emnlp2022-PU-for-DocRE
emnlp2022-PU-for-DocRE
0. Abstract
- para1
文档级别的关系抽取目标是识别多个句子中实体之间的关系。以前的大多数方法都集中在完全监督下的文档级RE。然而,在现实世界场景中,完全标记文档中的所有关系是代价昂贵并且困难的,因为文档级RE中的实体对的数量与实体的数量呈二次方增长。
为了解决常见的不完全标记问题,我们提出了一个统一的正无标记学习框架——shift and squared ranking loss positive-unlabeled(SSR-PU) learning。我们首次在文档级RE上使用正无标记(PU)学习。
考虑到数据集的标记数据可能导致未标记数据的先验转移,我们引入了训练数据先验转一下的PU学习。此外,使用无类别分数作为自适应阈值,我们提出了平方排序损失,并使用多标签排序度量证明了其贝叶斯一致性。
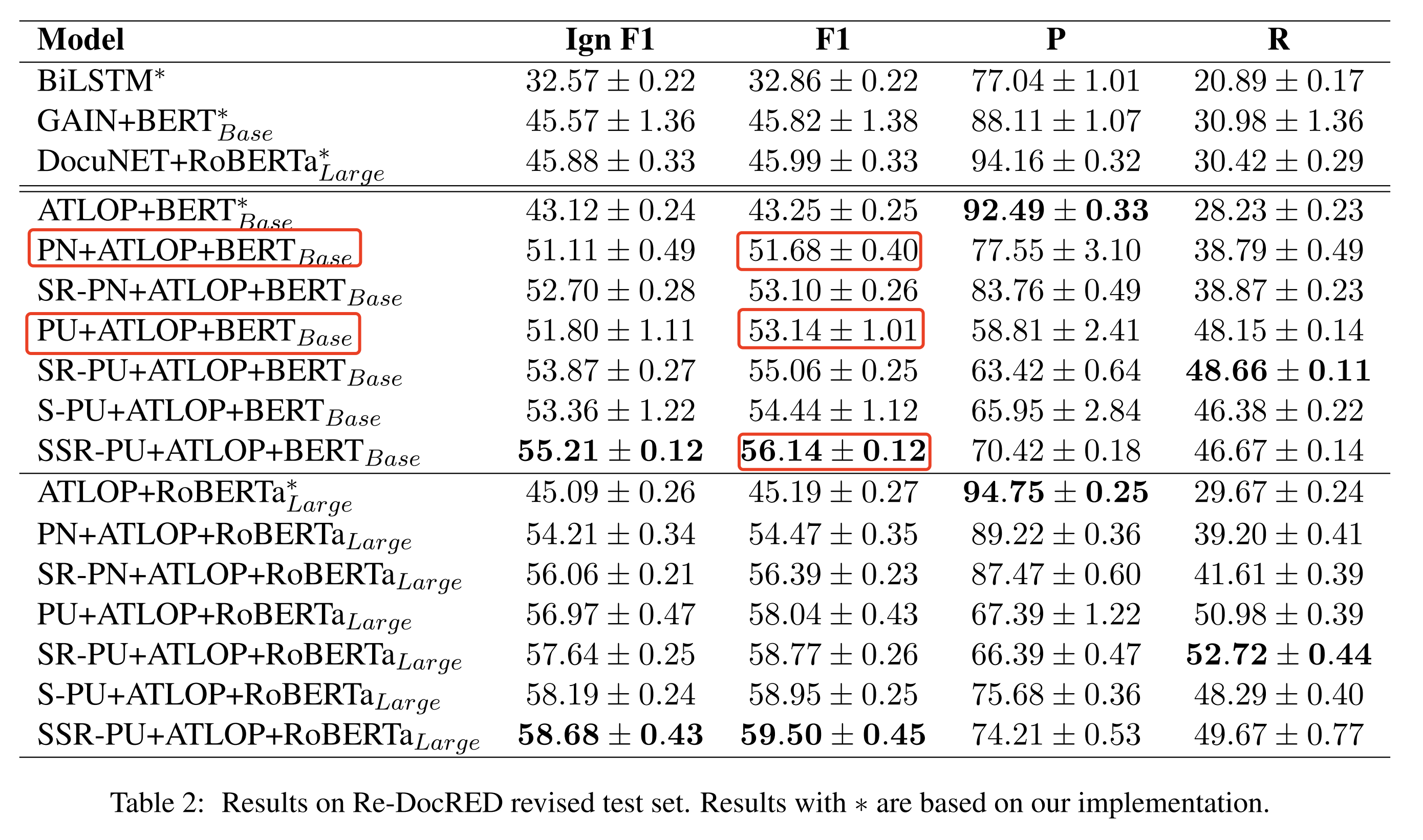
大量实验表明,我们的方法在不完全标记的情况下,相对于先前的baseline,实现了约14个F1点的改进。此外,他在完全监督和极未标记的情况下,也超过了以前最先进的结果
https://github.com/www-Ye/SSR-PU
1. Introduction
- para1
关系提取(RE)旨在识别给定文本中两个实体之间的关系。它在知识图构建、问题回答和生物医学文本理解方面有着丰富的应用。以前的大部分工作是在一句话中提取实体之间的关系。最近,旨在识别多个句子中表达的各种实体对之间的关系的文档级RE受到了越来越多的关注。
- para2
以前的文档级RE方法主要处理完全监督场景。然而,在现实世界场景中,不完全标记是文档级RE中的一个常见问题,因为实体对的数量随着实体的数量呈二次方增长。DocRED是文档级RE的一个流行数据集。最近的研究发现,DocRED(使用推荐修订方案注释数据)包含大量假阴性样本,即许多阳性样本未被标记。如图1所示,文件Alecu Russo包含大量未标记的positive关系。因此,在这个数据集上训练的模型在真是场景中往往会过拟合,并且召回率较低。因此,标签不完整的文档级RE已成为紧急需求。
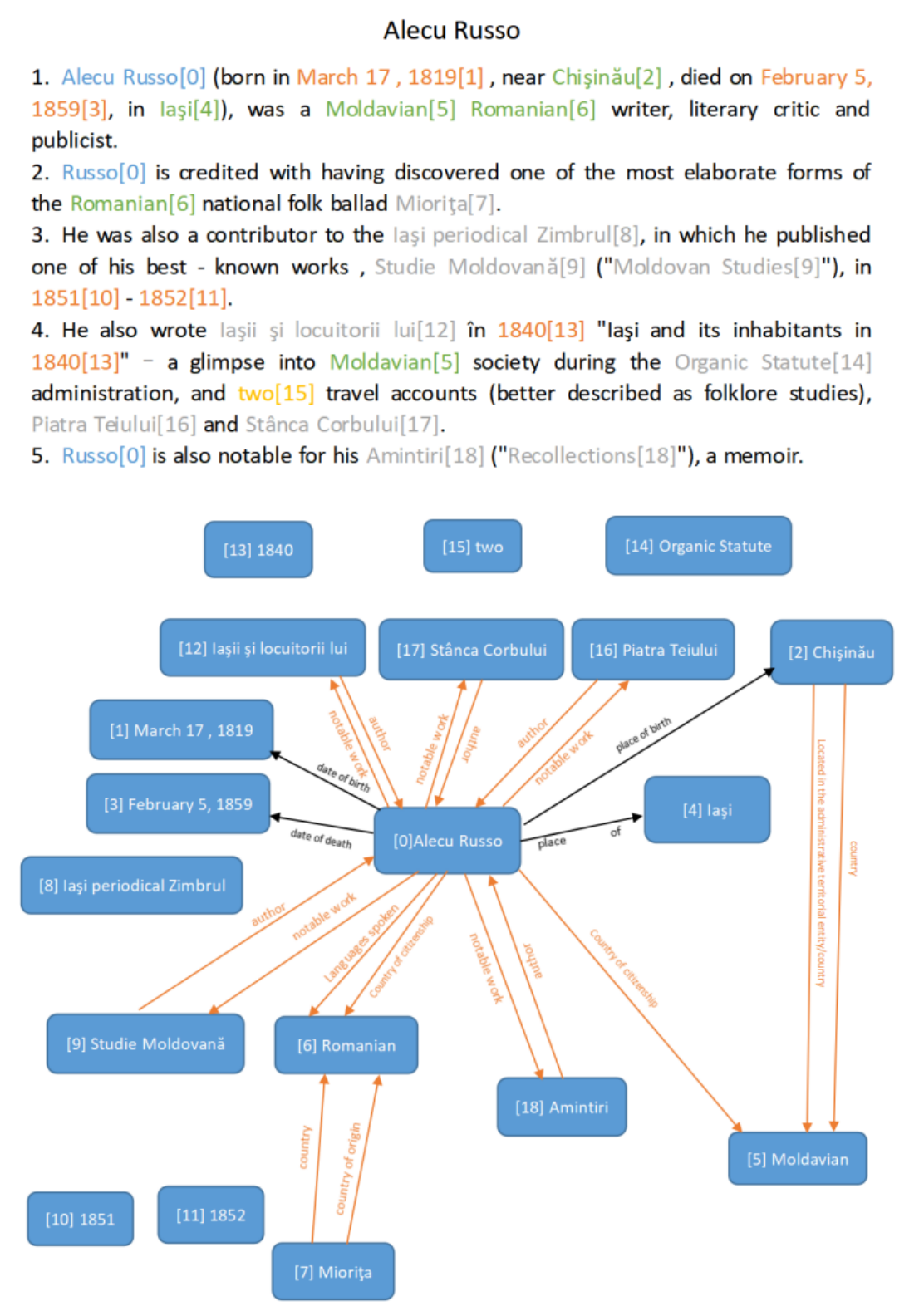
图1:DocRED的案例。实体根据其类型以不同的颜色高亮显示。黑色箭头表示用原始数据集注释的关系,橙色箭头表示重新注释的关系。
- para3
为了解决这个问题,我们提出了一个统一的正面无标记学习框架——shift and squared ranking loss positive-unlabeled (SSR-PU) learning,其可适于在不同水平下进行标记。
我们首次在文档级RE任务中使用正无标记学习(PU)。由于文档级RE是一个多标签分类任务,我们对每个类(one vs all)应用二进制PU学习方法,将其转化为多标签PU学习。此外,根据我们的观察,DocRED(由推荐修订方案注释的数据集)中相当一部分关系已经被注释。这导致未标记数据的先验分布与总体先验分布之间的偏差。为了解决这个问题,我们在训练数据的先验转移下引入了自适应PU学习,该学习基于估计的总体先验分布和标记正样本的分布来调整模型,使其与普通PN学习或普通PU学习相似。这里,正-负(PN)学习意味着将所有未标记的样本视为负样本。
- para4
此外,为了区分无类别和预定义类别,我们提出了无类别排名的平方排名损失,使得正预定义标签的排名高于无类别标签,而负预定义标签的排序更低。这是一个理想的多标签替代损失度量,我们从理论上证明了它与(Zhou和Lee,2022)提出的多标签排名度量的贝叶斯一致性。这种损失函数可以很好地适应PU学习。
- para5
我们在两个具有不完全标记的多标记文档级RE数据集DocRED和ChemDis Gene上进行了广泛的实验,这是一个新提出的多标记生物医学文档级RE数据库。实验结果表明,我们的方法SSR-PU比之前的基线(未考虑标记不完整现象)好了大约14个F1点。此外,我们进行了完全监督的实验,以及对新构建的极未标记数据的实验,其中每个文档中标记的每个关系类型的数量限制为1。在两个互补设置下的实验证明了我们方法在不同标记级别下的有效性。本文的贡献总结如下
- 我们提出了一个统一的正面无标记学习框架SSR-PU,以适应具有不同不完全标记级别的文档级RE
- 我们首次将PU学习应用于文档级RE任务,并在训练数据的先验转移下引入PU学习,该学习可以基于估计的先验和标记分布在普通PN学习和普通PU学习之间达到平衡
- 我们提出了平方排序损失,它相对于其他损失函数有效地提高了性能,并证明了其与多标签排序度量的贝叶斯一致性。
- 我们的方法在各种设置中实现了最先进的结果,并为具有不完整标签的文档级RE提供了稳健的基线。
2. Related Work
2.1 Document-level relation extraction
…
然而,以前的方法没有单独考虑未标记的数据。他们只是简单地将它们都当作阴性样本,这导致了在现实场景中的召回率降低和性能显著下降
2.2 PU learning
- Para1
正无标记(PU)学习旨在从正和无标记数据中学习分类器。PU学习是一种半监督学习,但他们之间有一个根本区别:虽然半监督学习需要标记的负数据,但PU学习只需要标记的正数据。许多当前的PU学习方法依赖于总体先验估计,而一些最近的研究注意到训练集和测试集之间存在先验转移(prior shift)。
另一方面,PU学习在许多NLP应用中都得到了应用,例如,文本分类、句子嵌入、命名实体识别、知识图补全和句子级RE(He等2020)。然而,这种方法很少应用于文档级RE任务。
2.3 Multi-label classification
- para1
多标签分类是一个广泛研究的问题,这里我们关注损失函数。二进制交叉熵(BCE)是最流行的多标签损失函数,将多标签问题减少为多个独立的二进制(one vs all)分类任务。最近,研究者发现平方损失也可以在分类任务中获得更好的结果。另一个常见的多标签损失函数是成对排名损失,它通过成对(一对一)比较将多标签学习转化为排名问题。
对于多标签PU学习,有研究者将其视为一个多标记的PU排名问题,Aota等人,2021)使用一对一策略将PU学习应用于多标签常见漏洞和暴露分类。对于文档级RE任务,(Zhou和Lee,2022)提出了一种无类别排序的多标签度量。该多标签度量尚未应用于PU学习。
3. Methodology
在本节中,我们介绍了针对具有不完全标记的文档级RE的方法 移位shift和平方排名损失squared ranking loss正未标记(SSR-PU)学习的细节。首先,我们介绍了文档级RE的正向无标记学习的定义。接下来,我们介绍了在训练数据的先验转移下的PU学习。最后,提出了使用无类别分数作为自适应阈值的平方排名损失。
3.1 Postiive-unlabeled learning for document-level RE
- para1
文档级RE可以被视为多标签分类任务,其中每个实体对是一个实例,关联关系是标签样本。以前的监督学习方法只将未标记的关系作为负样本来处理,这可能导致存在大量False Negative的情况下召回率低。为了解决这个问题,我们为每个类别采用PU学习。
- para2
使得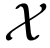 代表实例的space,并且
代表实例的space,并且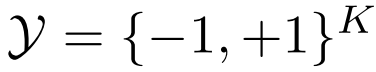 代表label的space,其中
代表label的space,其中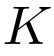 代表预定义的类别数目。一个实例
代表预定义的类别数目。一个实例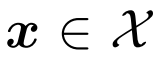 与由二进制向量标识的标签子集相关联
与由二进制向量标识的标签子集相关联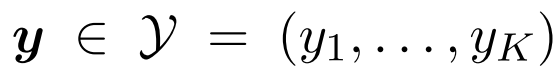 。其中
。其中 代表i-th label对于
代表i-th label对于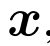 是positive的,然后
是positive的,然后 otherwise。得分函数定义为
otherwise。得分函数定义为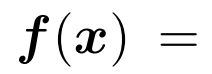
 。在后续的表示中,我们使用
。在后续的表示中,我们使用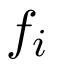 来替代,省略对x的依赖。
来替代,省略对x的依赖。
- para3
对于第i个类别,假设数据遵从一个密度的未知的概率分布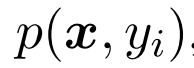 (注意这里,yi是针对每个类别的) ,
(注意这里,yi是针对每个类别的) ,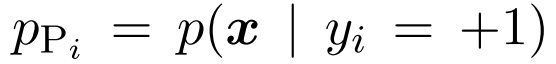 作为正边缘,
作为正边缘,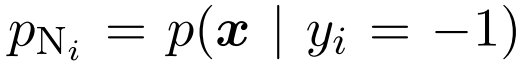 作为负边缘,
作为负边缘,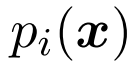 代表边缘。在positive-negative(PN) 学习中,目标是将预期的分类风险降至最低。
代表边缘。在positive-negative(PN) 学习中,目标是将预期的分类风险降至最低。
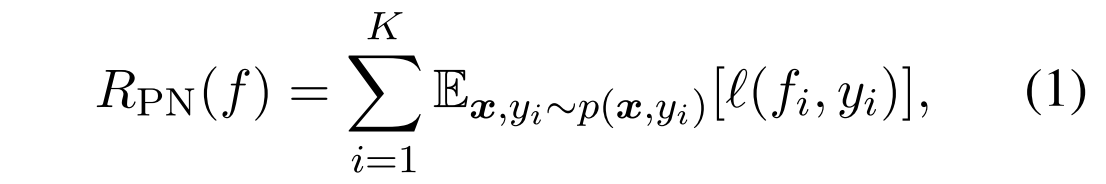
这里,等式1可以通过等价地使用正样本和负样本的误差之和来计算:
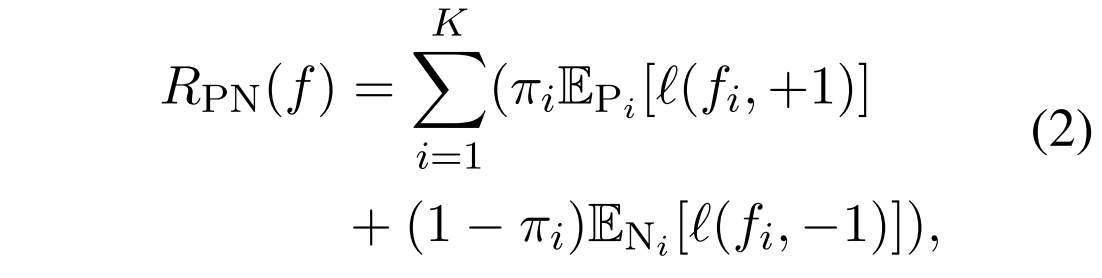
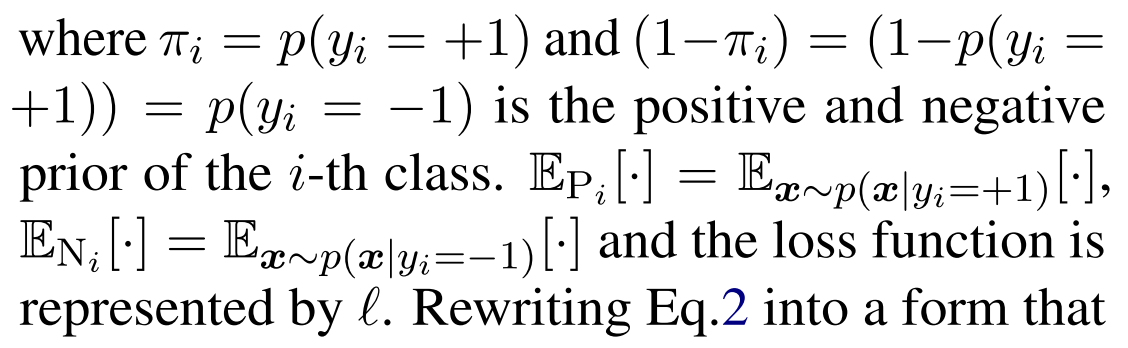
这个写法和交叉熵损失函数很像,但是确实有点看不懂 重写一下变成下面式子3的形式
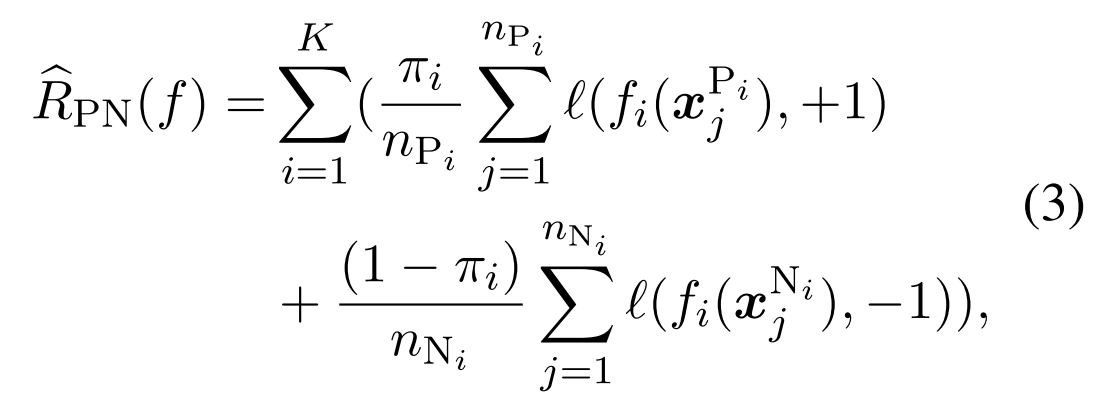
对于第i种关系,判断这种关系正例与负例的数目,看起来是不是只把这个类别的当做正例,然后把所有其他类别的都当做负例,然后nPi是正例的数量应该会少一些,nNi的数量会多一些,loss求和后再加权,用这个πi,看起来是一种先验?
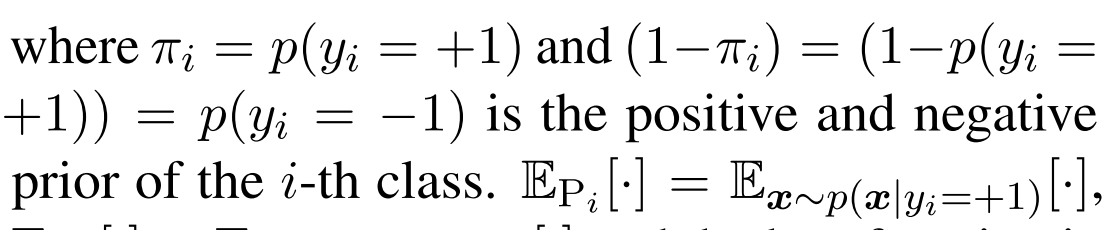
其中 代表表示类i的第j个样本为正或负的情况。
代表表示类i的第j个样本为正或负的情况。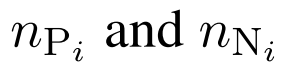 分别为i类阳性和阴性样本的数量。
分别为i类阳性和阴性样本的数量。
- para4
在正未标记(PU)学习中,由于缺乏负样本,我们无法从数据中估计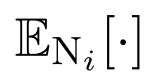
由于一些地方缺乏标记(甚至极端缺乏标记的场景),没标记的我们也不知道市政样本,还是负样本,那么就不能来判断,也就是说只标记了正样本
接下来,有研究者PU学习假设未标记的数据可以反映真实的总体分布,即pUi(x)=pi(x)。预期分类风险
公式可以定义为(这里可以省掉,直接看下面的式子5) :
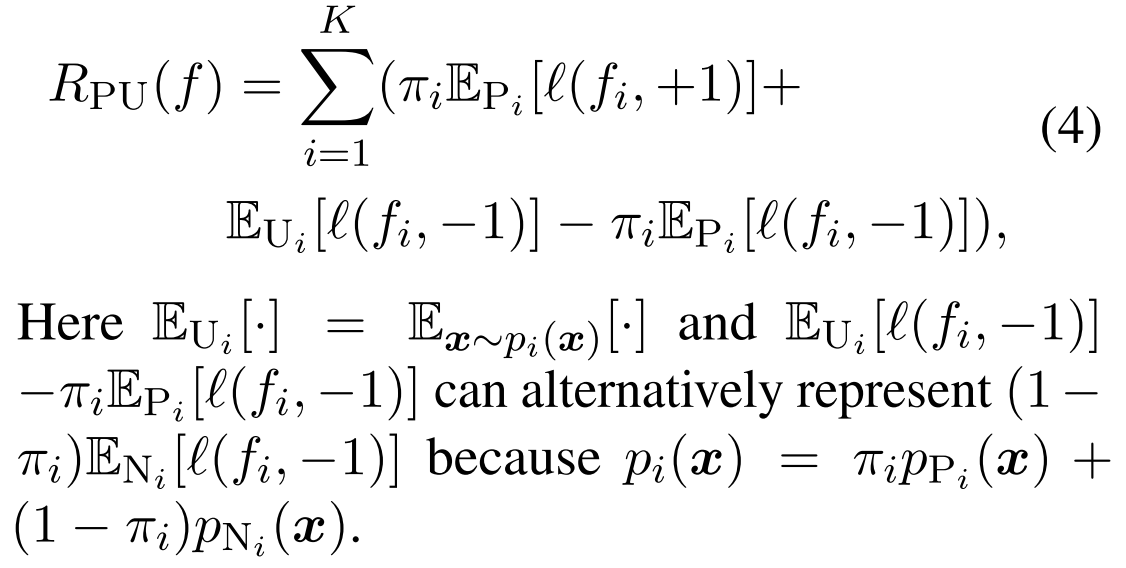
通过以可使用数据近似的形式重写方程4,我们得到以下结果:
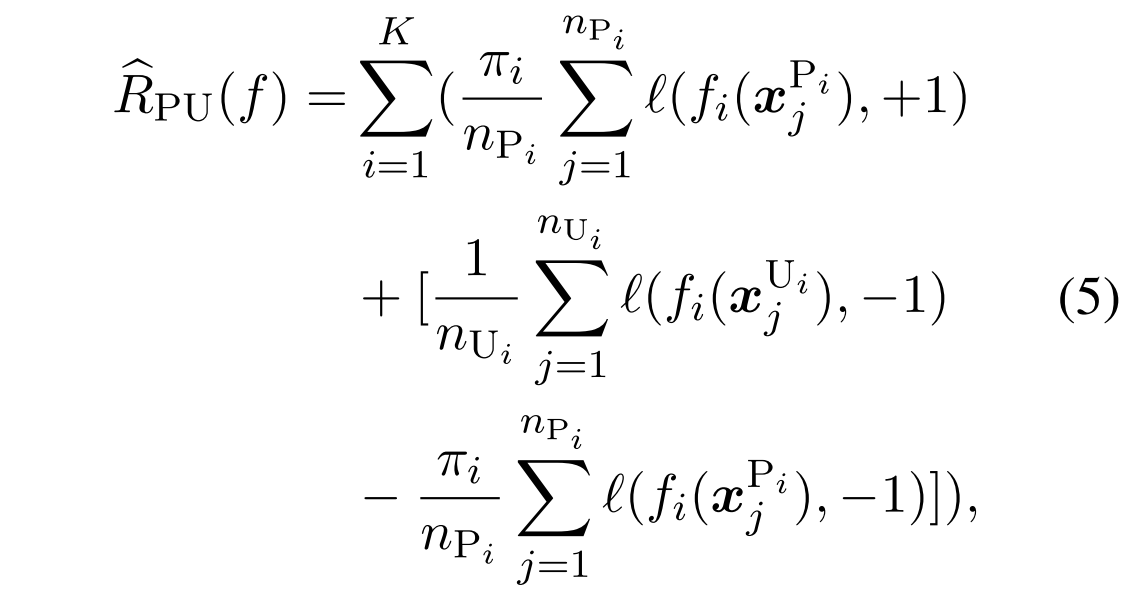
这里Ui是代表unlabel的医生,n就是个数
还是要看怎么理解下这个式子,最小化、最小化、最大化?对于一个样本,如果是positive的,最小化将其分类为正例的loss;对于一个样本,如果是无标记的,最小化将其分类为负例的loss;对于一个样本,如果是positive的,最大化其分类为负例的loss?
然而,方程5中的第二项可能是负的,并且在使用高度灵活的模型时容易过度拟合。因此,提出了一种非负风险估计器(Kiryo等人,2017)来缓解过度拟合问题:
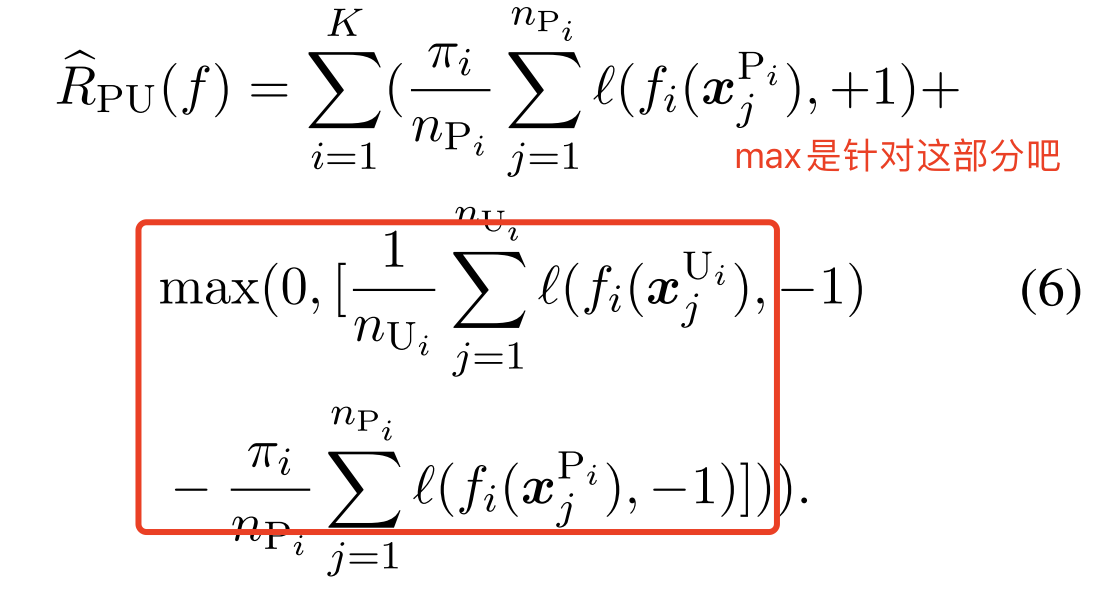
对于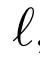 ,我们使用凸函数平方损失:
,我们使用凸函数平方损失:
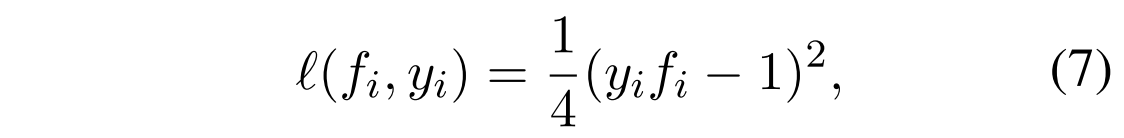
我们比较了第4.4节中使用平方损失和log-sigmoid损失函数的性能,后者是一种常用于分类的凸损失函数。
yi是1,分数也是1,loss是0;yi是1,分数是不知道怎么得到的,比如分数能-1?那么loss就是1
此外,为了解决严重的类不平衡问题,我们将正风险估计之前的γi乘以类权重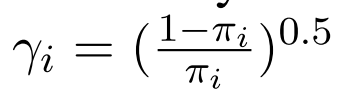
3.2 Class prior shift of training data
普通PU学习需要假设总体分布需要与未标记数据的分布相同。相反,对于由推荐修订方案构建的文档级RE数据集,可能已经注释了许多关系,特别是常见的关系。这导致训练集的未标记数据的先验转移。当这个假设被打破的时候,普通的PU学习将产生一个有偏见的结果。为了解决这个问题,受处理测试集和训练集之间的先验转移的方法的启发,我们引入了先验下的PU学习。
对于每个类别,我们假设已知的先验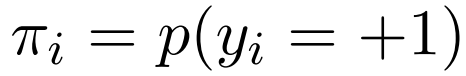 。我们设置
。我们设置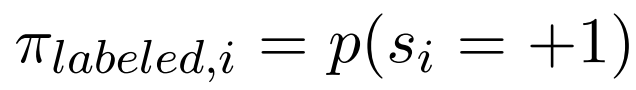 以及
以及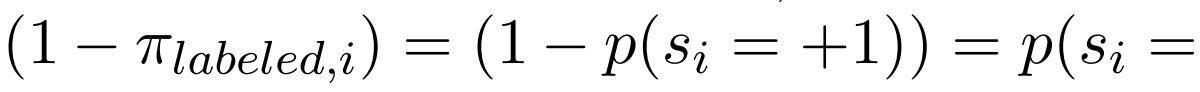
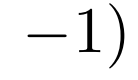 ,其中
,其中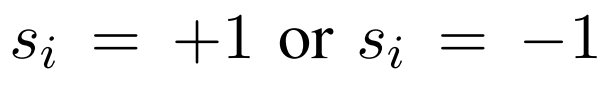 代表第i个类别是标记了还是没标记。
代表第i个类别是标记了还是没标记。
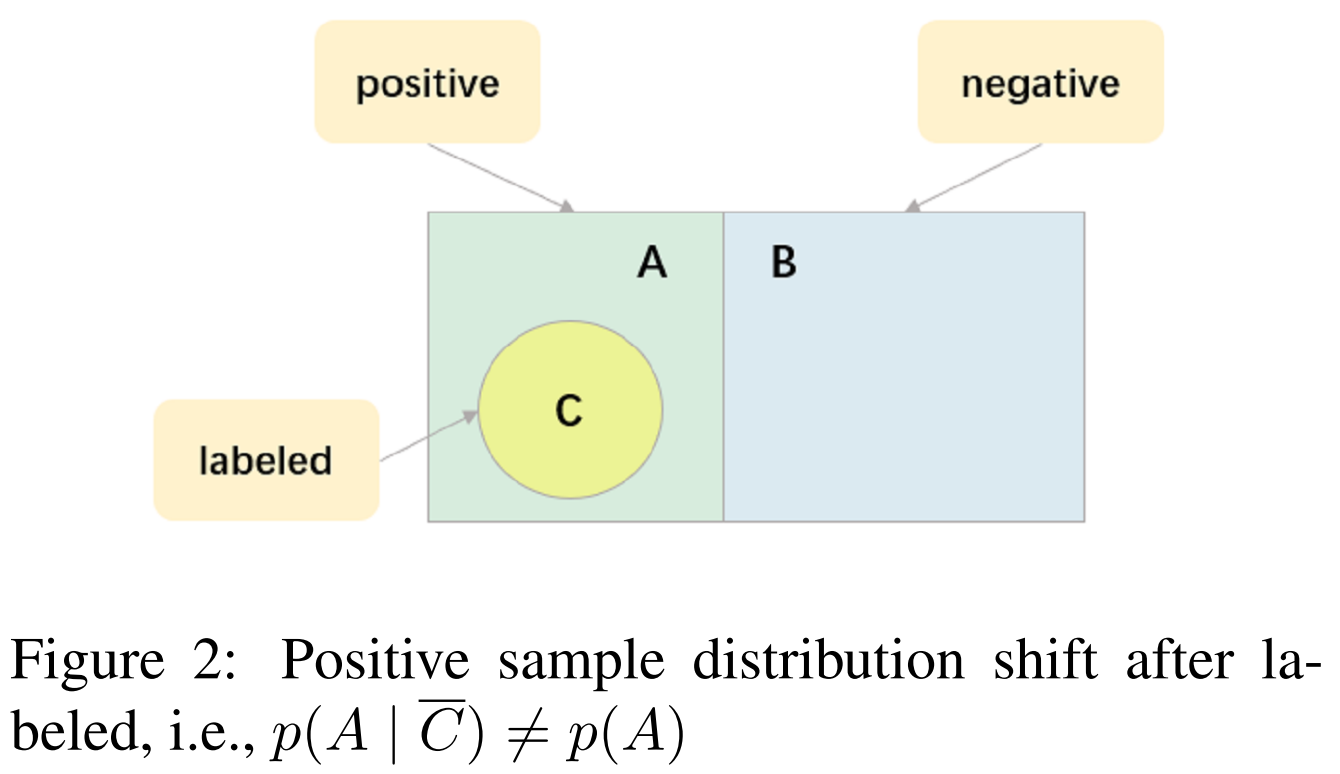
如图2所示,未标记数据下阳性样本的条件概率不同于总体阳性样本的概率。未标记数据下阳性样本的条件概率为:
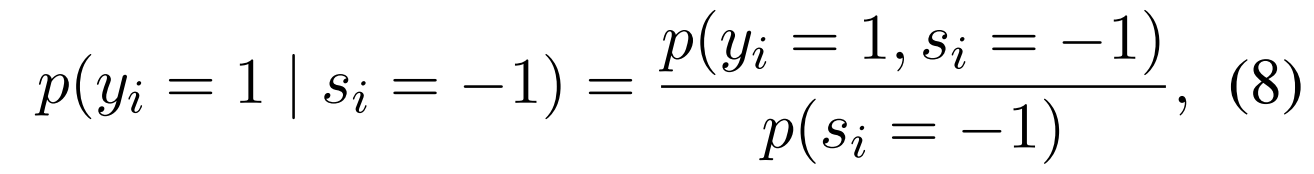
详细看一下这个公式,式子8就是上面的p(A|C—)
其中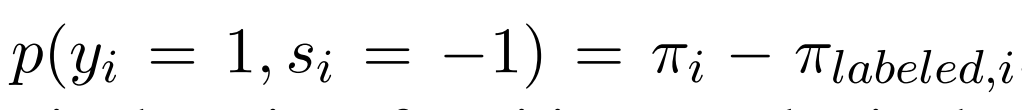 A-C,未标记的那部分但是positive
A-C,未标记的那部分但是positive
我们可以得到标记后的新的未标记数据中阳性样本的先验数为

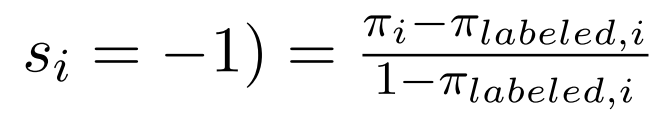
对于文档级的RE,目标是使训练数据的原始分布的以下错误分类风险最小化。

我们可以用正数和无标签数据的期望值来表示Rori(f) 的期望值来表示。
Theorem 1. 误分类风险Rori(f)可以等效地表示为这是把前面这个先验给拿出来
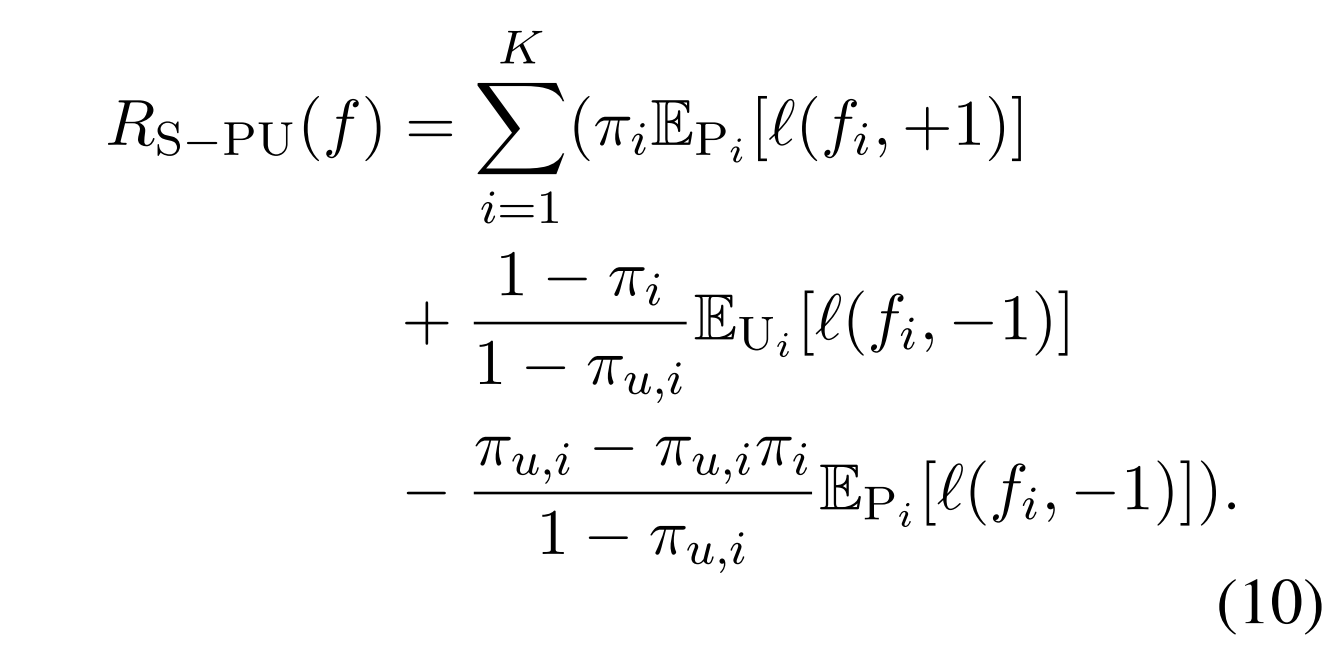
因此,我们可以得到训练数据的类先验转移下的非负风险估计器(Kiryo等人,2017),具体如下。
同样感觉是上面那个式子,带上权值后的一个变形
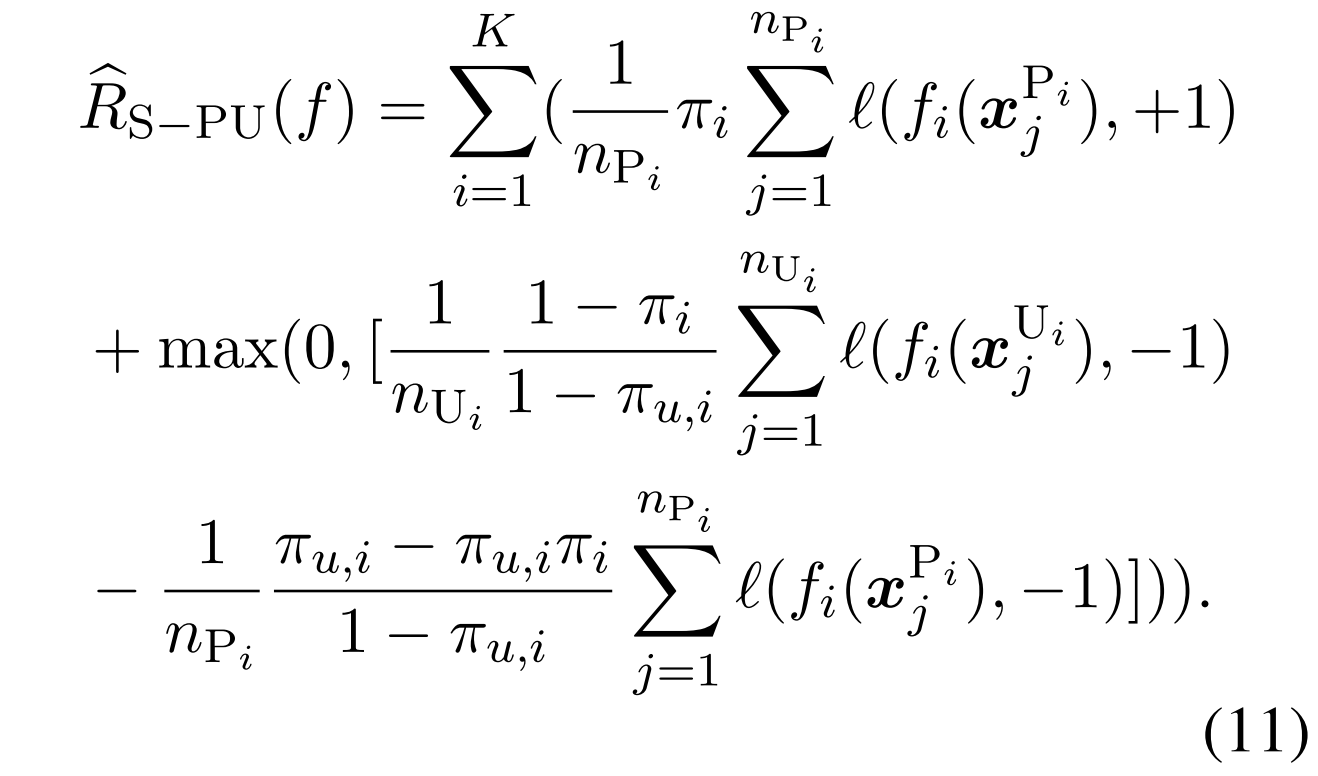
我们可以看到,PN学习和PU学习 是这个函数的特殊情况。当πu,i=0时,该方程还原为普通PN学习的形式,而当πu,i=πi时,该方程还原为普通PU学习的形式。
3.3 Squared ranking loss
为了更好地衡量文档级RE的性能,(Zhou和Lee,2022)提出了一个新的多标签性能指标
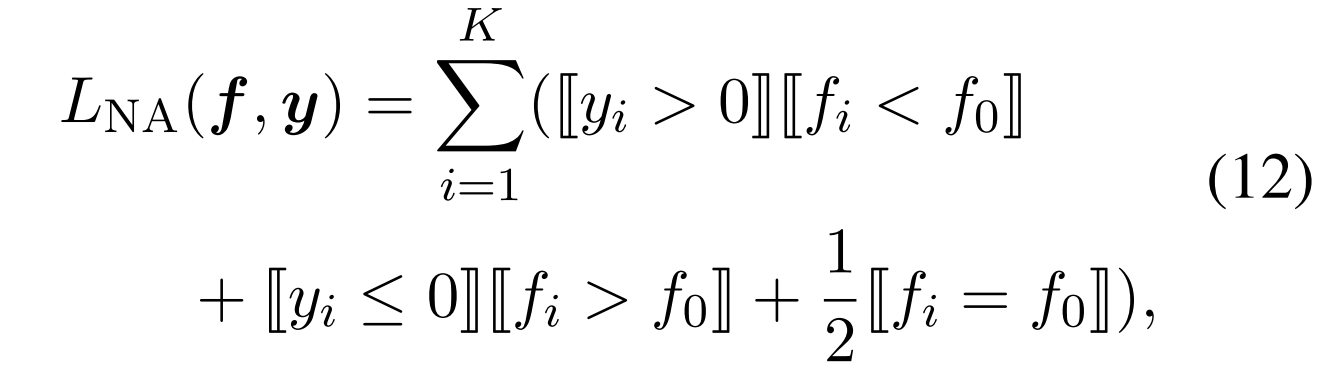
其中,正面的预设标签的排名应高于非类标签,负面的预设标签的排名应低于非类标签。是一个指标函数,当括号内的条件得到满足时取值为1,否则为0。

控制一种相对的差距?相对的就好了
4. 个人总结
多标签
Positive-Unlabeled Learning,瞄准的基准上是说,只需要标注positive的数据,未标注的数据,我也不知道是positive还是negative的,有可能是数据集漏标了,然后也是多分类问题

- 传统的PU学习,有一个loss,形如式子6这样,其中的l可以用平方损失(式子7)
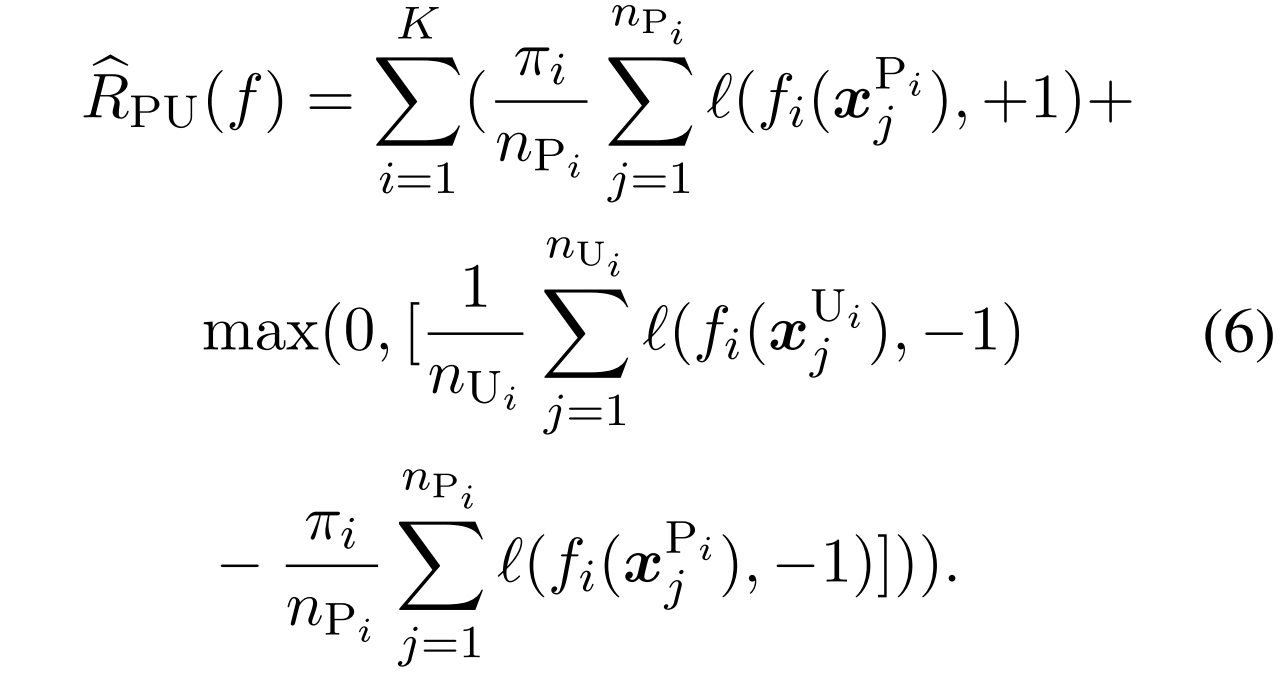
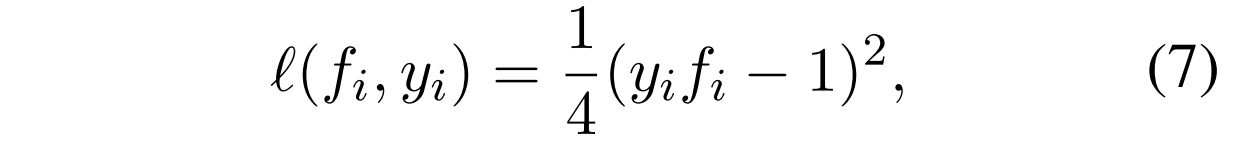
对于式子6,个人的理解是最小化第一个,最小化第二个,最大化第三个
- 基于一系列的分析,作者把这两个损失函数给改写了
基于先验知识shifting加权
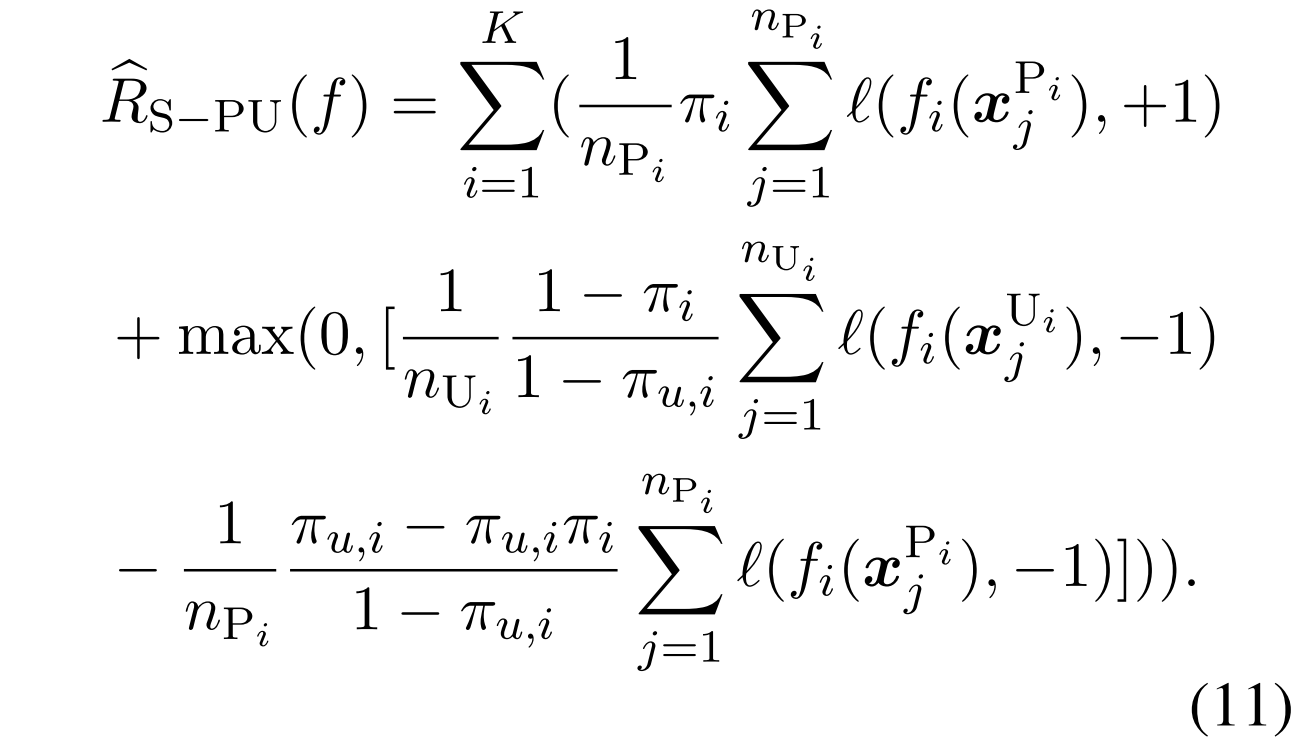
改成相对的差距,而不是绝对的fi数值
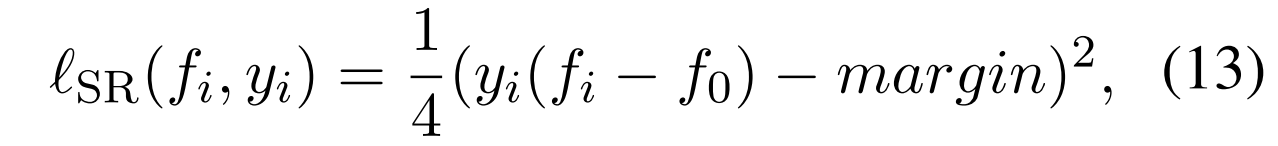
- 如果已知negative的话,好像还有一种PN的形式
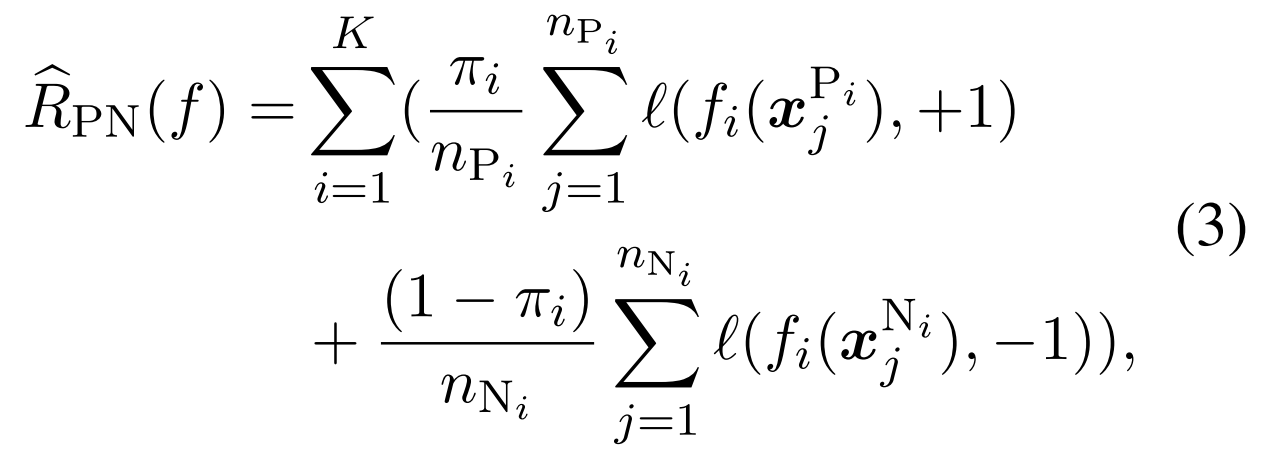
5. 不明白的问题记录
- 对PU学习的理解对不对,我的理解就是上面那个韦恩图中的感觉
- 看起来PU学习就是一个和损失函数相关的,这个是不是能做到相对即插即用?而且也是用在事件抽取领域上
- 这个从Method章节来看,好像和文档级也没什么关系,在句子级别上怎么感觉也可以用
- 即使不做他这个优化,直接PU学习的原始公式,感觉也会有提升吧