naacl2022_diffCSE论文阅读整理
naacl2022_diffCSE论文阅读整理
DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings
DiffCSE:基于差异的句子嵌入对比性学习,NAACL2022 MIT的文章,相对比较新
个人总结文章亮点如下:
1)motivation:SimCSE等研究发现,基于dropout的那种方法相较于同义词替换等等数据增强方法更好,这是不奇怪的。从对比学习的本质来说,虽然对比学习的目标鼓励一句话的表征不受增强转化的影响,但对于输入的直接增强(删除、替换)往往还是会改变句子含义的,也就是说,理想的句子嵌入不应该对这样的嵌入保持不变。即使是增强的这种替换类的操作,也应该一定程度上改变了句子的embedding表示?;;;作者:对转化敏感,但不一定不变?
2)在method那块,一方面类似SimCSE的那种两种dropout作为不敏感的变化,另一方面用replaced token decision(rtd)作为敏感的变化,借鉴了CV的内容;
Reference
- https://zhuanlan.zhihu.com/p/503701001:DiffCSE:Difference-based Contrastive Learning for SentenceEmbeddings (NAACL 2022)
- ELECTRA:https://huggingface.co/google/electra-base-discriminator
- 他这份代码也是在SimCSE基础上魔改的,https://github.com/voidism/DiffCSE
TODO-list
- pooler choice对着代码看一下
- 讨论为什么work
- discriminator那块是怎么搞的,怎么把h结合进去的?
0. Abstract
我们提出DiffCSE,一个用于学习句子嵌入的无监督对比学习框架。DiffCSE学习的句子嵌入对原始句子和编辑过的句子(edited sentence)之间的差异很敏感,其中编辑过的句子是通过随机掩码掉原始句子,然后从掩码过的语言模型中采样得到的。
从这里还不是太明白这个从掩码过的语言模型中采样是什么一种方法,先mask又弄回去的感觉?
我们表明,DiffSCE是一个等变(equivariant)对比学习的实例(Dangovski等人,2021),它概括了对比学习,并学习了对某些类型的增强不敏感而对其他 “有害”类型的增强敏感的表征。我们的实验表明,DiffCSE在无监督的句子表征学习方法中取得了最先进的结果,在文本语义相似性任务中,比无监督的SimCSE表现搞出了2.3个绝对的点数。
看这个abstract有些看不懂了,可能还要结合着方法看一看
1. Introduction
学习通用的句子表征,捕捉丰富的语义信息,同时在广泛的下游NLP任务中表现良好,无需特定任务的微调,是该领域的一个重要的开放性问题。最近的工作表明,通过对比学习对预训练的语言模型进行微调,可以在没有任何标记数据的情况下学习到好的句子嵌入。对比学习在单个数据上使用多种增强方法来构建positive pair,其表征被训练为比negative pair更加相似。
虽然不同的数据增强(随机裁剪、颜色抖动、旋转等)已被发现对预训练视觉模型至关重要,在应用于句子嵌入的对比学习时,这种增强的方法通常是不成功的。事实上,SimCSE发现,通过简单的基于dropout的扩增来构建positive pair的效果比更复杂的数据增强方法要好得多,比如基于同义词或屏蔽语言模型的词汇删除或替换。事后看来,这也许并不奇怪;虽然对比学习的训练目标鼓励表征不受增强转化的影响,但对输入的直接增强(如删除、替换)往往会改变句子的含义。也就是说,理想的句子嵌入不应该对这样的转换保持不变。
替换的方法从原理上就有些违背了?
我们提出去学习句子的表征,他们意识到但不一定是不变的,对于这种直接的表面层面的数据增强。这句话的原文英文不太好懂,写的也就比较绕:We propose to learn sentence representations
that are aware of, but not necessarily invariant to, such direct surface-level augmentations
这是一个等变对比学习的例子,这通过使用不敏感图像变换(例如灰度)上的对比损失和敏感图像变换上的预测损失(例如旋转)来改进视觉表示学习。我们通过使用基于dropout的噪声作为不敏感转换(如SimCSE)和基于MLM的单词替换作为敏感变换,对句子进行等变对比学习。这导致了基于原始句子和转换句子之间差异的额外交叉熵损失。
额外的交叉熵损失,L_{RTD}这个之前也有人用过了吧
我们在7个语义文本相似性任务(STS)和7个来自SentEval(Conneau and Kiela, 2018)的转移任务上进行了实验,发现这种基于差异的学习比标准的对比性学习有很大的改善。我们的DiffCSE方法在STS数据集上比之前最先进的模型SimCSE能实现约2.3%的绝对改善。我们还进行了一系列的消融研究,以证明我们设计的架构是合理的。定性研究和分析也包括对DiffCSE的嵌入空间的研究。
2. Background and Related Work
2.1 Learning Sentence Embeddings
这里暂时简化了,作者从最开始的SentenceBERT一路说到对比性学习开创性工作SimCLR,最后说到SimCSE。
最后,SimCSE(Gao等人,2021年)提出了一个极其简单的增强策略,只需切换dropout掩码。虽然简单,但以这种方式学到的句子嵌入已被证明比其他更复杂的增强方法更好。
2.2 Equivariant Contrastive Learning
DiffCSE的灵感来自于最近计算机视觉中的对比学习的概括,即等价对比学习(Dangovski等人,2021)。我们解释一下这种CV技术如何适应于自然语言。
了解输入转换(这里自己觉得好像是一些数据增强类的转化?) 对于成功的对比学习至关重要。过去的实证研究揭示了对比性学习的有用转化,比如计算机视觉的随机调整大小的裁剪和颜色抖动,以及NLP的dropout。对比学习鼓励表征对这些转换不敏感,也就是说,编码器被训练成对一组人工选择的转换不敏感。上述CV和NLP的研究也揭示了对对比学习有害的转换。例如,Chen等人(2020)表明,使表征对旋转不敏感会降低ImageNet线性探测的准确性,而Gao等人(2021)表明,使用MLM替换15%的单词会大大降低STS-B的性能。虽然以前的工作只是在对比性预训练中省略了这些转换,但在这里我们认为,我们还是应该通过学习对这些转换敏感(但不一定不变)的表征来利用这些转换;
敏感性的概念可以由数学中更普遍的等值属性来捕获。让$T$是来自一个group $G$的变换,然后使得$T(x)$代表对于一个sentence$x$的转化。等变性是指在输出特征上存在一个诱导的群组变换$T’$的特性,这个特性的数学表达如下:
$f(T(x))=T’(f(x))$
在对比性学习的特殊情况下, $T’$的目标是身份转换,我们说$f$被训练成“对$T$不变量”
这里作者这个表述一开始没有理解,现在来说的话就是groupG可能代表了多种变化操作,那么我们选择多种变化中的一种T,于是T(x)可以代表对x的一种变化操作的转化;这里从论文的这个公式来说不是很了解,可能要讨论一下;最后这个f被训练成对T不变量,就是说在等值这种情况下,我们的f应该对两种变化输出不变?
然而,不变性只是等价的一个微不足道的情况,我们可以设计一些训练目标,其中$T’$对某些转换(如MLM)不是同一的,而对其他转换(如dropout)是同一的。Dangovski等人(2021)表明,以这种方式将对比性学习推广到等值,可以提高CV中特征的语义质量,这里我们表明,不变性和等值的互补性延伸到NLP领域。关键的观察点是,编码器应该基于MLM的扩增具有等价性,而不是不变性。我们可以通过使用一个条件判断器来操作这一点,该判别器将句子表示与编辑过的句子相结合,然后预测原始句子与编辑过的句子之间的差异。
这基本是ELECTRA模型的条件版本,该模型通过一个二进制discriminator来检测一个标记是来自原始句子还是来自生成器,从而使编码器与MLM等效。我们假设,用我们的句子编码器的表征来调节ELECTRA模型的一个有用的目标,以鼓励$f$是“等效于MLM”
可能要看过方法后再反过来看看这一段,很多内容可能就理解了
就我们所知,我们是第一个 观察并强调上述CV和NLP之间的平行关系。特别是,我们表明,等价对比学习超出了CV的范围,它甚至适用于没有代数结构的转换,比如对句子的差异操作。此外,由于NLP中有用的转换的典型集合不如CV中那么确定,DiffCSE可以作为NLP研究者的诊断工具来发现有用的转换。
3. Difference-based Contrastive Learning
翻阅的时候发现这个章节长度很短,可能也是一种比较简单即插即用的方法?
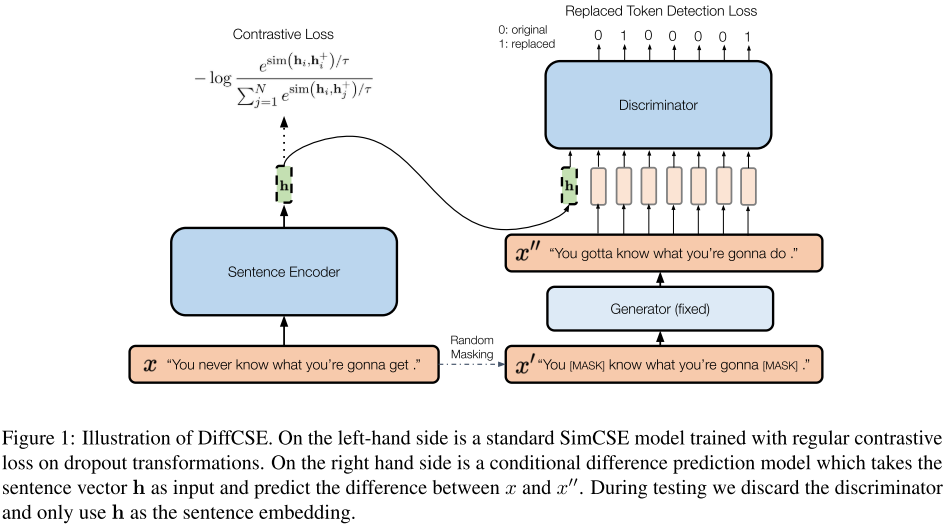
motivation:之前对某些句子修改是不敏感的,文本是离散的每个token稍微改变一下对语义影响都很大。模型对某些特定类型的增强是不敏感的,又对某些伤害了语义的增强的敏感的。x’ x’’有些替换是敏感的,有些是不敏感的,通过discriminator要鉴别一些语义变化敏感的。h的语义要表达出来是有变化的
左边h作为CLS放过来,h在encoder的映射中会和各个token会交互,起到交互作用了,引导…
x’’是作为正例了还是负例了?通过多任务学习改善预训练表征,在discriminator这块引入了一个新的;;为什么generator这块要用这样生成的方式来,而不是同义词替换,反义词替换;
代码simcse和diffcse来对比看,x’’已经出来文本了,在ELECTRA没法同步更新Discriminator和gen;;;;debiased 和simcse;;;右边的替换不当做正例和负例来看,只是看做一个替换RTD,又把左边的这个参与进来了;;;discriminator,我喜欢吃苹果 我爱吃苹果 很难判断出来,对这种不伤害语义的就不敏感
discriminator,我喜欢吃苹果 我爱吃苹果 很难判断出来,对这种不伤害语义的就不敏感;;x’’是我讨厌吃苹果,左边x是我喜欢吃苹果,cls输入进来后,就容易鉴别出来,cls;;;;多任务,增强了某个点上的表征,文本层面修改上的表征,自适应的敏感/不敏感,符合语义
图1:DiffCSE的图解。左边是一个标准的SimCSE模型,它是用常规的对比损失训练出来的dropout转换模型。右边是一个条件差异预测模型,它将句子向量h作为输入,预测预测x和x’’之间的差异。在测试过程中,我们抛弃了deiscriminator,只使用h作为句子嵌入。
自己写一下对这个图和为什么是work的理解:右边的discriminator也把h当做输入了,这样在梯度回传上会回传到sentence encoder上,这个h是怎么交互的还要理解,也就是说在一个h的引导下,希望能学习到这个差异?那么这个引导方式需要注意一下,因为之前CLINE那篇论文不需要这么做,也能够进行一个鉴别?
我们的方法很简单,可以看作是将SimCSE的标准对比学习目标(图1左)与差异预测目标(图一右)相结合。
- 对SimCSE部分的解释,这个已经见过很多次了
给定一个无标签的输入句子x,SimCSE通过应用不同的dropout掩码,为其创建了一个positive example x+。通过使用BERT_base编码器f,我们可以得到x的句子嵌入h=f(x),SimCSE的训练目标是:


- 对右边这个差异预测目标的解释(还要从loss函数的设计上,看看为什么能够引导到左边encoder来学习到更好的表示):
图1的右侧是ELECTRA(Clark等人,2020)中使用的差异预测目标的条件版本这里的条件是否指的是把h作为输入了,要交互一下有一个条件? ,它包含一个生成器和一个判别器。给定长度为$T$的一句话$x=[x_{(1)},x_{(2)},…,x_{(T)}]$,我们首先将其进行随机的掩码$m=[m_{(1)},m_{(2)},…,m_{(T)}],m_{(t)}\in[0,1]$,然后获取$x’=m·x$。我们使用另一个预训练的MLM作为生成器$G$,进行掩码语言建模,恢复$x’$中的随机掩码标记,得到编辑过的句子$x’’=G(x)$这里这个G是fix住的,不知道使用什么搞的 。然后,我们使用判别器$D$来执行标记检测(RTD)任务。对于句子中的每个标记,模型需要预测它是否被替换,单个句子$x$的交叉熵损失为:
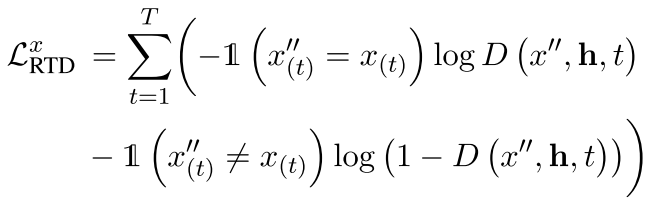
对于一个batch来说,要把这个loss求和: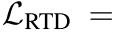

最后,我们将这两种损失与一个加权系数λ一起进行优化:
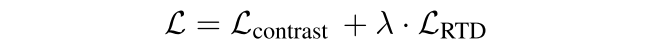
我们的模型和ELECTRA的区别在于,我们的判别器$D$是有条件的,所以它可以使用压缩在固定维度向量$h=f(x)$中的$x$的信息。$D$的梯度可以通过$h$反向传播到$f$。通过这样做,$f$将被鼓励使得$h$的信息量足以覆盖$x$的全部含义,这样$D$就可以区分$x$和$x’’$之间的微小差别。这种方法实质上是让条件判别器进行 “差异操作”,因此被称为DiffCSE。
读完method章节还是不太明白,主要是不明白这么操作是怎么和他motivation对上的,就是说我最后sentence encoder这边输出的h表征,既在SimCSE的引导下具有alignment和uniformity的特性,通过拉近正例推远负例增强了橘子的表征,但是这种可能导致了转化不敏感;;然后通过右边那个在h的引导下做鉴别,也就是说我这个h有能力覆盖含义,这样D就可以区分两者之间微小的差别(可能某几个词被替换了);;;句子表征h既有不敏感变化的能力,也有敏感变化的能力?
对于两句话,h能够很好的输出这两句话的表征,一种是差距比较大的比如两句话很离谱的那种通过SimCSE,然后一种差距不太大的,比如可能句法层面一样,而且只是换了几个词这样的我们也应当要敏感,那么通过右边的这种鉴别架构来学习,h要使得鉴别器具有更好的区分能力?
感觉还是想不到作者一个比较明确的motivation是什么:
当我们训练DiffCSE模型时,我们固定生成器G,只有句子编码器f和判别器D被优化。训练结束后,我们丢弃D,只用f(保持固定)来提取句子嵌入,以便在下游任务中进行评估。
3‘:知乎解读中一些要点的记录
motivation:
通过对比学习来学习sentence embedding的表示,一般的思路就是对单个样本使用multiple augmentation的方式来构造positive pair。这些方法的训练目标是在于让表征对于增广变换是不变的。(如SimCSE那种dropout-based的方法)
然而有些augumentation的方法,比如对input进行delete或者替换,往往会改变句子的含义,因此理想的augumentation的方法对于这些transformations因当时变化的(not invariat)。
在计算机视觉领域,这被称作equivariantcontrastive learning,在不敏感的image transformations(如灰度变化)使用对比损失,而在敏感的image transformations(如图片的旋转)上使用prediction loss;
想想这和CLINE的方法冲突不冲突,CLINE那篇好像不太专注的是句子表征这种下游任务,而是一些下游的一些攻击对抗那种例子
现在是用一个普通的方法生成的,那么如果是CLINE那种的呢,直接同义词反义词?
3‘’:ELECTRA记录
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA:预先训练文本编码器作为鉴别器,而不是生成器
是一种自我监督的语言表征学习的新方法。它可以用相对较少的计算量来预训练Transformer网络。ELECTRA模型被训练来区分 “真实 “的输入标记与另一个神经网络产生的 “虚假 “输入标记,类似于GAN的判别器。在小规模下,ELECTRA即使在单个GPU上训练也能取得很好的效果。在大规模情况下,ELECTRA在SQuAD 2.0数据集上取得了最先进的结果。
For a detailed description and experimental results, please refer to our paper ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators.
1 | |
作者的ELECTRA-with-Condition是怎么实现的?而且还说discriminator那块使用的是bert或者roberta,好像就是多了一个cls_input那块,然后把cls替换了,但是这样为什么就能起到更好的作用了,实在还是不太理解;
4. Experiments
4.1 Setup
在我们的实验中,我们遵循无监督的SimCSE(Gao等人,2021)的设置,并基于他们的PyTorch实现建立我们的模型。
我们还使用BERT(Devlin等人,2019)和RoBERTa(Liu等人,2019)的检查点作为我们句子编码器的初始化$f$
我们在[CLS]表示的基础上增加了一个MLP层,用batchnorm作为句子嵌入。我们将在第5节比较有/无batchnorm的模型。
对于判别器D,我们使用与句子编码器f(BERT/RoBERTa)相同的模型。
这里的判别器能用这样的模型吗,那么他那个h输入进去是怎么用上的,怎么好像也没有公式说明
对于generator G,我们使用较小的DistilBERT和DistilRoBERTa以提高效率
请注意,与ELECTRA论文(Clark等人,2020)不同,generator在训练期间是固定的。我们将在第5节中比较使用不同大小模型的generator的结果。更多的训练细节显示在附录A。
可以说这里的生成器是不关键的吗,是否有改进空间?好像也不是传统那种对抗训练的方式?
4.2 Data
对于无监督的预训练,我们使用了SimCSE的源代码所提供的10^6个从英语维基百科中随机抽出的句子。
We evaluate our model on 7 semantic textual similarity (STS) and 7 transfer tasks in SentEval.
STS tasks includes STS 2012– 2016 (Agirre et al., 2016), STS Benchmark (Cer et al., 2017) and SICK-Relatedness (Marelli et al., 2014). All the STS experiments are fully unsupervised, which means no STS training datasets are used and all embeddings are fixed once they are trained.
STS任务包括STS 2012- 2016(Agirre等人,2016)、STS基准(Cer等人,2017)和SICK-Relatedness(Marelli等人,2014)。所有的STS实验都是完全无监督的,这意味着没有使用STS训练数据集,所有的嵌入一旦训练完成就会被固定。
这里应该也补充了之前数据集那块的疑问,STS这边应该是没有用到train那块的,而且他是和SimCSE作对比,那SimCSE应该也是没有用
Transfer Task是各种感官分类任务,包括MR(Pang和Lee,2005)、CR(Hu和Liu,2004)、SUBJ(Pang和Lee,2004)、MPQA(Wiebe等,2005)、SST- 2(Socher等,2013)、TREC(Voorhees和Tice,2000)和MRPC(Dolan和Brockett,2005)。在这些Transfer Task中,我们将按照标准设置,使用在冻结的句子嵌入之上训练的逻辑回归分类器。
下游训练分类器,SentEval提供了一些默认设置,应该和那里对齐就可以
4.3 Results
4.3.1 Baselines
选用了一些baseline作为对比的
4.3.2 Semantic Textual Similarity(STS)
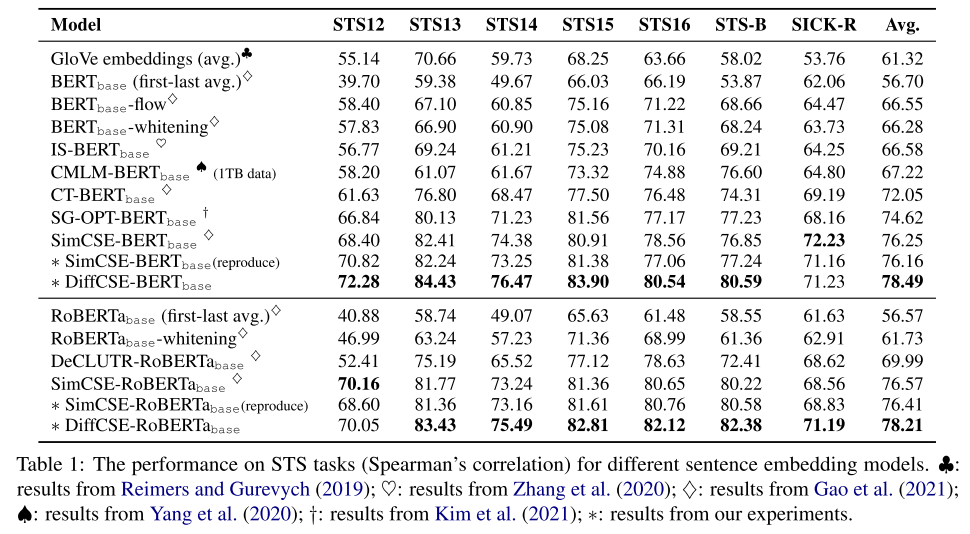
这里提供了一个SimCSE-reproduct的指标,应该是作者去跑了一下代码,从自己跑实验来说应该也是确实差一点能能到达SimCSE所宣称的指标
这个选择还挺tricky的,每项都比reproduce的好?
4.3.3 Transfer Tasks
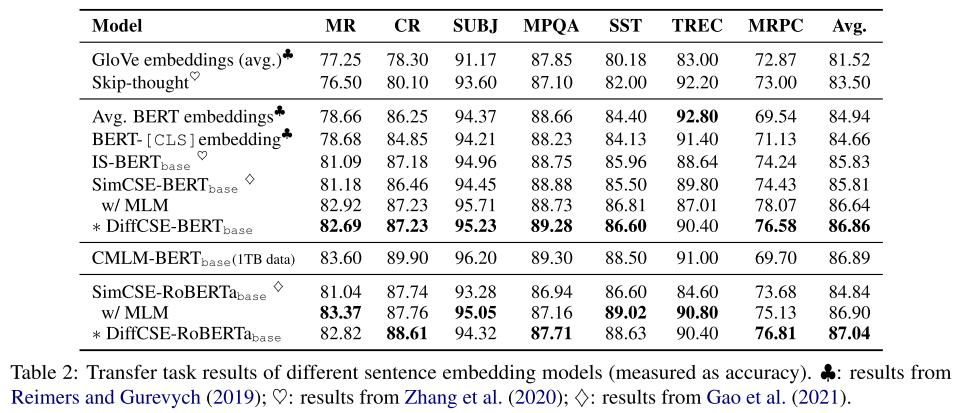
加上MLM作为训练目标后,会好一些?
Note that the CMLM-BERTbase (Yang et al., 2020) can achieve even better performance than DiffCSE. However, they use 1TB of the training data from Common Crawl dumps while our model only use 115MB of the Wikipedia data for pretraining. We put their scores in Table 2 for reference.
这个方法可能有些表现更好,但是用了很多额外的数据,而且这个数据规模是很大的;
In Sim- CSE, the authors propose to use MLM as an auxiliary task for the sentence encoder to further boost the performance of transfer tasks. Compared with the results of SimCSE with MLM, DiffCSE still can have a little improvement around 0.2%.
这里SimCSE原文是这么写的,没有放在正文里好像:

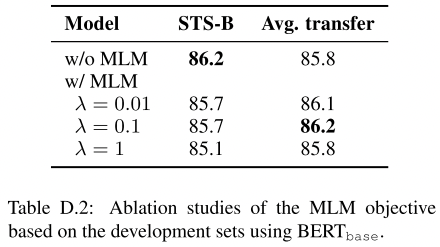
MLM在transfer任务中会更好?
5. Ablation Studies
我们进行了一系列广泛的消融研究,以支持我们的模型设计。我们使用BERTbase模型对STS-B的开发集和转移任务进行评估
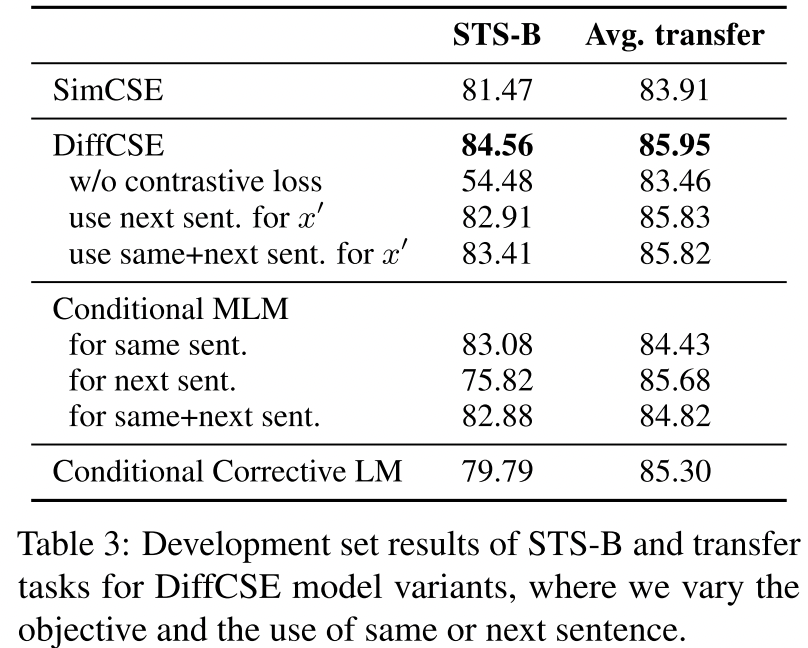
5.1 Removing Contrasitve Loss
This result shows that it is important to have insensitive and sensitive attributes that exist together in the representation space.
这一结果表明,在表示空间中,不敏感和敏感的属性一起存在是很重要的。
5.2 Next Sentence vs. Same Sentence
一些无监督句子嵌入的方法,如Quick-Thoughts(Logeswaran和Lee,2018)和CMLM(Yang等人,2020)预测下一句话作为训练目标。我们还体验了DiffCSE的一个变种,即根据下一句话来调节ELECTRA损失。请注意,这种模型不是在两个相似的句子之间进行 “差异操作”,也不是一个等价对比学习的实例。如表3所示(对x′使用下一个句子),STS-B的得分与DiffCSE相比明显下降,而转移性能仍然是相似的。
我们也尝试过同时使用同一个句子和下一个句子来调节ELECTRA目标(对x′使用同一个+下一个发送),但没有观察到改进。
不理解这里的next-sentence是怎么搞的
5.3 Other Conditional Pretraining Tasks
在右边那个架构使用其他的辅助任务,貌似效果不如现在这种MLM好;
5.4 Augumentation Methods: Insert/Delete/Replace
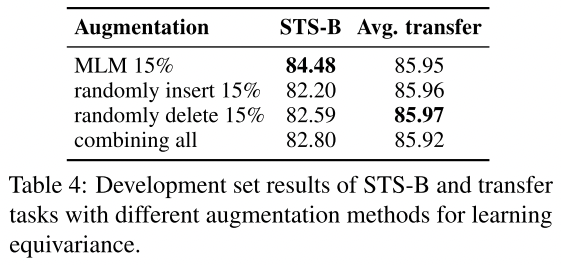
文字描述只解释了这个现象,但是好像没有解释为什么,从自己的感觉来说,那么如果是换成其他的了,我这个编码器输出的h还能够有那种作用吗?两边变化就比较大了?不过还是不太理解这个编码器h的作用;
5.5 Pooler Choice
在SimCSE中,作者使用BERT原始实现中的池器(一个带有tanh激活函数的线性层)作为最后一层,以提取特征来计算对比损失。在我们的实现中(详见附录A),我们发现使用带有批量归一化(Batch- Norm)(Ioffe和Szegedy,2015)的两层池器更好,这在计算机视觉的对比学习框架中常用(Chen等人,2020;Grill等人,2020;Chen和He,2021;华等人,2021)。我们在表5中显示了消融的结果。我们可以看到,添加BatchNorm有利于DiffCSE或SimCSE在STS-B和转移任务上获得更好的表现。
这里应该说的是那个MLP Layer的地方吧,要去对着代码看一下
5.6 Size of the Generator

Notice that although DistilBERTbase has only half the number of layers of BERT, it can retain 97% of BERT’s performance due to knowledge distillation
我们在表6中显示了我们的结果,我们可以看到Transfer task的性能在不同的generator中没有太大的变化。
然而,当我们从BERT-中型转换到BERT-小型时,STS-B的得分下降了。这一发现与ELECTRA不同,ELECTRA在生成器为判别器1/4-1/2大小时效果最好。因为我们的鉴别器是以句子向量为条件的,所以鉴别器将更容易执行RTD任务。因此,使用更强的生成器(BERTbase,DistilBERTbase)来增加RTD的难度将有助于鉴别器更好地学习。然而,当使用像BERTlarge这样的大型模型时,它可能是一个对判别器来说太有挑战性的任务。在我们的实验中,使用DistilBERTbase,它的能力接近但比BERTbase略差,给了我们最好的性能。
鉴别器是带有那个句子向量h作为条件的,所以鉴别器将更容易执行RTD任务。使用bert-base和distilBERT-base这种比medium、small大的作为generator,将更加有利于鉴别器的学习,因为其增加了RTD的难度….
但是当使用到large的时候,可能这个任务又太难了导致学不好,最后选用了distilbert
5.7 Masking Ratio

5.8 Coefficient $\lambda$(两边loss的平衡)

6. Analysis
6.1 定性研究
句子嵌入的一个非常普遍的应用的一个非常常见的应用是检索任务。这里我们展示了一些检索实例,以定性地解释为什么DiffCSE能比SimCSE表现更好。
使用STS-B测试集的2758个句子作为语料库,然后使用句子查询,通过计算余弦相似度来检索句子嵌入空间中的最近邻居。
我们在表9中显示了检索到的前3个例子。
第一个查询句子是 “你也可以这样做”。SimCSE模型检索到一个非常相似的句子,但其含义略有不同(”你也可以用它。”)作为排名第一的答案。相比之下,DiffCSE可以分辨出微小的差别,所以它检索出gt答案作为等级1的答案。
二个查询句子是 “这不是一个问题”。SimCSE检索到了一个意思相反但措辞非常相似的句子,而DiffCSE可以检索到措辞不太相似的正确答案。
我们还提供了第三个例子,SimCSE和DiffCSE都不能检索到一个使用双重否定的查询句子的正确答案。双重否定这里,有没有性能提升的一些创新思路?或者这几个case能不能和CLINE那边结合

6.2 Retrieval Task
除了定性研究,我们还展示了检索任务的定量结果。在这里,我们也使用STS-B测试集中的所有2758个句子作为语料库。在这个语料库中,有97个阳性对(从人类注释中得到5个语义相似度分数)。对于每个阳性对,我们用一个句子来检索另一个句子,看另一个句子是否在前1/5/10的排名中。检索任务的召回率@1/5/10见表10。我们可以看到,DiffCSE的召回率@1/5/10超过了SimCSE,显示了使用DiffCSE进行检索任务的有效性。

diffCSE使得检索更准了
6.3 Distribution of Sentence Embeddings
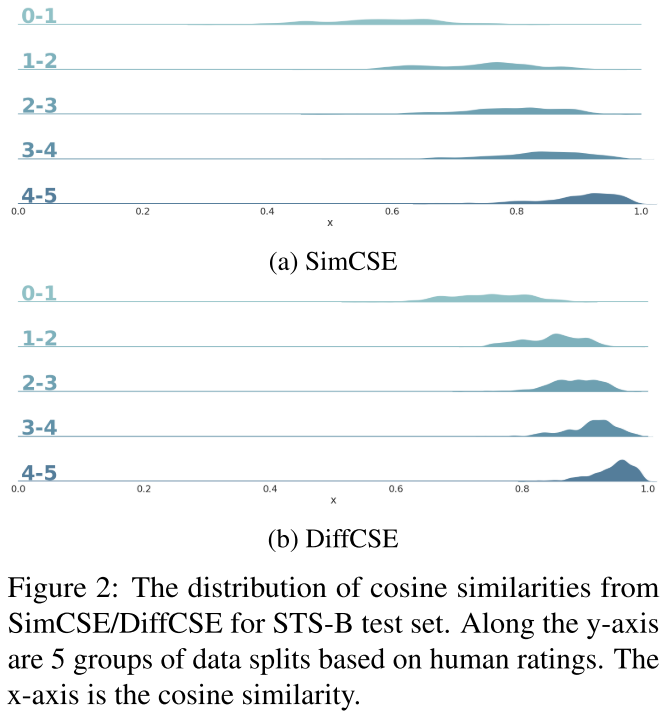
图2:STS-B测试集的SimCSE/DiffCSE的余弦相似度分布。沿着y轴是基于人类评分的5组数据分割。X轴是余弦相似度。
为了研究DiffCSE的表示空间,我们在图2中绘制了SimCSE和DiffCSE的STS-B测试集的感官相似度的余弦分布。我们观察到,SimCSE和DiffCSE都能分配与人类评分一致的余弦值。
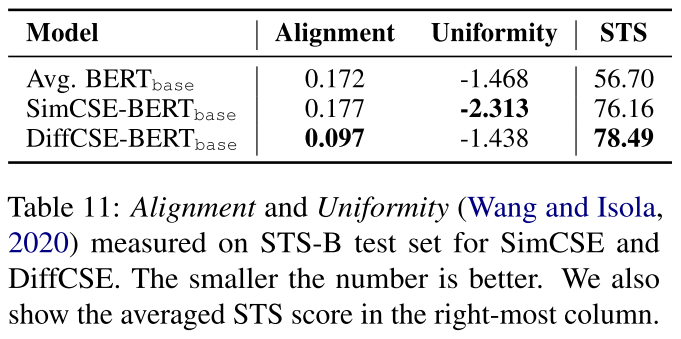
然而,我们也观察到,在相同的人类评分下,DiffCSE分配的余弦相似度比SimCSE略高。这一现象可能是由于ELECTRA和其他基Transformer的预训练语言模型有挤压表示空间的问题,正如Meng等人(2021)所提到的。由于我们使用句子嵌入作为ELECTRA的输入来进行有条件的ELECTRA训练,因此感性句子嵌入将不可避免地被挤压以适应ELECTRA的输入分布。我们遵循先前的研究(Wang and Isola, 2020; Gao et al., 2021),在表11中使用统一性和对齐性(详见附录C)来衡量DiffCSE和SimCSE的代表空间质量。与平均的BERT嵌入相比,Sim- CSE具有相似的对齐度(0.177对0.172),但均匀性更好(-2.313)。相比之下,DiffCSE的均匀性与Avg. BERT(-1.438 v.s. -1.468),但对齐度要好得多(0.097)。这表明SimCSE和DiffCSE在两个不同的方向上优化了表示空间。而DiffCSE的改进可能来自于它更好的对齐方式。
这里是一个从alignment 和 uniformity角度进行的分析;
7. Conclusion
在本文中,我们提出了DiffCSE,一个新的无监督的句子嵌入框架,它意识到了基于MLM的单词替换,但并没有对其产生影响。在语义文本相似性任务和转移任务上的实证结果都显示了DiffCSE与当前最先进的句子嵌入方法相比的有效性。我们还进行了广泛的消减研究,以证明DiffCSE的不同建模选择。定性研究和检索结果也表明,DiffCSE可以为句子检索提供一个更好的嵌入空间。我们工作的一个局限性是,我们没有探索使用人类标记的NLI数据集来进一步提高性能的监督环境。我们把这个话题留给未来的工作。我们相信,我们的工作可以为NLP社区的重新搜索者提供一种利用自然语言增强的新方法,从而产生更好的句子嵌入。
把NLI那些用上,提升检索上的一些,或者transfer任务上的?或者去CLINE那种数据集里搞
8. Coding角度
这里discriminator的,把那个h作为CLS的输入?
discriminator是这里:https://github.com/voidism/DiffCSE/blob/f724b2cc921efdfb4e4bd85cd7ca13a8f0d1f0cf/diffcse/models.py#L338
BERTmodel中的这里,他这个h的结合方式来看,
1 | |
这里就是把其中的cls给替换了,作为一个最初始的,虽然不知道为什么这样就能作用于他这个motivation吧
他这份代码也是在SimCSE基础上魔改的;
9.
