二、MySQL索引
二、MySQL索引
reference:
https://blog.csdn.net/qq_57314342/article/details/123058002
https://xiaolincoding.com/mysql/index/index_interview.html
- 什么是索引?
在关系型数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需内容
索引:好比书的目录,用于加快查找的效率
索引的作用:加快查找效率,减慢插入和删除、修改效率
- 索引的要解决的问题
如果数据库中没有索引,此时查找的时候相当于要把整个表遍历一遍,如果想找id为8的学生信息,没有索引,此时的查找过程就相当于一个“顺序表查找”。
内存访问速度多快,并且数据也没那么多,其实速度还可以。
但是如果针对数据库顺序查找,数据库的数据实在磁盘上,磁盘访问速度更慢,并且数据量非常多,速度可能就会很慢,索引就是为了避免数据库进行顺序查找,提高查找效率
0. 自己的一些补充,和同学讨论后
- 假设有3个字段,在实际项目的使用上,可以给3个字段每个字段单独加一个索引,在此基础上再把3个组合起来加一个索引,虽然加索引和增删改的速度会慢,但是提高了查询的效率
- 在比如「公司名称」这种字段上加索引,虽然不像id那样12345678的,但是也有字典序可能可以用
- 索引近似把O(n)的效率变成了O(logn)的
- 实际业务场景,可以用redis+mysql的方式,把redis作为缓存层,然后查询的时候,先去看看redis里面有没有,如果没有的话再去mysql里面找,找到后再加入redis,这样对于热点数据的保存可能会比较好
- 这里引出了redis的缓存雪崩、缓存击穿、缓存穿透问题
- 索引对like这种查询(但如果是 like ‘%xxx%’ 这种就没啥用了)就可能没有什么用处了,不是有序的那种感觉,而like这种场景是一个模糊匹配场景,可以引入es
1. 为什么MySQL采用B+树作为索引?
这个是面试经常被问到的问题。要解释这个问题,不单单要从数据结构角度出发,还要考虑磁盘I/O次数,因为mysql的数据时存储在磁盘中的
1.1 怎样的索引的数据结构是好的?
mysql的数据是持久化的,意味着数据(索引+记录)是保存到磁盘上的,因为这样即使设备断电了,数据也不会丢失。磁盘是一个慢的离谱的存储设备,相较于内存 CPU而言非常非常慢。
由于数据库的索引是保存到磁盘上的,因此当我们通过索引查找某行数据的时候,就需要先从磁盘读取索引到内存,再通过索引从磁盘中找到某行数据,然后读入到内存,也就是会发生多次磁盘I/O,磁盘I/O次数越多,消耗时间就越大——希望尽可能少的磁盘I/O操作完成查询工作
另外,mysql是支持范围查找的,所以索引的数据结构不仅能高效的查询一个数据,也要能高效的执行范围查找
设计mysql索引的数据结构,至少要满足
- 能在尽可能少的磁盘I/O操作中完成查询工作
- 要能高效的查询某一个记录,也能高效的执行范围查找
1.2 什么是二分查找
索引数据最好能按顺序排列,这样就能用「二分查找法」高效定位数据
二分查找每次都能把查询的范围减半,这样复杂度就降到了O(logn),但是每次查找都要不断计算中间的位置
1.3 什么是二分查找树
用数组实现现行排序的数据结构虽然好用,但是插入新元素的时候性能太低——插入一个元素,需要将这个元素之后的元素都后移一位,如果这个操作发生在磁盘中将是灾难性的。因为磁盘速度比内存慢很多,不能将一种共线性结构用在磁盘
其次,有序的数组在使用二分查找的时候,每次查找都要不断计算中间的位置
需要设计一个非线性,天然适合二分查找的数据结构
二叉查找树
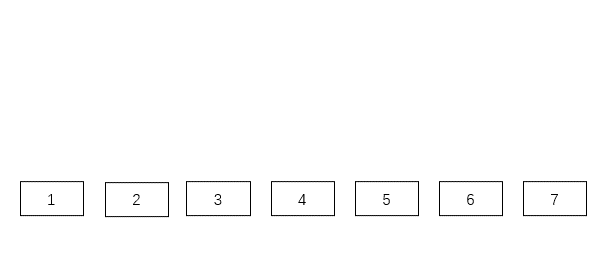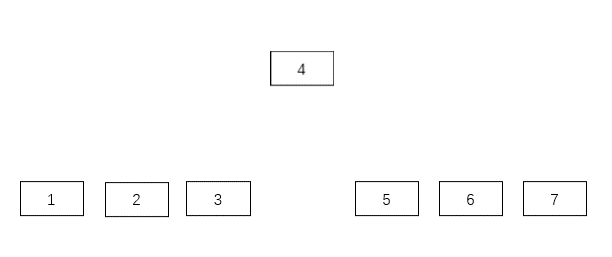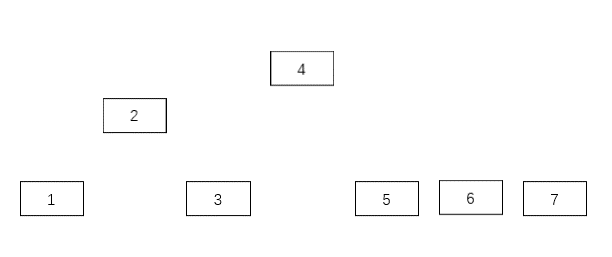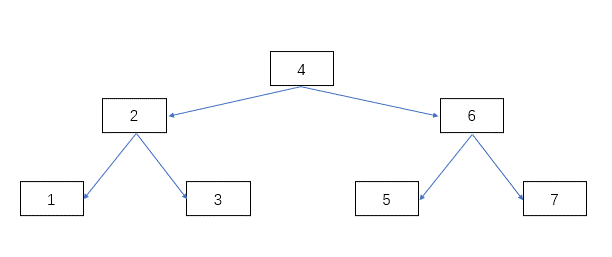
二叉查找树的特点是,一个节点的左子树所有节点都小于这个节点,右子树都大于这个节点
- 不需要计算中间节点位置了
- 插入的时候,不用开销很大了
然而,二叉查找树还存在着问题
- 当每次插入的元素都是二叉查找树的最大元素,二叉查找树就会退化成链表,这样的查找数据时间复杂度又变成O(n)的了
由于树是存储在磁盘中的,访问每个节点,都对应一次磁盘I/O操作,树的高度就等于每次查询数据的时候磁盘IO操作次数
1.4 什么是自平衡二叉树
针对二叉查找树会在极端情况下退化成链表的问题,提出平衡二叉查找树(AVL树)
在二叉查找树的基础上,约束:每个节点的左子树的右子树的高度差不能超过1
红黑树也是自平衡二叉树,加入了左旋右旋操作,也是为了自平衡
不管平衡二叉树还是红黑树,都会随着元素增多,导致树的高度变高,意味着IO次数增多,影响整体查询效率
一个结论:当树的节点越多的时候,并且树的分叉数M越大的时候,M叉树的高度会远小于二叉树的高度
红黑树是一种自平衡二叉查找树
1.5 什么是B树
自平衡二叉树虽然能保持查询操作的时间复杂度在O(logn),但是因为本质上是一个二叉树,每个节点只能有两个子节点,节点个数越多的时候,树的高度就会变高,就会增加磁盘的IO次数,影响查询效率
解决树的高度问题,提出来了B树,不再限制一个节点只能有2个子节点,而是可以有M个子节点,降低树的高度
假设M=3,3阶的B树,每个节点最多有M-1=2个数据,和最多有M=3个子节点,超过要求就会分裂
同样的场景下,平衡二叉树的高度就会高很多,但是B树的高度要低一些
B树的不足之处:
每个节点是存放数据的
查询位于底层的某个节点的过程中,非这个节点的记录数据会从磁盘加载到内存,这些记录是没用的,我们只想读取这些节点的索引数据来做比较查询,而其他的路径数据是对我们没用的
另外用B树来做范围查询的时候,中序遍历,涉及多个节点的磁盘IO问题
1.6 什么是B+树
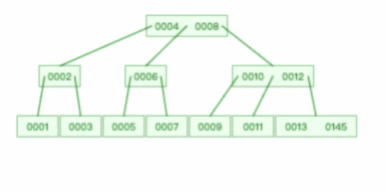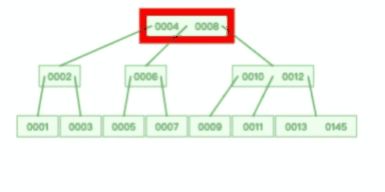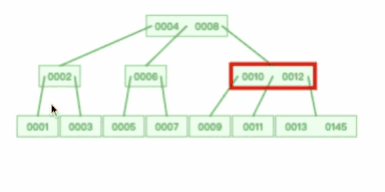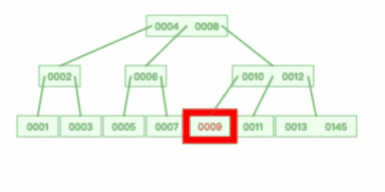
B+树就是对B树做了一个升级,mysql中索引的数据结构就用的是B+树,结构如下图
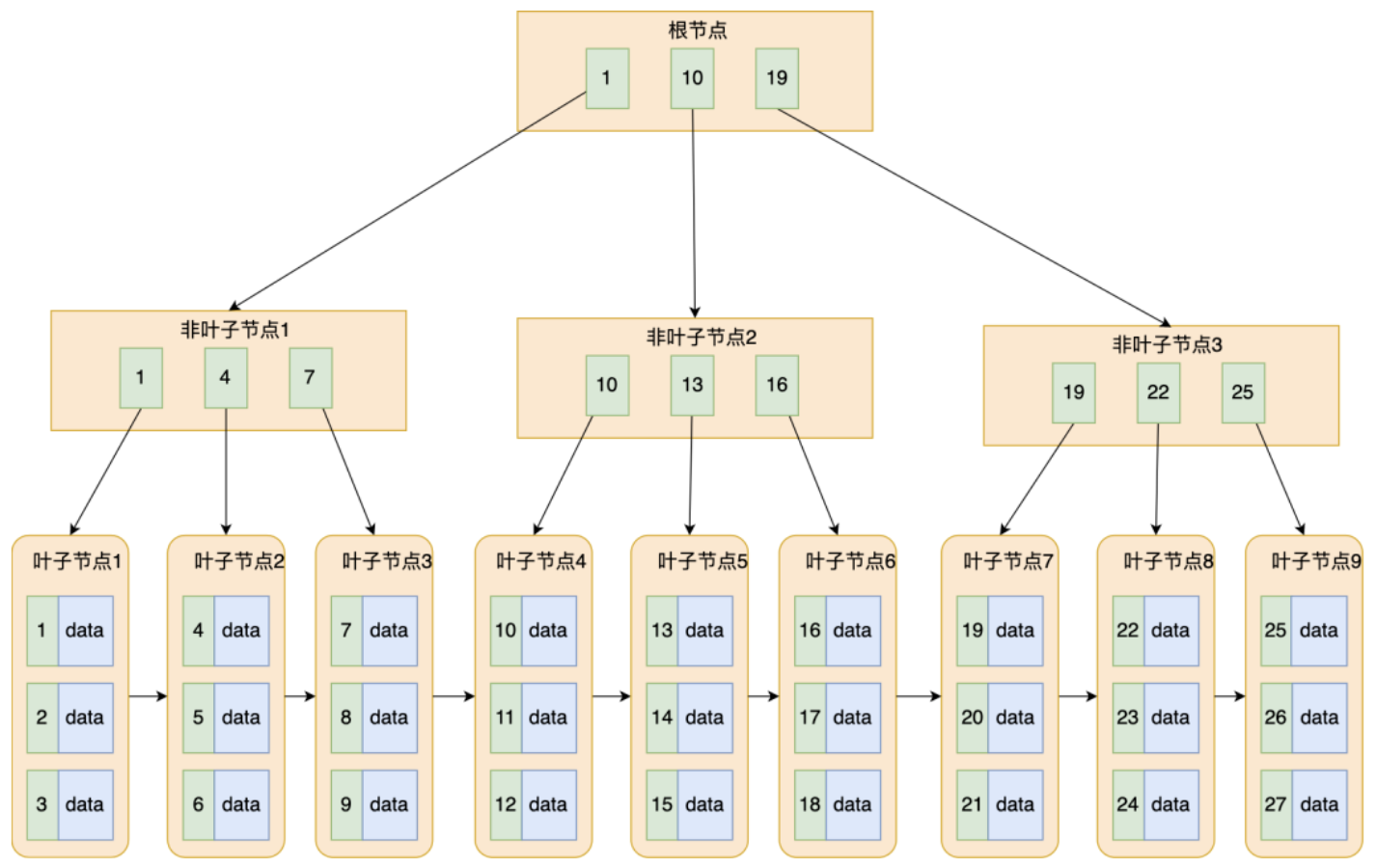
B+树和B树差异的点,主要是:
- 叶子节点才存放数据(索引+记录),非叶子结点只存放索引
- 所有索引都会在叶子节点出现,叶子结点之间构成一个有序链表
- 非叶子结点的索引也会在叶子中,并且在子节点中是所有索引的最大(或最小)
1.6.1 B树 vs B+树,单点查询性能比较
B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B 树更「矮胖」,查询底层节点的磁盘 I/O次数会更少
1.6.2 B树 vs B+树,插入和删除效率
B+树的插入删除效率更高
1.6.3 B树 vs B+树,范围查询
B+树所有叶子节点之间还有一个链表进行连接,这种设计对范围查询非常有帮助
比如说我们想知道 12 月 1 日和 12 月 12 日之间的订单,这个时候可以先查找到 12 月 1 日所在的叶子节点,然后利用链表向右遍历,直到找到 12 月12 日的节点,这样就不需要从根节点查询了,进一步节省查询需要的时间。
1.7 MySQL中的B+树
MySQL 的存储方式根据存储引擎的不同而不同,我们最常用的就是 Innodb 存储引擎,它就是采用了 B+ 树作为了索引的数据结构。
1.8 为什么不用hash
解决不了范围查找的问题,而且这样应该空间开销很大?