5种常见的Redis数据类型是怎么实现
5种常见的Redis数据类型是怎么实现
五种常见的redis数据类型是:String、List、Set、Zset、hash
1. String类型内部的实现
String类型底层的数据结构实现主要是SDS(Simple dynamic string,简单动态字符串)。SDS和我们认识的C字符串不太一样,之所以没有使用C语言的字符串表示,因为SDS相比于C的原生字符串:
- SDS获取字符串长度的时间复杂度是O(1)
因为C语言的字符串并不记录本身的长度,所以在获取长度的时候时间复杂度为O(n);而SDS结构里用len属性记录了字符串的长度,所以复杂度为O(1);
- SDS不仅可以保存文本数据,还可以保存二进制数据
因为SDS使用len属性的值,而不是\0字符串来判断字符串是否结束,并且SDS的所有API都会以处理二进制的方式来处理SDS存放在buf[]数组里的数据。所以SDS不光能存放文本数据,而且能保存图片、音频、视频、压缩文件这样的二进制数据
- Redis的SDS是 API安全的,进行分strcat等操作的时候,不会造成缓冲区溢出
SDS在拼接字符串之前会检查SDS空间是否满足要求,如果空间不够会自动扩容,所以不会导致缓冲区溢出问题
2. List类型内部实现
List类型的底层数据结构,是由双向链表或压缩列表实现的:
如果列表元素小于512个,列表的每个元素值都小于64字节,redis会使用压缩列表作为list类型的底层数据结构(小数据规模才使用压缩列表,因为压缩列表的修改是一个额外的消耗)
如果列表的元素不满足上述条件,redis会用双向链表作为list类型的底层数据结构
在最新版本,List数据结构底层就只由quicklist实现
quicklist补充
感觉是综合了双向链表和压缩列表
其实 quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。
在前面讲压缩列表的时候,我也提到了压缩列表的不足,虽然压缩列表是通过紧凑型的内存布局节省了内存开销,但是因为它的结构设计,如果保存的元素数量增加,或者元素变大了,压缩列表会有「连锁更新」的风险,一旦发生,会造成性能下降。
quicklist 解决办法,通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。
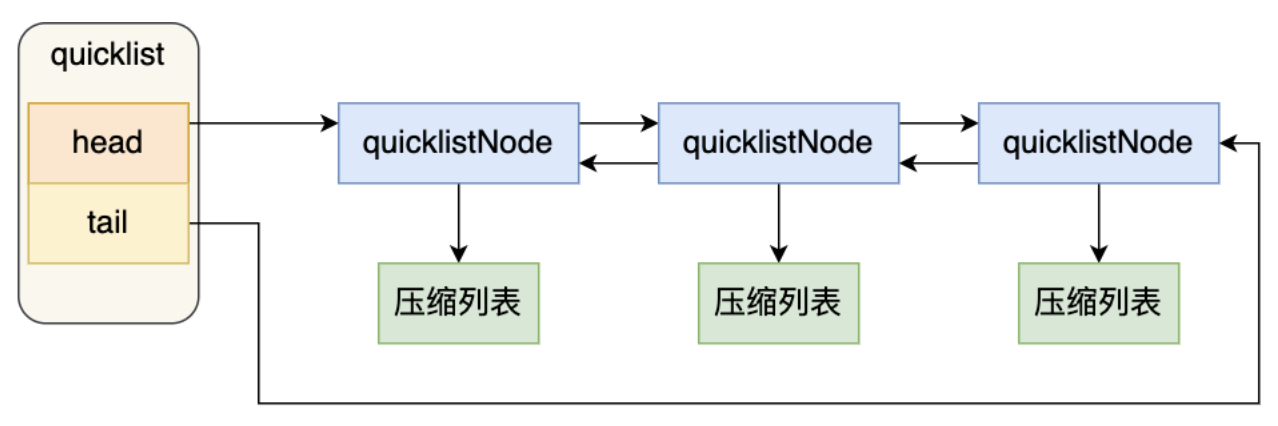
在向quicklist添加一个元素的时候,不会像普通的链表那样,直接新建一个链表节点。而是会检查插入位置的压缩列表是否能容纳该元素,如果能容纳就直接保存到quicklistNode结构里的压缩列表,如果不能容纳,才会创建一个新的quicklistNode结构
quicklist会控制quicklistNode结构里的压缩列表的大小或者元素个数,来规避潜在的连锁更新风险,但是并没有完全解决连锁更新的问题。
3. Hash类型内部实现
Hash类型的底层数据结构是由压缩列表或哈希表实现的:
- 如果哈希元素数小于512个,所有值小于64字节,redis会使用压缩列表作为hash类型的底层数据结构
- 如果哈希类型元素不满足上面的条件,redis会用哈希表作为hash类型底层的数据结构
在新版redis中,压缩列表被丢弃了,改成listpack数据结构实现
listpack数据结构补充
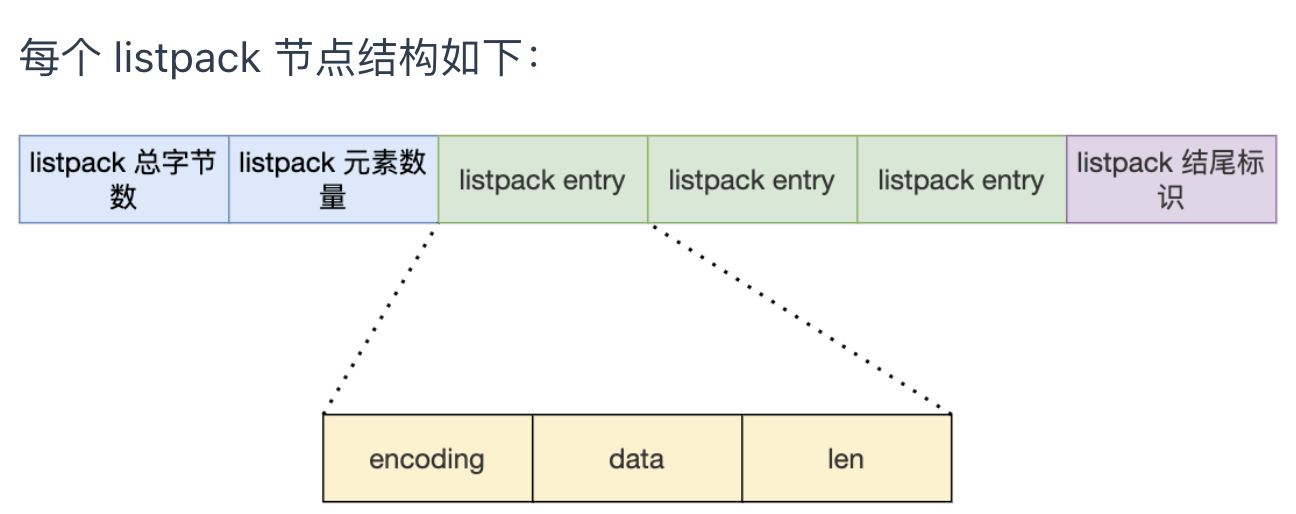
- encoding:定义该元素的编码类型,会对不同长度的整数和字符串进行编码
- data:实际存放的数据
- len:encoding+data的总长度
可以看到,listpack没有压缩列表中记录前一个节点长度的字段了,listpack只记录当前节点的长度,当我们向listpack加入一个新元素的时候,不回应系那个其他节点的长度字段的变化,从而避免了压缩列表的连锁更新
4. Set类型内部实现
Set类型的底层数据结构是由哈希表或整数集合来实现的:
- 如果集合中的元素都是整数,且元素个数小于512,redis会使用整数集合作为Set类型的底层数据结构
- 如果集合中的元素不满足上面条件,则redis使用哈希表作为Set类型底层的数据结构
整数集合补充
哈希表补充
5. ZSet类型内部实现
ZSet类型的底层数据结构是由压缩列表或跳表来实现的:
- 如果有序集合元素个数小于128个,并且每个元素值小于64个字节的时候,redis会使用压缩列表作为ZSet底层的数据结构
- 如果不满足上面的条件,会用跳表作为Zset类型的底层数据结构
在新版本redis中,压缩列表被丢弃了,改成listpack数据结构实现
跳表补充
链表在查找元素的时候,因为需要逐一查找,所以查询效率非常低,时间复杂度是O(N)
于是就出现了跳表,在链表基础上改进,实现了一种「多层」的有序链表
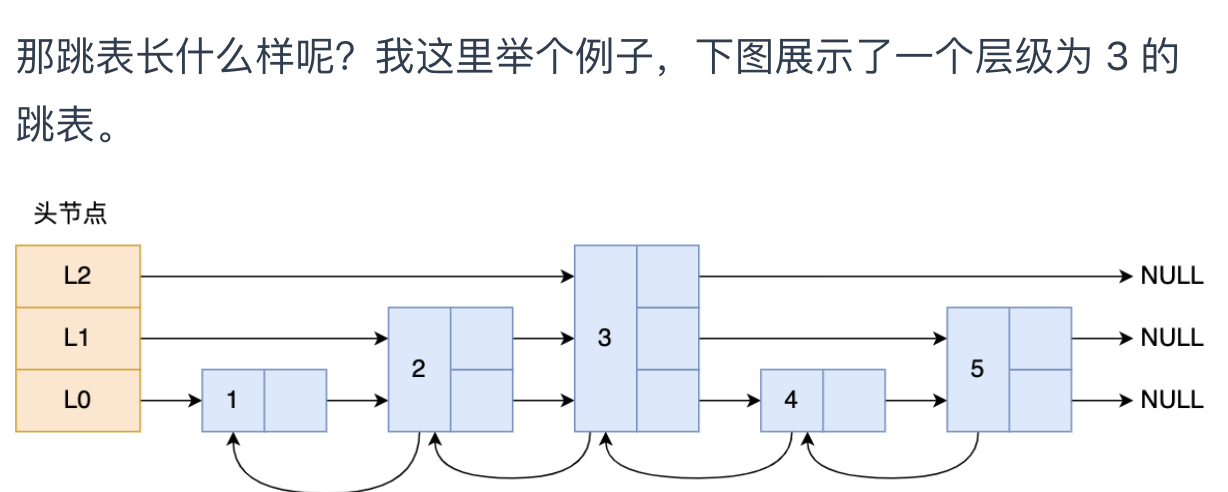
图中头节点有 L0~L2 三个头指针,分别指向了不同层级的节点,然后每个层级的节点都通过指针连接起来:
- L0 层级共有 5 个节点,分别是节点1、2、3、4、5;
- L1 层级共有 3 个节点,分别是节点 2、3、5;
- L2 层级只有 1 个节点,也就是节点 3 。
如果我们要在链表中查找节点 4 这个元素,只能从头开始遍历链表,需要查找 4 次,而使用了跳表后,只需要查找 2 次就能定位到节点 4,因为可以在头节点直接从 L2 层级跳到节点 3,然后再往前遍历找到节点 4。
可以看到,这个查找过程就是在多个层级上跳来跳去,最后定位到元素。当数据量很大时,跳表的查找复杂度就是 **O(logN)**。