呢?
由于数据存储受限,系统并不是要将所有数据都需要存放到缓存中的,而只是将其中一部分热点的数据缓存起来,所以要设计一个热点动态数据的缓存策略
热点数据动态缓存的策略总体思路:通过数据最新访问时间来做排名,并过滤掉不常访问的数据,只留下经常访问的数据
以电商平台场景中做例子,现在要求只缓存用户经常访问的top1000的商品,具体细节如下:
- 先通过缓存系统做一个排序队列(比如存放1000个商品),系统会根据商品的访问时间,更新队列信息,越是最近访问的商品排名越靠前
- 同时系统会定期过滤掉排名最后的200个商品,然后再从数据库中随机读取出200个商品加入队列中
- 这样当请求每次到达的时候,会先从队列中获取商品ID,如果命中,就根据ID再从另一个缓存数据结构中读取实际场景的商品信息,并返回
zadd和zrange,zset的操作,比较适合做排名
3. 说说常见的缓存更新策略?
常见的缓存更新策略共有3种:
- Cache Aside(旁路缓存)策略;
- Read/Write Through(读穿/写穿)策略;
- Write Back(写回)策略;
3.1 Cache Aside(旁路缓存)策略
这是最常用的缓存策略,应用程序直接和「数据库、缓存」交互,并负责对缓存的维护,详细可分为写策略和读策略

写策略的步骤:
- 先更新数据库中的数据,再删除缓存中的数据
读策略的步骤:
- 如果读取命中了缓存,则直接返回数据
- 如果读取没有命中缓存,则从数据库中读取数据,然后将数据写入到缓存,并且返回给用户
Cache Aside策略适合读多写少的场景,不适合写多的场景,因为当写入比较频繁的时候,缓存中的数据会被频繁的清理,这样会对缓存的命中率有一些影响。
3.2 Read/Write Through(读穿/写穿)策略
Read Through/Write Through 策略的特点是由缓存节点而非应用程序来和数据库打交道
Redis没有直接提供这种功能
3.3 Write Back(写回)策略
Write Back(写回)策略在更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。对于数据库的更新,会通过批量异步更新的方式进行。
异步更新数据库?