该篇博客记录一些redis high level的总结性话语,适合用于redis的简单介绍,以及一些上层的概述
Redis总结
1. Redis在项目中的使用
1.1 智能114系统
1.1.1 记录用户历史的交互信息
简述:
每个用户在每次呼叫的时候会分配一个唯一的callId,在并发场景下,通过这个callId来对用户序列交互式通话进行记录;
每次用户请求过来的时候,通过callId作为key读取上一对话状态的lastTaskStatus、历史请求参数historyRequestParameters、历史相应参数historyResponseParameters,上一对话状态的查号召回结果(查号场景下)lastSeachRecall。供程序内部的流程和状态跳转进行使用;
每次用户请求经程序处理结束后,先通过callId再次取出记录的上述各种信息(lastTaskStatus,historyRequestParameters,historyResponseParameters,lastSeachRecall)等,执行delete删除该条callId对应的信息,然后把这些信息refresh后(如append最新的内容),然后重新在lpush回内存型数据库中。这一过程中还包含一个timestamp的记录;
在程序中dialog参数传值为end时,会将该callId存储于redis中的内容全部取出,记录日志;
程序和部署环境对系统安全有一些要求,这里在安装和部署redis的时候还做了一些安全性修改,比如说端口从6379改成6380,以及把一些敏感命令的操作的关键词重命名一样,记得有一个flushall,还有像delete这样的,好像是修改一个redis的config文件。另外这些修改后,如果从程序内部还想要执行这些操作,则需要修改安装后whl包的源码内容,修改对应操作的关键字;
使用redis的理由:
下面这两条比较浅层,真正要说的时候感觉还得复习完八股文后
- 内存型数据库,访问速度快。作为一个线上运行的商业级别系统,程序对效率有要求;
- 支持json(或者说是字典)格式的数据记录,存取从操作上来说比较方便;
代码拆解:
- 函数,refresh redis的这个过程,每次响应的时候来干
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| def refreshRedis(requestParameters, taskStatus, lastSearchRecall, historyRequestParameters, historyResponseParameters, returnInfo):
'''
TODO 待补充
'''
try:
historyRequestParameters.append(requestParameters)
historyResponseParameters.append(returnInfo)
mapping = {
'timestamp': time.time(),
'lastTaskStatus': taskStatus,
'lastSearchRecall': lastSearchRecall,
'historyRequestParameters': historyRequestParameters,
'historyResponseParameters': historyResponseParameters
}
r.delete(requestParameters['callId'])
r.lpush(
requestParameters['callId'],
json.dumps(mapping, ensure_ascii=False)
)
return 'SUCCESS'
except:
return 'ERROR'
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| ''' 读redis,init过程 '''
if requestParameters['dialog'] == 'begin':
r.delete(requestParameters['callId']) # begin时候清空redis
# debug,状态跳转
if debugFlag:
writeText = ''
writeText = "【跳转到0000会话初始】传值中dialog为begin"
Debug.debugModeWriteLog(
callId = requestParameters['callId'],
writeText = writeText
)
lastTaskStatus = '0000'
historyRequestParameters = []
historyResponseParameters = []
lastSearchRecall = []
# 为了防止一直begin,在这里需要refresh
else:
redisDict = r.lindex(requestParameters['callId'], 0)
if redisDict is None:
taskStatus = '0501'
returnInfo['resultTag'] = statusToTag[taskStatus]
returnInfo['resultInfo'] = {}
return json.dumps(returnInfo, ensure_ascii=False)
redisDict = json.loads(redisDict)
lastTaskStatus = redisDict['lastTaskStatus']
historyRequestParameters = redisDict['historyRequestParameters']
historyResponseParameters = redisDict['historyResponseParameters']
lastSearchRecall = redisDict['lastSearchRecall']
|
1
2
3
4
5
6
7
8
9
10
11
12
| def recordRedis(requestParameters):
redisJson = r.lindex(requestParameters['callId'], 0)
redisDict = json.loads(redisJson)
today = str(date.today().strftime("%Y%m%d"))
try:
os.mkdir('logs/'+today+'/')
except:
pass
fileDir = 'logs/' + today + '/' + str(requestParameters['callId']) + '.json'
with open(fileDir, 'a+', encoding='utf-8') as writer:
writer.write(json.dumps(redisDict, indent=4, ensure_ascii=False))
return True
|
1.1.2 多进程的数据同步问题
在uwsgi+nginx这样的并发配置场景下,有主进程还有很多worker进程,如通过ps -ef | grep [PID|NAME]等可进行查看,会包含UID,PID,PPID等信息,PPID就是这个进程的父进程ID,如果说父进程id是1的话就代表这个进程是主进程,这些之后整理在linux操作系统相关那一个文档中吧;
背景:
- 由于程序效率要求,每次只在冷启动的时候读取一次配置文件中的各项内容,特别是数量较大的关键词词典等,如果每次接口请求的时候都读取将会造成大量的无用消耗;
- 而由于多进程模式下,各个进程不共享参数,那么即使设计了如
reloadKeyword这样的接口,那么通过这个接口进行请求完成词典更新的时候,也只会使得这个进程的数据得到更新,而其它进程则还是老版预加载数据,造成了数据不同步的问题(也就是说被分发到这个已经被更新的进程上的请求会读取到新的数据,而被分发到未更新进程的,则会是获取老数据);
- 尚不知道工业界的解决办法,本来有个简单版的解决办法,在请求的时候设置一个多次调用的逻辑,这个多次调用的逻辑不能在外部执行,设想的是由client端或者某种脚本的方式来执行,但是这个方式不够优雅,进而开始寻找比较优雅的解决办法;
解决方法:
- 设计
currentReloadTime代表该进程当前的reload时间。设计redisReloadTime代表redis内部记录的全局系统reload时间,这个时间用规范化的字符串datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')进行表示;
- 在冷启动的时候,相当于为每个进程初始化一个
currentReloadTime,然后往redis内部传入一个当前时间的redisReloadTime(注:这两个时间在开始的时候是不相等的,另外由于冷启动和redis那边是分离的,也就是每次冷启动的时候首先要在redis中清掉这个);
- 在调用
/reloadKeywords接口的时候,会刷新redisReloadTime这个时间为调用的时间;
- 在每次程序的单一个进程收到请求的时候,首先从远程读取
redisReloadTime。将程序的currentReloadTime值和这个redisReloadTime值进行如下比较:
- 如果当前进程的
currentReloadTime小于这个redisReloadTime,则需要执行更新词典操作,执行如reloadCommonQueryWord()等函数后,把当前的时间值赋值给currentReloadTime
- 如果当前进程的
currentReloadTime大于这个redisReloadTime了,那么则说明当前这个进程已经处在最新状态,不需要再更新了;
- 在上面这样说法的操作下,调用
reloadKeyword接口只会影响几个进程接下来的最新一次请求的时间效率,相对于原版每次都影响有了一定程度的优化,起到了一定的热更新效果,不过还是未知工业界的热更新操作是怎么做到的;
代码拆解:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
global currentReloadTime
currentReloadTime = str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f'))
time.sleep(0.5)
redisReloadTimeDict = {
"redisReloadTime": str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f'))
}
if r.lindex('redisReloadTime', 0) is not None:
r.delete('redisReloadTime')
r.lpush(
'redisReloadTime',
json.dumps(redisReloadTimeDict, ensure_ascii=False)
)
previousRedisReloadTime = ''
if r.lindex('redisReloadTime', 0) is None:
redisReloadTimeDict = {
"redisReloadTime": str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f'))
}
r.delete('redisReloadTime')
r.lpush(
'redisReloadTime',
json.dumps(redisReloadTimeDict, ensure_ascii=False)
)
previousRedisReloadTime = redisReloadTimeDict['redisReloadTime']
print("callId: " + callId + ", 出现了取不到redisReloadTime的情况,重新置总体上的redisReloadTime是: " + str(redisReloadTimeDict['redisReloadTime']))
else:
redisJson = r.lindex('redisReloadTime', 0)
redisDict = json.loads(redisJson)
previousRedisReloadTime = redisDict['redisReloadTime']
global currentReloadTime
print("callId: " + callId + ", 该进程的currentReloadTime是: " + str(currentReloadTime))
print("callId: " + callId + ", 总体上的previousRedisReloadTime是: " + str(previousRedisReloadTime))
if currentReloadTime < previousRedisReloadTime:
reloadCommonQueryWord()
loadDoctorMovecarPriority()
currentReloadTime = str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f'))
print("callId: " + callId + ", 更新完成, 该进程的currentReloadTime是: " + str(currentReloadTime))
print("callId: " + callId + ", 更新完成, 总体上的previousRedisReloadTime是: " + str(previousRedisReloadTime))
print("callId: " + callId + ", 更新reloadKeywords类词典后(减去更新json类词典后是加载用时,不知道要多久): " + str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')))
else:
print("callId: " + callId + ", currentReloadTime > previousRedisReloadTime, 无需更新, " + str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')))
response = Entrance._114(requests, config, model, keywords, posClient, dictSearch, _114cfgs, INTENT_CLASSIFICATION_CONFIGS, QUERY_PHONENUMBER_CONFIGS)
print("callId: " + callId + ", 该次会话给出的response是: " + str(response))
print("callId: " + callId + ", 该次会话给出的response时间是: " + str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')))
|
1.1.3 智能114系统中redis使用到的内容详解
TODO,读完redis八股文相关
2. Redis综合上层概念
2.1 Redis是什么
redis是一个基于C语言开发的高性能key-value的内存数据库,可以用作数据库、缓存、消息中间件等。是一种NoSQL(Not-only SQL,泛指非关系型数据库)的数据库
补充:关系型数据库,也就是依据关系模型来创建的数据库。类似于“一对一、一对多、多对多”等关系模型。关系型数据库可以很好的存储一些关系模型的数据,比如一个老师对应多个学生,一本书对应多个作者等等,MySQL是最典型的关系型数据库
redis作为一个内存型数据库,有着这些特点:
- 性能优秀,数据在内存中,读写速度非常快,支持并发10W QPS;
内存:见操作系统笔记
QPS:见基础知识杂烩笔记
单进程单线程,是线程安全的(采用IO多路复用机制);
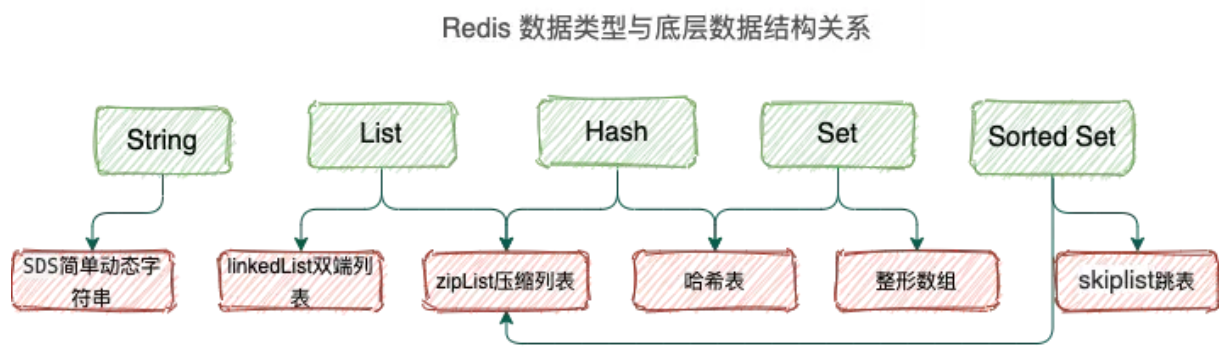
丰富的数据类型,支持:String,List,Hash,set,Sorted Set
2.2 Redis为什么这么快
https://zhuanlan.zhihu.com/p/460236324
2.2.1 到底有多快
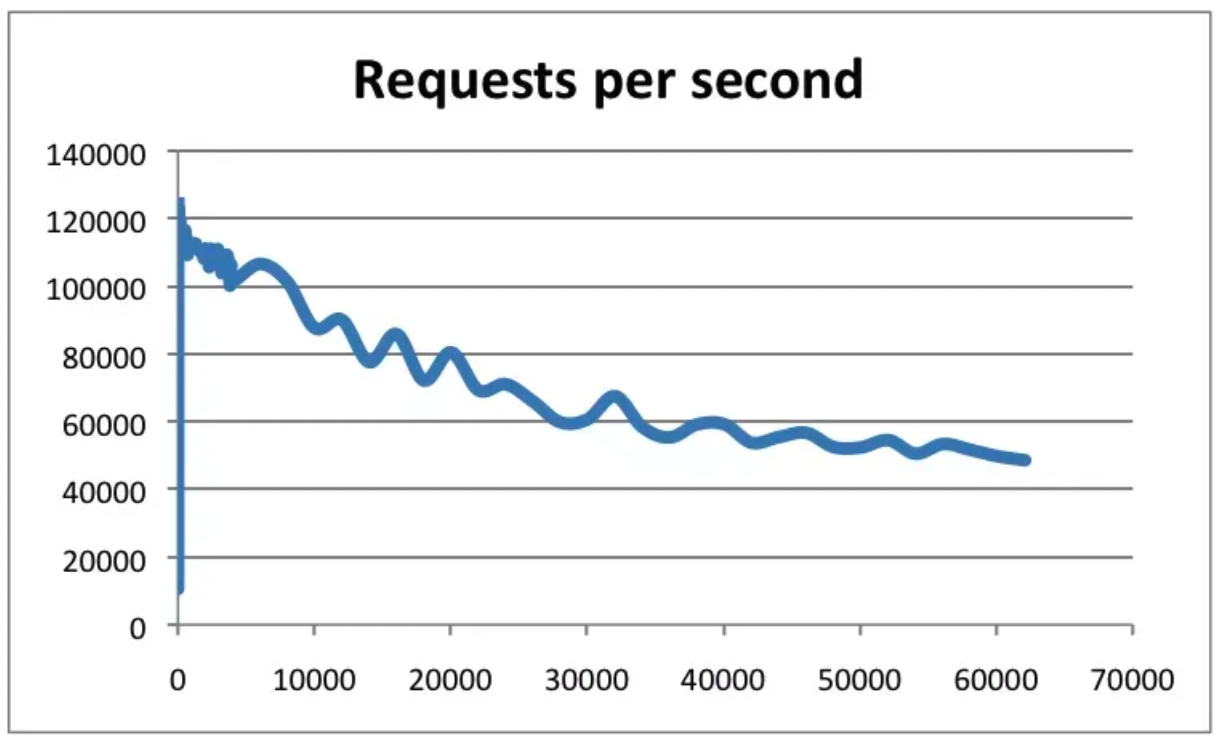
根据官方数据,Redis的QPS可以达到约100000。下图横轴是连接数,纵轴是QPS
2.2.2 基于内存实现
Redis是基于内存的数据库,和磁盘数据相比,完全吊打次破案的读写速度。
不论读写操作都是在内存上完成的。
内存直接由CPU控制,CPU内部继承的内存控制器……
2.2.3 高效的数据结构
学习MySQL的时候,直到为提高检索使用了B+ Tree数据结构,所以Redis速度快也可数据结构有关
redis支持5种数据类型,String、List、Hash、Set、SortedSet
不同的数据类型底层使用了一种或者多种数据结构来支撑,目标就是为了追求更快的速度