emnlp2022_ACA论文阅读
EMNLP2022_Adversarial Class Augmentation论文阅读
EMNLP是刚刚camera ready的版本,相较于2022.11月下旬这个时间点来说是最新的顶会之一
motivation:
在持续学习中,常常出现灾难性遗忘问题,也就是说当模型学习新关系的时候,旧关系的性能就下降了。以前的研究针对的都默认了CRE模型已经充分学习了旧关系,而当新关系出现的时候想办法恢复旧关系;
但是作者发现,有可能是已经学习到的关系没有很好的鲁棒性,比如说当一个父子关系出现的时候,前面兄弟关系和这块就很容易混了,因为以前学习关系的鲁棒性太差了,可能模型在开始学习的时候,比如默认认为人名之间就是一个child的关系,但是后续出现father关系的时候,前面那种比较简单的可能就被flush或者怎么弄掉了;
主要贡献如下+自己总结:
自己总结
- 是一种model agnostic的方法,模型无关比较general
作者总结
1)我们对两种强CRE方法进行了一系列的实证研究,并观察到灾难性遗忘与类似关系的存在密切相关;
2)我们发现了CRE中灾难性遗忘的一个重要原因,这在之前的所有工作中都被忽略了:CRE模型存在识别新关系的学习捷径,而这些学习捷径对其类似关系的出现不够鲁棒;
3)我们提出了一种对抗类增强机制,以帮助CRE模型学习更稳健的表示。在两个基准测试上的实验结果表明,我们的方法可以始终如一地提高两种最先进方法的性能。
0. Abstract
连续关系提取(Continual Relation Extraction, CRE)旨在从类增量的数据流中不断学习新的关系。而现有的CRE模型通常存在灾难性遗忘问题,即当模型学习新关系时候,旧关系的性能严重下降。大多数先前的工作都将灾难性遗忘归因于新关系出现时所学表征的“腐败”,并隐含假设CRE模型已经充分学习了旧关系。
在本文中,通过实证研究,我们认为这一假设可能不成立,而灾难性遗忘的一个重要原因是,学习到的表示对于随后的学习过程中出现类似关系没有很好的鲁棒性。后续举例来说,就是在比如一个父子关系出现的时候,前面兄弟关系和这块就很容易混了,这样的感觉
为了解决这一问题,我们鼓励模型通过简单而有效的对抗类增强机制(Adversarial Class Augmentation, ACA)学习更精确和更健壮的表示,该机制易于实现且模型不可知(model-agnostic)。模型无关的方法,就是比较general的
实验结果表明,ACA可在两个流行的基准上持续改进最先进的持续学习关系提取模型的性能。
1. Introduction
- para1
关系提取(Relation Extraction)旨在检测句子中两个给定实体的关系。传统的关系提取模型是在具有预先定义的关系集合的固定数据集上训练的,无法处理不断出现新关系的现实生活情况。为此,引入了连续关系提取。
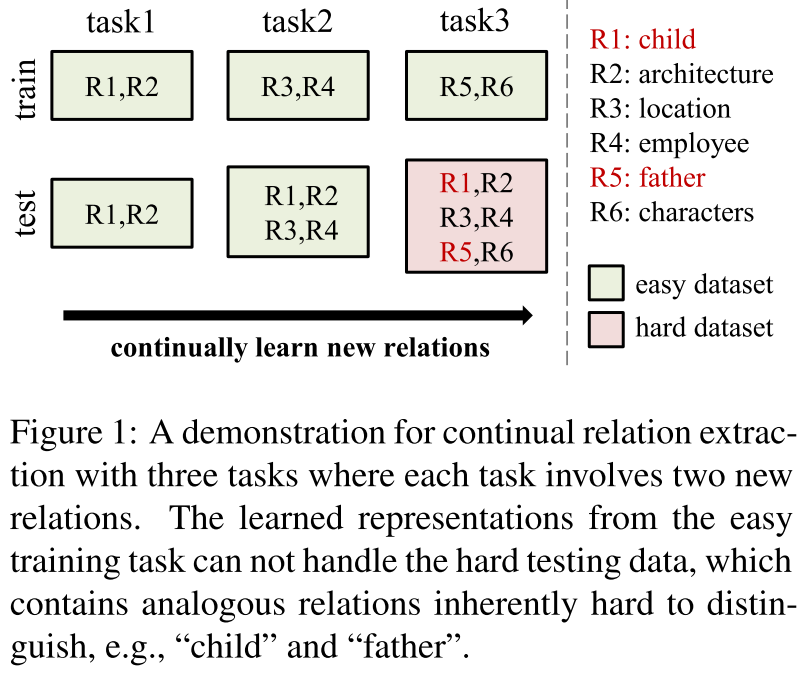
(图1:使用三个任务进行连续关系提取的展示,其中每个任务涉及两个新的关系。从简单训练任务中学习到的表示不能处理难的测试数据,其中包含固有难以区分的类似关系,例如“孩子”和“父亲”)学习到的表示对于随后出现的关系鲁棒性差,比如当一个兄弟关系出现的时候,以前学习的父子关系可能就被分类成兄弟关系了
如图1所示,CRE被公式化为一个类增量问题,它在一系列任务上训练模型。在每项任务中,模型需要学习一些新的关系,并根据所有看到的关系进行评估。与其他持续学习系统一样,CRE模型也遭受灾难性遗忘,即,在学习新关系时,先前学习的关系的性能严重下降。
从简单跑代码作者输出的日志来看,假设TACRED有40个关系,就是4个4个不断增量的
- para2
CRE的主流研究主要将灾难性遗忘归因于新任务到来时所学知识的腐败。为此,引入了各种复杂的基于排练的机制来更好的保留或恢复知识,如关系原型、课程元学习、对比回放和知识提炼。所有这些方法都隐含地假设模型已经充分学习了旧关系,然而在本文中,我们发现这一假设可能不成立。
没有充分学习旧关系——学习到旧关系的鲁棒性差,比如之前学习到的一个兄弟关系,后边新的父子关系来了后,之前学到的可能就被同化了这种感觉,主要是比较相似的关系
- para3
通过一系列的实证研究,我们发现灾难性遗忘大多发生在某些特定关系上,而当它们类似关系出现时,往往会发生显著的性能下降。根据我们的观察,我们发现了灾难性遗忘的另一个原因:
i.e.:由于对于相对容易的训练任务,CRE模型首先没有学习到足够鲁棒的关系表示
以图一中的“child”为例,由于任务1中没有hard negative类 (在对比学习中,hard negative是一个很关键的问题,如何引入并且特殊的针对hard negative,对指标上来说还是非常work的) ,CRE倾向于依赖虚假的快捷方式(例如实体类型)来识别“child”。这里我的感觉是说,比如通过简单的识别是一个名字词性的,就能判断是child了,但是后面的出来了这个就不行了
虽然学习到的不精确表示,可以处理任务1和任务2的测试集,但他们不够健壮,无法将任务3的“child”与其类似关系“father”区分开来。因此,当“father”出现时,“child”的表现将显著下降。相比之下,“architecture”等关系在任务3中仍然表现良好,因为他们的类似关系尚未出现
- para4
最近,对抗性数据增强成为一个强有力的baseline,以防止模型从简单的数据集中学习虚假的快捷方式。受这些工作的启发,我们引入了一种简单而有效的对抗类增强(Adversarial Class Augmentation, ACA),以增强CRE模型的鲁棒性。具体而言,ACA利用两种类扩充方法,即混合类扩充和反向类扩充,为新任务构建hard negative类。当任务到达时,ACA联合训练与对抗性增强类的新关系,以学习鲁棒性表示。
注意,我们的方法与之前的所有工作都是正交的:ACA专注于更好地学习新出现关系的知识(因为默认不是旧的关系学习不够好,是觉的旧的学的太简单了?) ,而之前的方法都是为了保留或者恢复旧关系的学习知识。因此,将ACA纳入之前的CRE模型可以更进一步的提升性能和表现。
- para5
我们将我们的贡献归纳为:
1)我们对两种强CRE方法进行了一系列的实证研究,并观察到灾难性遗忘与类似关系的存在密切相关;
2)我们发现了CRE中灾难性遗忘的一个重要原因,这在之前的所有工作中都被忽略了:CRE模型存在识别新关系的学习捷径,而这些学习捷径对其类似关系的出现不够鲁棒;
3)我们提出了一种对抗类增强机制,以帮助CRE模型学习更稳健的表示。在两个基准测试上的实验结果表明,我们的方法可以始终如一地提高两种最先进方法的性能。
2. Related Work
2.1 Relation Extraction
关系提取
2.2 Continual Learning
持续学习
2.3 Shortcuts Learning Phenomenon
上面两个或多或少有一些了解了,这个现象还不是很了解。在这里记录一下
- para1
快捷学习方式表明,DNN模型倾向于在数据集中学习不可靠的快捷方式,从而导致实际应用中的泛化能力较差。最近,研究人员揭示了不同类型语言任务的捷径学习现象,如自然语言推理、信息提取、阅读理解和问题回答。
Geirhos等人指出,捷径学习现象之所以发生,是因为“最小努力原则”,即人(动物和机器)自然会将解决任务的工作量最小化。
最近,数据增强和对抗性训练被用来缓解合成数据的捷径学习现象。据我们所知,我们是第一个从捷径学习的角度分析CRE中灾难性遗忘的工作,并提出了一种对抗性数据增强方法来缓解它。
将方法用在CRE任务上?进行组合创新?这种和dropout那些方法感觉背后原理会不会是相同的
3. Task Formulation
- para1
在持续学习关系抽取CRE任务中,模型是在一系列的任务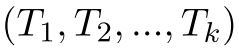 上训练的,每个Task
上训练的,每个Task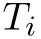 分别是训练集和测试集
分别是训练集和测试集
每个属于训练集和测试集的实例
这里应该是说,就是每个Task内部,只包含这个task的关系
CRE的目标是在新任务上不断训练模型,以学习新的关系,同时避免忘记以前学习过的关系
更正式的说,在第i个任务中,模型从训练集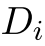 中被预测。
中被预测。
为了缓解CRE中的灾难性遗忘,先前的工作采用了一个存储器来存储每个旧关系中的几个典型实例(如10个),在随后的训练过程中,记忆中的实例将被回放,以减轻灾难性遗忘。
4. Catastrophic Forgetting in CRE: Characteristics and Cause
持续学习中的灾难性遗忘问题:特征和原因
在本节中,我们对两种最先进的CRE模型,即EMAR和RP-CRE,以及两个基准,即FewRel和TACRED进行了一系列的实证研究,以分析CRE中的灾难性遗忘。有关这两个benchmark和两个CRE模型的详细信息,请参考6.1节。
4.1 Characteristics of Catastrophic Forgetting(灾难性遗忘的特征)
- para1
我们使用Forgetting Rate(FR)来测量关系的平均遗忘。假定一个关系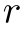 的FR被定义为:
的FR被定义为:
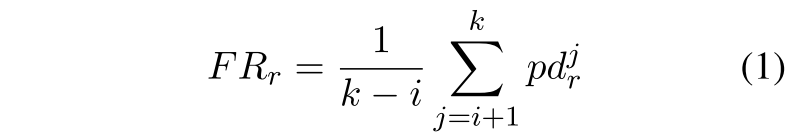

其中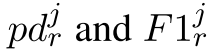 分别是任务$j$上的模型训练之后$r$的性能退化和F1分数。FewRel和TACRED的序列长度k均为10
分别是任务$j$上的模型训练之后$r$的性能退化和F1分数。FewRel和TACRED的序列长度k均为10
自己来解读一下这个式子, 假设i是5,k现在是8了,那么对于一个关系r(比如说“child”),他的遗忘率就是6 7 8三轮性能退化pd的平均值。假设对于j=7这个轮次的时候,性能退化是5 6轮(第i轮开始)的F1分数,减去当前轮F1分数的一个最大值
这个值是否只有退化的可能,不过按理说混入新关系后,只可能会更错?但也不一定?
- para2

(表1:我们将FewRel中的关系根据FR分类成三组。MS是max similarity的缩写。F1和F1* 分别是EMAR/RP-CRE的Macro-F1分数和将所有数据训练在一起的监督模型。∆ 是两个CRE模型和监督模型之间的性能差距。)
我们根据FR从小到大将关系分成三个同等大小的组,如表1所示,G1中的关系几乎不会被遗忘,因为因为EMAR和RP-CRE中的FR分别只有1.3%和1.2%。相比之下,G3中的关系具有灾难性遗忘,两种模型的FR都接近10%。这是FewRel上的实验结果
在TACRED上观察到类似的趋势(详情请参考附录A)。为了探究为什么FR在不同关系之间差异很大,我们深入研究了两个CRE模型的结果,并提出了两个问题。
这里的max similarity不太清楚是什么意思
4.1.1 Where catastrophisc forgetting happends?
- para1
仔细比较G1和G3,我们发现G3中的关系在数据集中似乎具有相似的关系。例如,“母亲(mother)”属于G3,并且在数据集中存在其语义上类似的关系,例如“配偶(spouse)”。
为了证实我们的发现,我们首先将一对关系的相似性定义为其原型的相似距离,i.e. 所有对应实例的平均vanilla BERT sentence embedding。然后,对于某个关系,我们计算它与数据集中所有其他关系的最大相似度(MS)。
将关系表征为一个sentence embedding,如果一个关系可能有多个词这样比如把“child”这个词给表示出来了,然后计算与数据集中其他关系的最大相似度,这里感觉不是数据集,感觉是一个group里的?也可能是一个数据集的,作者没有说的太明白
如表1中所展示的,G3的MS显著大于G1,表明灾难性遗忘主要发生在MS较大的关系上。此外,如最后两列(F1和F1∗(∆)) 在表1中,我们还观察到CRE模型和监督模型之间的性能差距随着MS的增加而显著增加,这表明CRE对识别与大型MS的关系提出了更严重的挑战。
4.1.2 When catastrophic forgetting happens?
- para1
我们还观察到,与高FR的关系在某些任务中的表现总是突然下降。为了探究性能严重下降的任务的特征,我们在50个不同的任务序列上运行了两个CRE模型,并记录了发生灾难性遗忘的所有糟糕情况(在模型学习新任务后,关系的F1分数下降超过10分)。
给定某个关系r及其对应的坏情况,我们标记存在r的前5个最相似关系的情况。

(表2:50次不同任务序列中的灾难性遗忘分析。”#CF”代表所有的灾难性遗忘case,”#SIM”是坏的案例,伴随着前5名相似关系的出现。)解读来说,就是当新关系混进来训练后,相似关系会更加容易导致灾难性遗忘
如表2所示,我们观察到,两个基准测试中80%以上的坏案例与前5个最相似关系的出现有关。以FewRel数据集中的关系“母亲”为例,90%以上的坏案例包含关系“配偶”,其与“母亲”的相似度最高。这些结果表明,对于遭受灾难性遗忘的关系,显著的性能下降通常伴随着其类似关系的出现。作者在appendix中给了更加详细的数据
4.2 Cause of Catastrophic Forgetting
这个章节的信息和上面感觉会很重复吗?实际上把这个名字起给上一节感觉也没什么问题
从开头来看,作者可能想说一些先前工作已经假设把历史关系学的够好了这样的
- para1
所有先前的CRE工作都将灾难性遗忘归因于持续学习过程中,所学知识的腐败,假设CRE模型已经充分学习了先前的关系。然而,我们认为这一假设可能不成立。在CRE中,模型在一系列独立的简单训练集上持续训练,其中每个数据集通常只包含很少的新关系,而没有类似的关系出现在一起。相反,CRE模型是在所有关系的更难测试数据集上进行评估的,该数据集通常包含类似的关系。
在真实场景中,这种情况更加容易出现,因为可能人为定义的关系不会那么正交,在维护过程中维护着维护着就乱了
一些研究者发现,深度神经网络倾向于在简单的训练数据集中学习虚假的捷径来做出决策,从而导致较差的泛化能力。因此,我们指出了学习关系性能下降的另一个重要原因:CRE模型在容易识别关系的训练数据集中存在学习捷径,而这些学习捷径对其类似关系的出现不够鲁棒。作者这里的解释还是挺不错的,就是说可能仅通过实体类型这种浅层的关系,就判断出两个的关系了
这一原因可以很好地解释我们观察到的现象,即灾难性遗忘主要发生在后续任务中具有相似关系的某些特定关系上,而当它们的相似关系出现时,几乎总是会发生显著的性能下降。
- para2
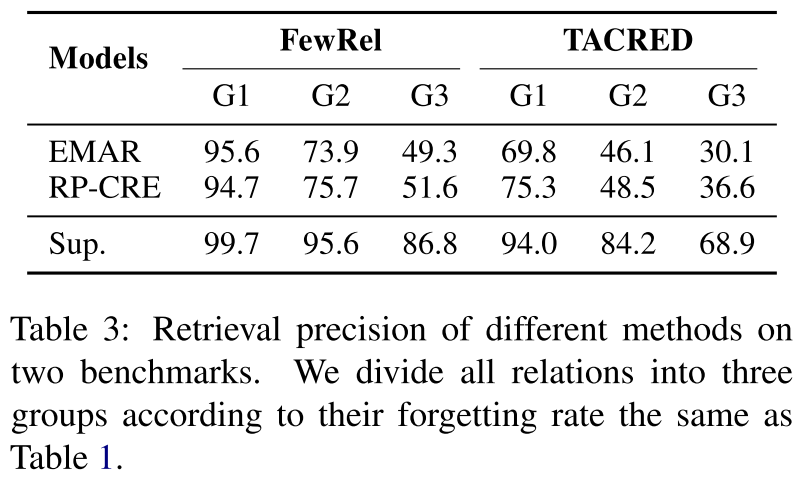
为了证实我们的假设,我们提出了一个检索测试:在CRE模型被训练以识别特定关系r之后,我们使用训练后的模型根据表示的相似性从整个测试集检索r的实例。如果所学习的表示不够鲁棒,则相应的检索精度将相对较低。
检错怎么理解,就是从相似度,以relation来反向检索实例?
表3显示了两个CRE模型和监督模型的检索结果的结果。与监督模型相比,两种CRE方法检索到了更多无关的实例,特别是对于遭受严重遗忘的关系,这表明CRE模型确实学习到了缺乏鲁棒性的表示。
5. Methodology
最近,对抗性数据增强显示了避免模型在简单数据集中学习虚假快捷方式的前景。因此,在本节中,我们提出了一种简单而有效的对抗性类增强机制(ACA),该机制包含两种类增强,以帮助CRE模型学习更稳健的表示。
5.1 Two-Stage Training
我们的ACA是模型不可知的(model-agnostic,这种一般是比较通用的方法),并利用流行的最先进的CRE模型作为骨干。因此,我们首先简要介绍了这些CRE模型的两阶段训练过程。
CRE模型旨在完成一系列任务: ,在不失一般性的情况下,我们用两个组件来表示CRE模型:
,在不失一般性的情况下,我们用两个组件来表示CRE模型:
1) 编码器,其将输入实例x映射到表示向量;
2) 一个分类器,它在当前任务之前的所有关系上产生概率分布,作为x的预测。

(图2:(a)演示了现有典型CRE模型的学习过程以及我们的Adversarial class扩充机制。(b)Hybrid-class augmentation. (c)Reversed-class augmentation. We use “[E11]/[E12]” and “[E21]/[E22]” to mark the head entity e1 and tail entity e2, respectively.)
这是一种有向性的关系
如图2(a)所示,以前的CRE方法通常可以制定为两个阶段的培训过程。
1) 初始训练:他们首先扩展分类器中的类节点以获得新的关系,然后仅使用新数据训练CRE模型以学习新的关系;
2) 记忆回放:他们首先用新数据更新记忆库,然后回放记忆库以恢复先前学习的关系的知识。
具体而言,之前的工作主要集中在记忆回放阶段,并提出了各种复杂的机制来更好地保留或恢复所学知识,而对初始训练阶段的改进仍在探索中。在他们的原始论文中查看这些CRE方法的更多细节。
先前主要就是一个memory replay的过程
5.2 Adversarial Class Augmentation
与所有先前的CRE模型正交,我们的ACA转而专注于第一个初始训练阶段,以提高新学习的关系表示的鲁棒性。具体来说,当新的任务Ti到来时,ACA首先基于新的训练集Di扩充新的关系Ri,然后一起训练原始关系和合成类。
5.2.1 Hybrid-class Augmentation(混合类扩充)

给定N个新的关系(在TACRED40个关系,分成10个阶段的时候,那就是给了4个关系?) ,我们将他们随机配对,得到N//2(下取整)个关系对。我们基于这些关系对构造混合合成类。具体来说,对于一个关系pair 。
。
对于上面的图来说,wp和wq是具有ri的关系,wm和wn是一个rj的关系,然后把wp和wn给拿出来,这里注意si后面的…和sj前面的…,这两个拼到一块生成x_hybrid
As shown in Figure 2(b), we first extract a span si that contains the head entity e1i but excludes the tail entity e2 i from xi,
and a span sj that contains the tail entity e2j but excludes the head entity e1 j from xj, and
concat在一起生成$x_{hybrid}$,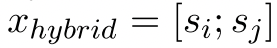
we can construct N//2 extra classes
这里不理解,为什么没有反向的sj和si的这个hybrid关系,这样就是N个了?另外这样的话,label标签是什么,这两个之间有什么关系????
5.2.2 Reversed-class Augmentation(反向class的数据增强)

我们将我们的关系分为两类,对称关系和非对称关系。这里和那个DialogRE是一样的
对称关系意味着头部和尾部实体的顺序无关紧要,例如“sibling”和“spouse”(有关两个数据集上对称关系的详细信息,请参阅附录e)。相反,不对称关系的语义与头部和尾部实体的选择有关,例如“located in”和“mother”。如图2(c)所示,反向类扩充反转每个不对称关系的头部和尾部实体,以构造额外的类。如图2(c)所示,反向类扩充反转了每个不对称关系的头部和尾部实体,以构造额外的类。
这个操作不应该是挺常见的,感觉这个方法还挺简单的
5.2.3 Adversarial Training
给定N个新关系,我们最多可以生成N+ N//2个使用两种增强方法的硬否定类。因此,在初始训练阶段,模型被联合训练以分类(2N+N//2)类,以更好地学习原始的新关系。在初始训练结束时,分类器中扩充类的扩展类节点将被移除。
这里的initial training是什么,这个好像还没有提到?应该不是指在预测时候不使用吧?
6. Experiments
6.1 Experimental Setups
6.1.1 Datasets
FewRel、TACRED
Following previous work (Han et al., 2020; Wu et al., 2021; Cui et al., 2021; Zhao et al., 2022), our experiments are conducted upon the following two widely datasets, and the training-test-validation split ratio is 3:1:1


6.1.2 Evaluation Metrics
继Cui等人(2021)和Zhao等人(2022年)之后,我们使用所有已知任务的平均准确度作为评估指标。对于更强的方法,每个任务的平均精度应始终高于基线
6.1.3 Baselines
暂时略过,model-agnostic
6.1.4 Implement Details
我们的ACA是模型不可知的,我们选择了两个最先进的CRE模型,EMAR和RP-CRE作为评估ACA的基础。存储库中每个关系的存储实例数为10。EMAR和RP-CRE的所有超参数与其原始论文的超参数相同。ACA不引入任何模型超参数。我们在具有48GB内存的单个NVIDIA A40 GPU上运行代码,并报告5个不同任务序列的平均结果。
6.2 Main Results
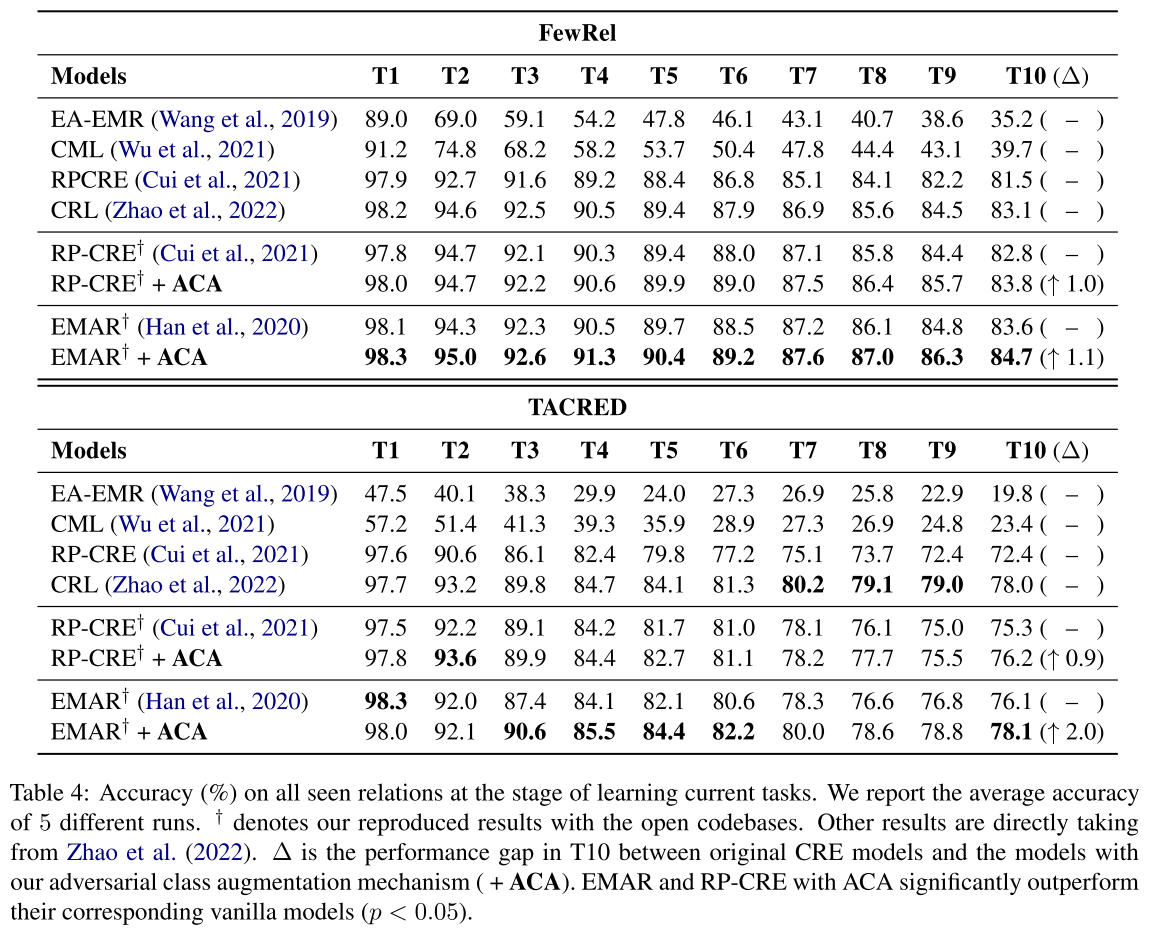
在T10的一个,是一个很关键的指标
7. Analysis
7.1 Ablation Study
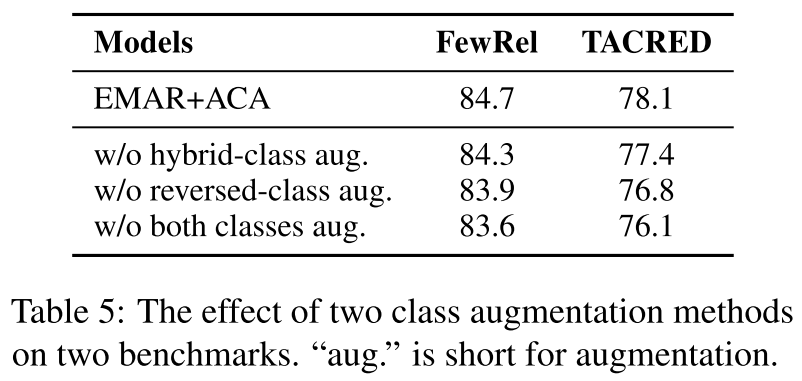
为了进一步探讨我们提出的两类增强方法的有效性,我们进行了消融研究。表5显示了两个基准上不同增强方法的EMAR结果。我们发现,这两种增强都有助于模型性能,并且它们相互补充。此外,反向类扩充比混合类扩充更有效。我们认为原因是反向类扩充可以保持所构建句子的流畅性,而混合类扩充不能。
7.2 Robust Representation Learning
- para1
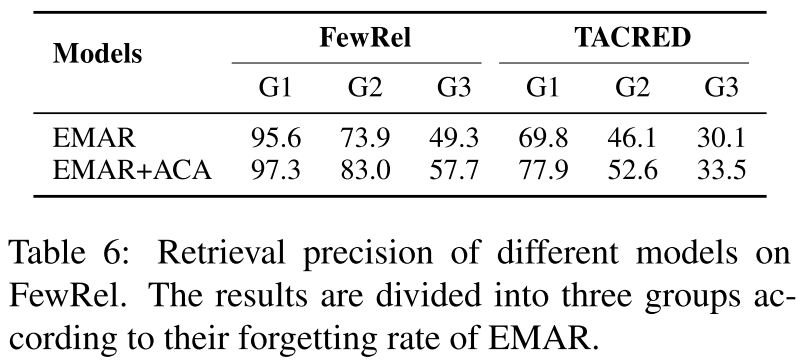
我们提出的ACA旨在学习能够更好地区分类似关系的鲁棒表示。为了进一步确认我们方法的有效性,我们首先复制了在我们的试点实验中引入的检索测试(更多详细信息,请参见附录C)。表6显示了EMAR和EMAR+ACA在两个基准上的结果。如图所示,ACA可以显著提高检索结果的精度,表明我们的方法确实有助于模型学习更稳健的表示。
- para2

我们还进行了一个案例研究,直观地展示了我们方法的有效性。我们考虑两种类似的关系P25(“母亲”)和P26(“配偶”),当P26出现时,EMAR灾难性地忘记了P25。在模型学习P25和P26之后,我们分别使用t-SNE来可视化属于这两个关系所有实例的表示。如图3所示:
1)对于EMAR,在模型学习关系P25之后,它依赖于虚假线索(例如实体类型)来识别P25的实例。因此,属于P25和P26的实例的表示混合在一起,这意味着P25的学习表示也可以表示P26的例例。当P26出现时,很难在P25的存储器实例非常有限的情况下用P26学习P25的更鲁棒表示,因此EMAR灾难性地忘记了P25(P25的F1分数显著降低了14分);
2) 对于EMAR+ACA,当学习P25时,该模型可以通过我们的增强关系学习P25的更鲁棒表示。因此,属于P25和P26的实例的表示比EMAR的表示更容易分离。当P26出现时,P25的遗忘问题大大缓解(P25的F1分数仅下降4分)。
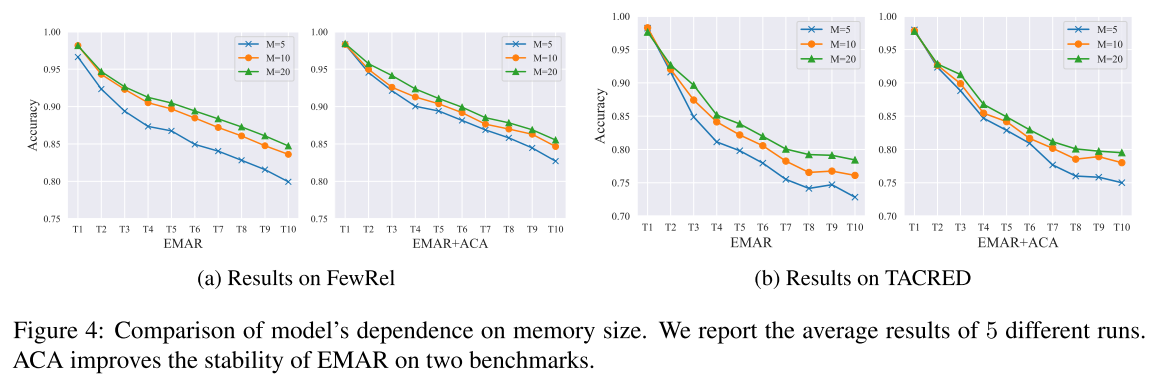
7.3 Influence of Memory Size
记忆大小是每个关系的记忆实例的数量,这是基于排练的CRE方法模型性能的关键因素。因此,在本节中,我们研究了内存大小对ACA的影响。
我们比较了内存大小为5、10和20的EMAR和EMAR+ACA的性能。如图4所示:
1)随着内存大小的减小,两个模型的性能都下降,显示了内存大小对于CRE模型的重要性;
2) 在FewRel和TACRED上,EMAR+ACA在所有三种不同的内存大小下都优于EMAR,进一步证明了我们的ACA的有效性;
3) 随着内存大小的减小,EMAR+ACA表现出相对稳定的性能。具体而言,EMAR+ACA在FewRel上形成EMAR 2.8、1.1和0.7精度
Memory size is the number ofmemorized instances for each relation, which is a key factor for the model performance of rehearsal-based CRE methods.
7.4 Error Analysis
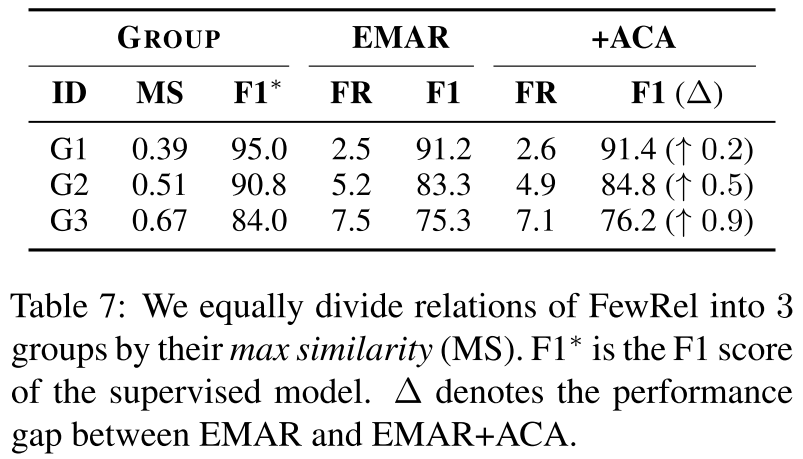
在本节中,我们进行了错误分析,以显示ACA的有效性和CRE的挑战。通过对灾难性遗忘的分析,我们发现关系的表现与它们的最大相似度高度相关。因此,我们根据关系的最大相似度将其平均分为三组。如表7所示:
1) ACA主要提高了最大相似度较大的关系的性能并降低了遗忘率;
2) 尽管ACA是有效的,但具有最大相似性的关系仍然受到营养不良的影响并且与监督模型有很大的性能差距。因此,今后的工作应该更加关注这些关系。
8. Conclusion
在本文中,我们进行了一系列实证研究,以分析CRE中的灾难性遗忘,并发现灾难性遗忘大多发生在某些特定关系上,而当它们的类似关系出现在后续任务中时,往往会发生显著的性能下降。
基于我们的观察,我们发现了CRE中灾难性遗忘的一个重要原因,即所有以前的工作都忽略了这一点,即CRE模型存在识别新关系的学习捷径,而这些学习捷径对其类似关系的出现不够鲁棒。
为此,我们提出了一种简单而有效的对抗类扩充机制,以帮助CRE模型学习更稳健的表示。在两个基准上的大量实验表明,我们的方法可以进一步提高两个最先进的CRE模型的性能。
9. Limitations
我们的论文有几个局限性:
1)尽管我们从快捷学习的角度提供了一个新的视角来解释灾难性遗忘,并利用检索测试来证实我们的假设,但我们没有探索CRE模型学习哪些类型的快捷方式;
2) 我们的ACA具有两种测量方法,专门为CRE设计。然而,我们在本文中关于灾难性遗忘的发现在持续学习的背景下可能很常见。因此,如果我们能提出更通用的对抗性训练方法,使其适用于所有的持续学习系统,那就更好了;
3) ACA在初始训练阶段之前进行课堂模拟,这在骨干CRE模型之上引入了额外的计算开销。