ElasticSearch上层问题
ElasticSearch上层问题
1. ElasticSearch原理及简介
reference:
https://zhuanlan.zhihu.com/p/62892586,该篇博客对上层说的比较全面,是一种漫画的形式,这里对他进行一个整理
1.1 倒排索引
1.1.1 引入
在诗词的飞花令环节中,要求说出带”前“字的诗句,这么说来说是比较难想出诗句的
然而“窗前明月光,疑是地上霜…” “日照香炉生紫烟,遥看瀑布挂前川”这些家喻户晓的诗词中就带有“前”字
脑子里想不起来的原因,就是因为没有建立倒排索引
一般来说,背诗的时候会是一个从前往后的记忆顺序,先记诗名、作者,然后背诗的内容,脑子里的索引可能就会是像下图这样的,以诗名作为key,诗的内容作为value,让背静夜思很快就能反应过来,因为从索引找到了诗
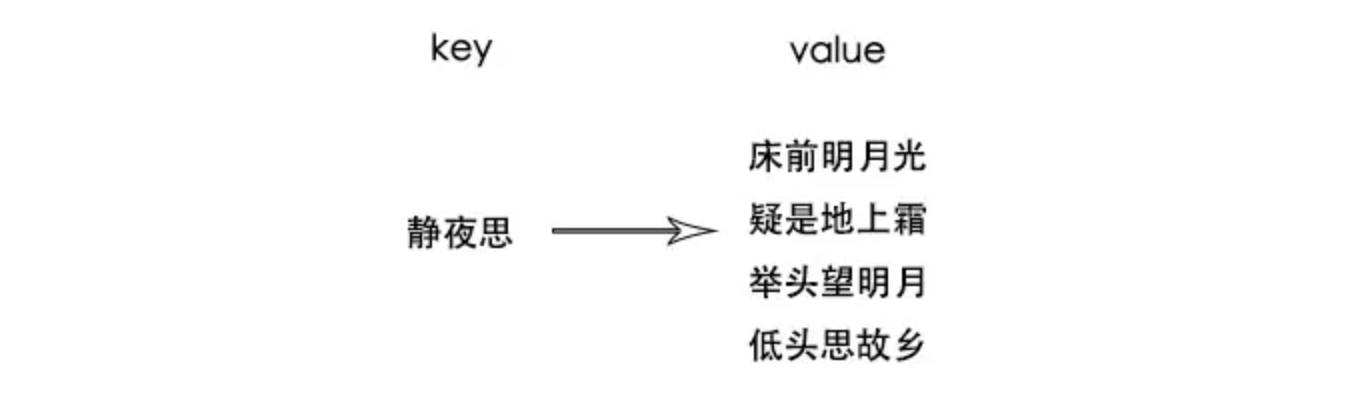
但是如果是说出带“前”字的诗句,由于没有索引,只能遍历脑海中的所有诗词,当诗词量大的时候就找的很慢了
倒排索引, 又叫反向索引,下面来举一个例子,如果以这种方式简历索引。以“前”字作为key,诗句内容作为value。
这就是倒排索引,以诗句内容中的一些关键字作为索引,来找到诗句

1.1.2 索引量爆炸问题
上面这个方式来说,很容易想到索引量爆炸这个问题,因为每个字都可以建立索引,那么将会多个key对应同一份value
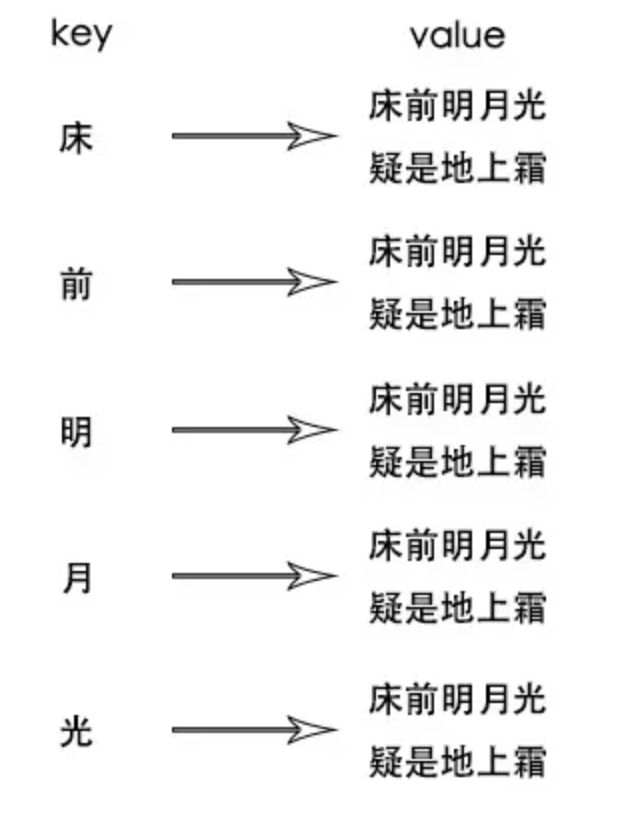
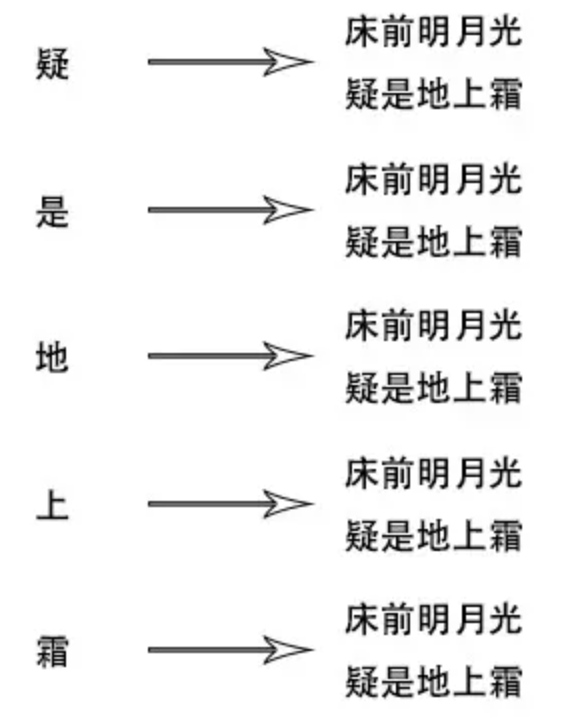
一句诗就可以建立10个倒排索引,诗词字数越多,索引量还要更多,记忆量会爆炸性增长,于是会进行压缩
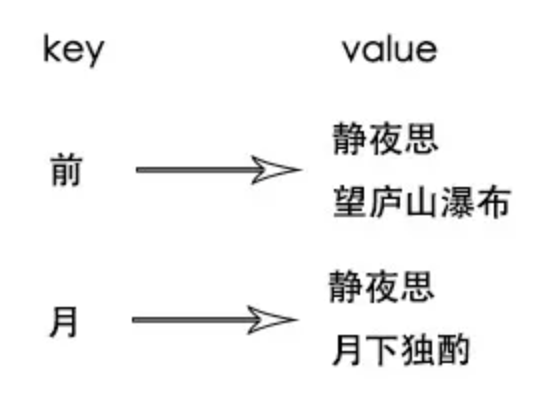
既然可以通过诗名就想起一首诗,那反向索引就没有必要索引到诗句了!而是只索引到诗名就可以
这个代入数据场景的话,是不是索引到id就可以了,数据遗漏问题,就是id重复了给漏了?
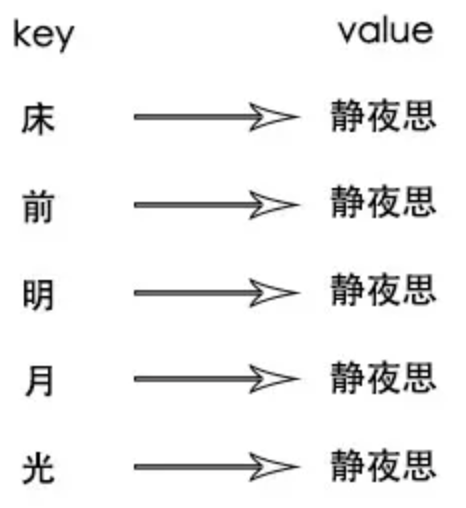
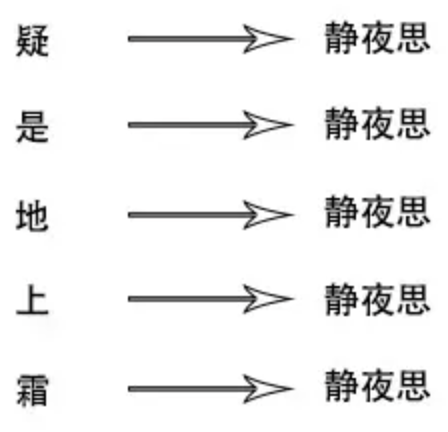
倒排索引的value不存诗句,改存诗名,这样数据量就可以减少很多,诗名可以理解正正向索引,静夜思->“窗前明月光,疑是地上霜…”
这是一首诗的情况,多首诗可以形成索引矩阵的形式
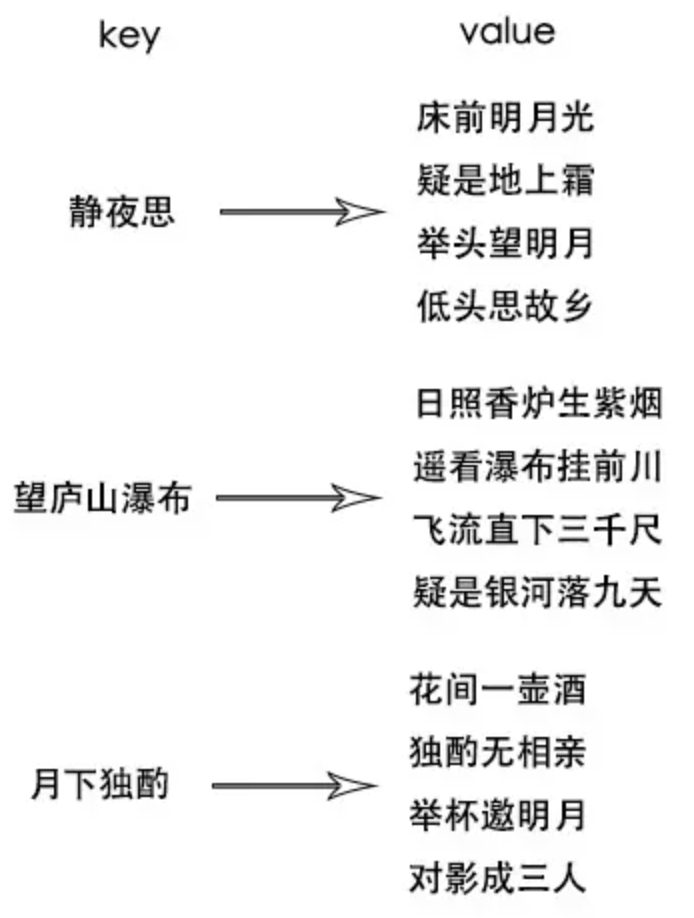
初中的赛诗会,要是了解这种结构就好了hh
1.2 搜索引擎原理
上面这个索引过程和百度或者谷歌的搜索是类似的,根据一个内容,去找要找的文章
像百度,谷歌这些搜索引擎的原理和背诗是一样的,最核心的都是建立倒排索引,快速命中想要搜索的内容
搜索引擎的流程要更加复杂一些,包括网页爬取和停顿词过滤等
1.2.1 爬取+停顿词过滤+建立反向索引
的、而这种词可以认为是停用词,可以给过滤掉,没必要建立索引,这就是所谓的分词
搜索引擎都是对文章分词之后,再根据关键字建立倒排索引的策略
搜索引擎三大内容:爬取、分词、建立反向索引
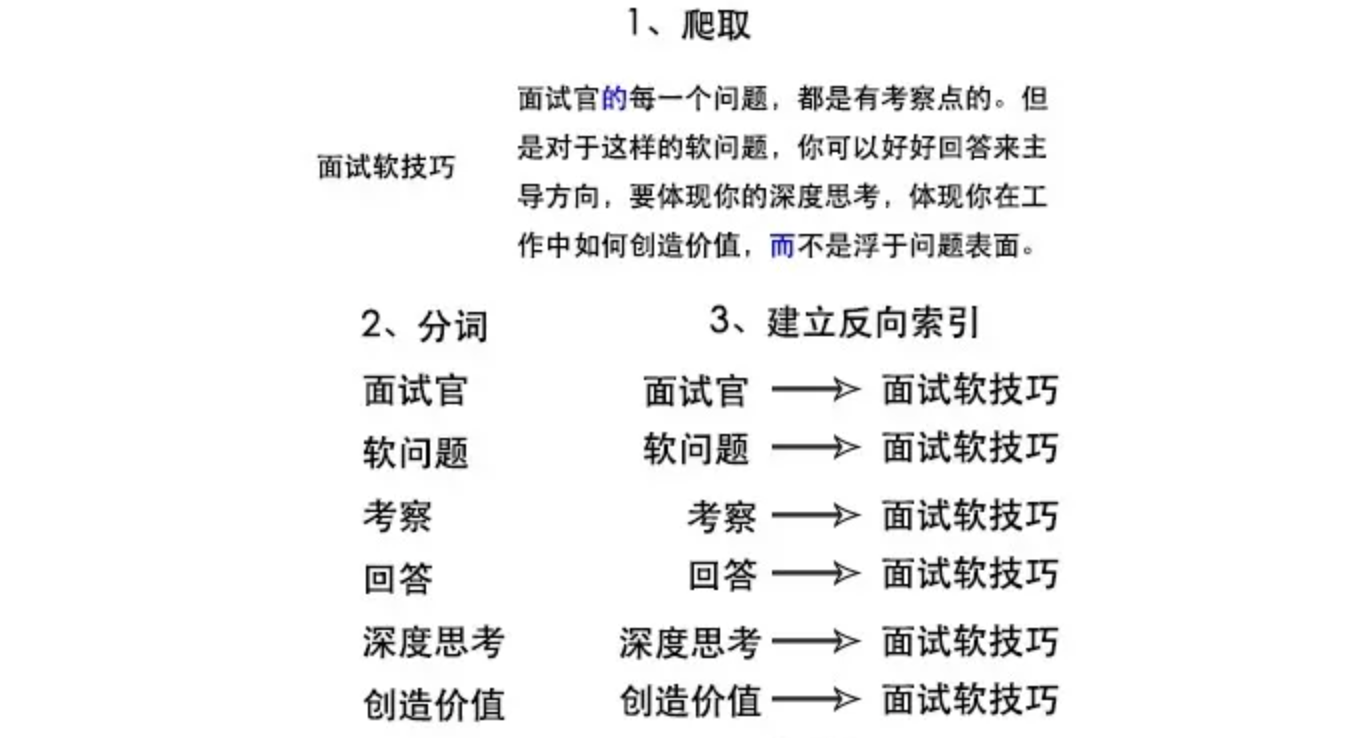
在使用的es中,通过ik-analyzer和pinyin-analyzer来进行分词等,这样来建立反向索引,中文场景这种基本差不多
之后要补充一些特殊设置和参数
1.3 ElasticSearch简介
一个搜索引擎的实现工足量是巨大的,业界已经有成熟的开源解决方案了,最早是lucene,可以方便的建立倒排索引
但是lucene还是一个库,必须要懂一点搜索引擎的原理才能用的比较好,后来又有人基于lucene进行封装,写出了ES
ES的好处:
- 将搜索引擎内部的操作封装成了restful的API,通过http请求就能对其进行操作
- 考虑了海量的数据,实现了分布式,是一个可以存储海量数据的分布式搜索引擎(怎么理解分布式?)
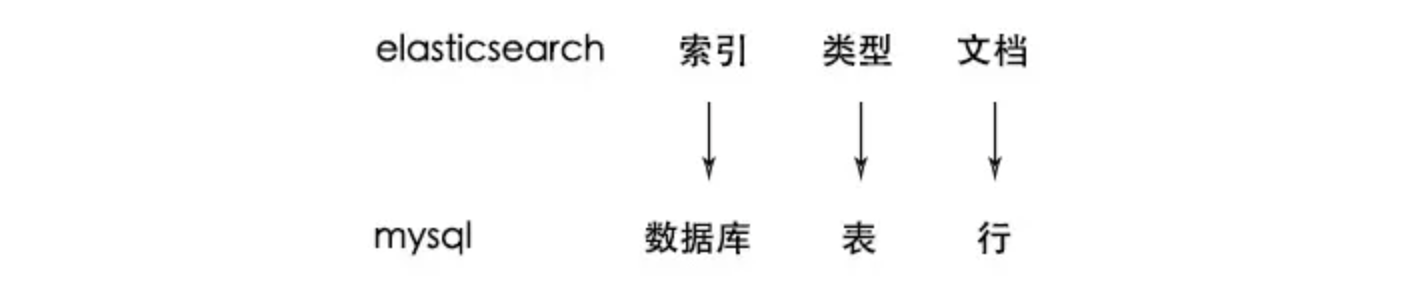
1.3.1 ElasticSearch基本概念——索引、类型、文档
- 索引index
这里的索引和刚刚说的key不是一个概念,es中的索引是存放数据的地方,可以理解为mysql中的一个数据库
- 类型
类型是用来定义数据结构的,可以认为是mysql中的一张表
- 文档
文档就是最终的数据了,可以认为一个文档就是一条记录
1.3.2 ES的索引,这里以自己项目中的索引为例
索引的名称是online-index-v9-1_c
索引的类型是online-index-v9-1_c
然后内部有date类型、keyword类型、integer类型、text类型等
类型相当于表结构的描述,每个字段的类型以json形式描述一行
1 | |
上述索引中,keyword和text表示的都是字符串,区别是什么?
keyword类型是不会分词的,直接根据字符串建立反向索引
text类型在存入es的时候,会先分词,然后根据分词后的内容建立反向索引
1.3.3 常用到的ik-analyzer和pinyin-analyzer
ik-analyzer:
- 提供了最大分词功能,然后可以在分词后的基础上使用pinyin-analyzer
pinyin-analyzer:
- 保持首字母、首字母长度限制
- 全拼音保留
- 小写
- 去除重复项
- …
1.4 ElasticSearch分布式原理
elasticsearch也会对数据进行切分,同时每一个分片会保存多个副本,为了保证分布式环境下的高可用
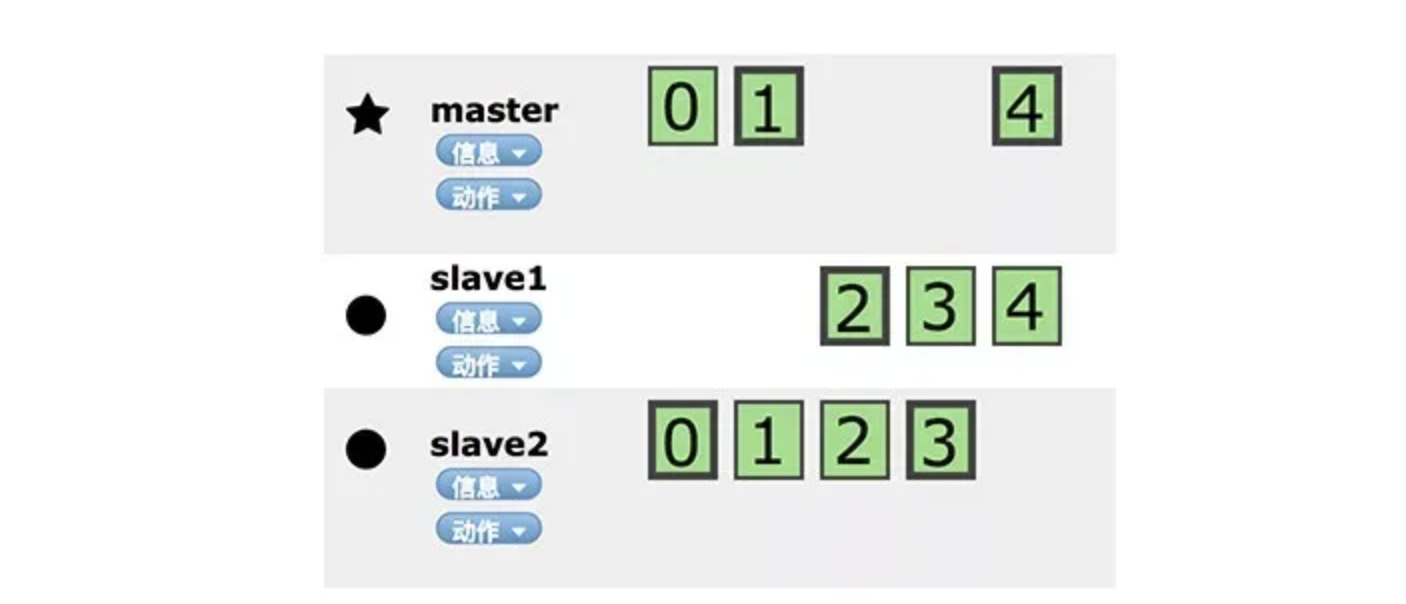
绿色表示数据块,其实es中的数据也是备份存储至多个节点
master-slave结构,节点是对等的,节点间户通过自己的一些规则选取集群的Master,Master会负责集群状态信息的改变
建立一个索引,就是先通知master建立索引,然后将信息同步给其他节点
1.5 ElasticSearch、Logstash、Kibana(ELK系统)
Logstash导入数据
Kibana查看,貌似还可以接入一些实时计算模块,做实时报警功能