acl-short2021_SCD论文阅读整理
acl-short2021_SCD论文阅读整理
SCD: Self-Contrastive Decorrelation for Sentence Embeddings 句子嵌入的自对比去相关
个人总结文章亮点如下:
1)考虑到negative pair不好构造,或者说受到一些batch大小的限制,提出来自己过encoder两种不同dropout rate的方法,这两个之间的h(首次embedding那个地方的输出)要在一种相似度监视下远离,而过了projection layer后维度扩充,这些维度两个样本之间似乎又要在一个主对角线上接近一些?
2)一些指标写的是自己复现的指标,那么后期如果为了和他对比的话,可以用这个来对比?
Reference
- source code: https://github.com/SAP-samples/acl2022-self-contrastive-decorrelation/,看起来也是SimCSE直接修改过来的;
TODO-list
0. Abstract
在本文中,我们提出了自对比去相关(SCD),一种自监督方法。给定一个输入句子,它优化了联合自对比和去相关目标。
这个自对比可以理解,去相关(decorrelation)该怎么理解,可能还要看到method那个章节再看看
通过利用不同比率的标准dropout实例化所产生的对比学习来促进表征的学习。
所提出的方法在概念上是简单的,但在经验上是强大的。它在不使用contrasitive pair的情况下,在多个基准上取得了与最先进方法相当的结果。这项研究为高效的自我监督学习方法开辟了途径,这些方法比目前的对比性方法更加强大。
这里说的compareable performance,然后又说了efficient,所以要从效率这个方面做一些文章吗?
1. Introduction
% 第一段
表征的无监督学习(又称嵌入)是NLP中的一个基本问题,在文献中已经被广泛研究。句子嵌入对许多语言处理应用来说是必不可少的,如机器翻译、情感分析、信息检索和语义搜索。(不仅可以在STS上和别人拼,还可以看下游任务有哪些,然后在下游任务搞一些创新?) 最近,自监督的预训练方案已经成功地应用于Transformer架构的背景下,导致了自然语言处理和理解模式的改变。这里的想法是采用一个辅助任务,在训练期间强制执行一个额外的目标。通常情况下,这需要根据上下文的信息子集来进行预测。在实践中发现,大多数有效的目标是非常简单的。这些pretext task的一些成功例子是掩码语言模型(Masked Language Modeling,MLM)、下句预测(Next Sentence Prediction, NSP)、句子顺序预测(Sentence Order Prediction)等。
在处理无标签的数据的时候,对比学习是自监督方法中最强大的方法之一。对比性学习的目标是以这样一种方式学习一个嵌入空间,即类似的样本对(positive pair)保持彼此接近。同时,不相似的样本对(即负数对)被远远推开。为此,统一样本的不同扩增视图和不同的样本扩增视图被用作正负对(这里是在说SimCLR的内容) 。这些方法从视觉到文本表征学习的各种任务中显示出令人印象深刻的结果。
% 第二段
已经有多种不同的正负对选择技术被提出。举例来说:
DeCLUTR:将同一文件中的不同跨度作为positive pair;
CT:对来自两个不同编码器的同一句子的嵌入进行调整;
CERT:应用回译来创建原始句子的增强表示;
IS-BERT:使全局和局部特征之间的一致性最大化;
CLEAR:采用多种句子层面的增强策略来学习一个句子的表述;
尽管这些方法很简单,但他们需要仔细处理negative pair,依赖大的batch size或者复杂的记忆策略(sophisticated memory strategies)。其中包括memory bank或者定制的挖掘策略来有效的检索负数对。
特别是在NLP中,”hard negative mining“的努力在无监督的情况下变得特别具有挑战性。增加训练批次的大小或内存库的大小隐含地引入了更多的hard negative样本,同时也带来了大内存需求的沉重负担。
% 第三段
在本文中,我们介绍了SCD,一种用于自我监督学习的句子嵌入学习的新算法。与最先进的对比学习方法相比,SCD在基于句子相似性的任务方面取得了相当的性能,不采用,例如:明确的对比对。
相反,为了学习句子表征,所提出的方法对单一样本的增强所施加的自我对比。在这方面,该方法建立在对句子进行足够强的扰动以反应句子的语义变化这一想法之上。然而,目前还不清楚哪种扰动只是对句子进行了轻微的改动,而没有改变语义(positive pair),哪种扰动充分修改了语义,形成了一个负样本。这种模糊性表现在增强的样本同时具有负面和正面样本的特征(之前一些讨论时候感觉出来的,很难界定什么是negative 什么是 postiive,而且还有一些从句法层面来说的) 。
这里突然想到之前那个双重否定based那种方法,是一个更强的正例的感觉?
句法层面的相关性,减弱,而增强语义层面的相关性
为了适应这一点,我们提出了一个由两个对立项组成的目标函数,它作用与一个样本的增强pair:
i)自相背离(排斥)
ii)特征相关性(吸引)
第一个term将两个augmentation作为一个negative pair,推开不同的view;这怎么感觉和以前的base想法都不一样了,也可能这里augmentation是一些比较特殊的
与此相反的是,第二项关注的是作为positive pair的增量。因此,它最大限度的提高了同一特征在各视图中的相关性,学习了对增强的不变性;
考虑到目标的对立性,将他们整合到一个联合损失中会产生一个最小-最大优化方案。所提出的方案通过将表征学习的目标设定为吸引-排斥的权衡来避免退化的嵌入。同时,他还能学习改善表征的语义表达能力。
由于NLP中扩增的难度,所提出的方法是为批次中的每个样本“即时”产生扩增。为此,通过改变每个样本的dropout rate来产生多个数据增强;这里终于说到一些方法相关的内容,就是说对同一个样本不同的dropout rate
我们根据经验观察到,与成对的对比性方法相比,SCD对数据增强的选择更加稳健。我们认为,不依赖对比性的配对是主要原因之一,这一观察在自监督学习的文献中也有体现,与BYOL。虽然其他方法采取不同的增强或不同的模型副本,但我们利用了标准dropout的同一句子的不同输出。
% 第四段
与我们的论文最相关的是(SimCSE)。该论文考虑在对比学习的背景下使用dropout作为数据增强。我们的方法的一个关键创新点是,我们使用dropout来创建自我对比对,这可以作为正向和负向来使用。最后,我们注意到,我们的模型不同于成对的特征去重或whiting,后者鼓励在一个样本的增强视图之间进行类似的表示,同时尽量减少表示向量中的冗余度。与这些方法相比,一个关键的区别是,它们完全忽略了对比性目标。相比之下,我们的方法考虑到了这一点,并提供了将自相矛盾的观点同时作为正反两方面的手段。
% 第五段
Contribution被归纳为以下几点:
1)通过使用不同的dropout来生成句子嵌入;
2)消除对使用自我对比的负面对的依赖性;以前方法负面对不一定负面,而这里是一定负面?
3)为NLP中的非对比性自监督学习提出特征去重目标;
看完前面还没办法很get到这个motivation
2. Method
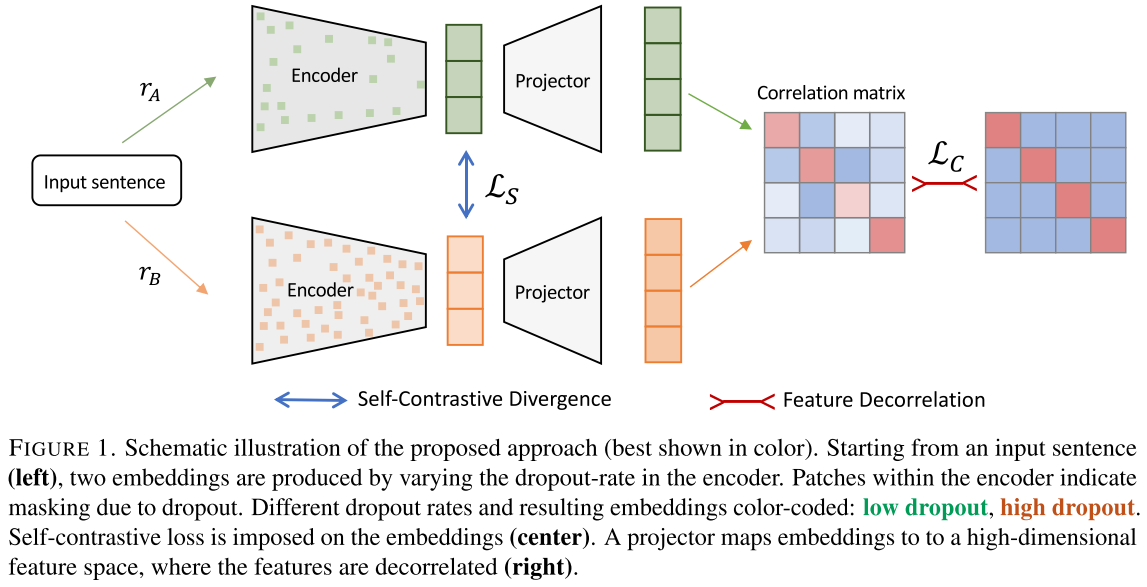
图1:提出方法的示意图(最好以彩色显示)。从一个输入句子(左)开始,通过改变编码器的dropout rate产生两个嵌入。编码器内的斑点表示由于dropout造成的mask。不同的dropout rate和由此产生的嵌入用颜色编码,绿色代表低rate的dropout,橙色代表高的dropout。自我对比的损失函数在embedding上进行(中间部分)。Projector将嵌入映射到一个高维的特征空间,其中的特征是去相关的(右)。和DiffCSE一样,我觉得很难大概了解到一个作者的motivation是什么
最右边是个理想情况,要让输出和理想情况比较接近
% 第一段
我们的方法依赖于生成样本的两个视图A和B。为此,在嵌入空间为批次$X$中的每个样本$x_i$生成增强。批次是由一个set的sample来创建的,$\mathcal{D}={(x_i)}{i=1}^{N}$,其中$ N $代表样本数。数据增强由encoder$f_\theta$完成,其中$\theta$代表参数。编码器的输出是$X$中样本的嵌入,表示为$H^{A}\in\tau$ and $H^{B}\in\tau$。其中$\tau$代表embedding空间。之后,我们使得$h_i\in\tau$表示句子的相关表示。于是,每个 样本产生的增强嵌入被表示为$h{i}^{A}$和$h_{i}^{B}$。
为了获取不同的嵌入,我们利用一个Transformer语言模型作为编码器,并结合不同的dropout rate。具体来说,一个augmentation基于较高的dropout rate,第一个augmentation基于较低的dropout rate。这就需要在编码阶段采用不同的随机掩码。随机掩码与不同的比率有关,$r_A$和$r_B$,其中$r_A<r_B$。将不同的dropout rate整合到编码器中,我们得到: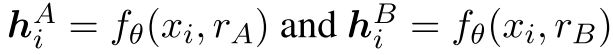
给定嵌入,我们利用联合损失,由两个目标组成:
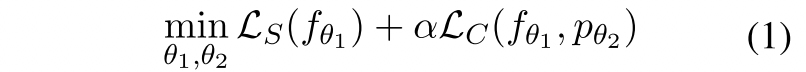
其中$\alpha \in R$代表一个超参数,$p$代表$\tau\rightarrow\mathcal{P}$是一个由参数$\theta_2$构成的projector MLP层。这里$|P|>>|\tau|$例如在embedding那个层输出是768,那么这里说后面远远大于前边,猜测后面是一个4096这样一个更大的? 。
- $\mathcal{L}S$的目标是增强嵌入的对比度,将嵌入$h{i}^{A}$和$h_{i}^{B}$推远。
- $\mathcal{L}_C$是为了减少冗余,并促进在高维空间中的增量的不变性。
这里能否从句法层面做一些理解,之前印象里那个句法层面的一些说法还是很有印象的
2.1 Self-Contrastive Divergence
自对比的差异化
自我对比试图在他不用dropout之间产生的embedding之间形成对比,因此$\mathcal{L}_s$由批次中的样本的余弦相似度组成,为:
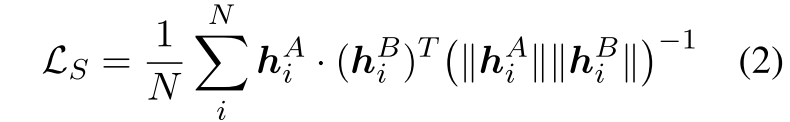
平均余弦相似度
越像,余弦相似度越大,那么loss越大是有问题的;;需要通过学习的梯度反向传播,让两个不同rate的dropout两者比较远离,这样两者余弦相似度更小,loss就越小了;;;
这里如果说问题的话:首先两个dropout的rate要控制吧,比如我虽然一个大一个小,但是比较接近的时候,我可以用SimCSE那样的,就是说把SimCSE那个结合进来;;但是两个比较远的时候,可以用现在这样的?
对比学习不一定
2.2 Feature Decorrelation
特征装饰关系
$\mathcal{L}_C$试图使嵌入不受增强的影响,同时减少特征中的冗余。为此,嵌入的$h_i$从$\mathcal{T}$向上投射到一个高维空间$\mathcal{P}$。其中进行了去相关性。
为了避免符号上的混乱,我们使得$p_{i}^{}=p(h_{i}^{})$,$*\in{A,B}$。表示应用$p(·)$投影后样本$x_i$的增强嵌入向量。然后从投影嵌入计算出一个相关矩阵。其条目$C_{j,k}$是:

求和里面是每个数据的,然后把32个加起来
其中$p_{i,j}^{*}\in R$,表示投影嵌入向量中的第j个分量。
这个公式在这里有些看不懂了,主要在于维度上,这里每个都是什么维度的?如果我认为$h_i$肯定是一个768这样维度的,比如说一个CLStoken,那么我是有i个样本的,每个样本的dim可以是一个4096这样一个更扩了高维的,我的Cjk是第j个样本,在第k个维度(4096中的一个)的一个相似度,暂时只能这么理解了?这个在每个维度(4096上)的相似度室友什么含义的表示吗?
这里我C的维度,看起来像是一个batch_size*4096,每个样本两种数据增强方法(不同dropout)上的在每个扩增维度$\mathcal{P}$上的相似度
那么,特征装饰相关的损失目标定义为:
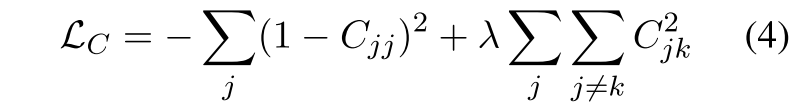
这里自己看公式的时候总觉得维度是对不上的,根据图里来说,我这个Cjk的维度应该是4096×4096的?也就是说我i(batch)那个维度,在前面已经求和过了,这里4096×4096的
从相似度来看,公式1,认为5% 和 15%反例;;;L_{C}是为了减小高维度的冗余并且促进不变性;;可能是不太关心非对角线,或者说非对角线元素比较多?
$\lambda$和4096是配套的
第一个term试图通过沿对角线的交叉相关最大化来实现变量的增加。
第二个term旨在通过最小化对角线以外的相关性来减少特征表示中的冗余度。
然后再结合图来尝试理解下这个式子:不清楚为什么前面这一项要加上负号,一些解释上说第一项通过最大化对角线互相关来增强不变性,而第二项最小化对角线之外的相关性来减少冗余;;;;;;很难理解为什么要这么做,另外这里的维护变化也很奇怪,i的维度在式子3上是怎么消掉的?
3. Experiments & Results
3.1 Traning Setup
从一个预训练的Transformer LM开始训练。使用HuggingFace中的Bert和Roberta。对于sentence representation,我们使用[CLS]token。相似于SimCSE的,我们从10^6数量级无监督的wikipedia数据集的数据进行训练。MLP那里输出应该是4096的;
两个dropout的比率大概是$r_{A}=5.0%$,$r_{B}=15.0%$。(BERT);$r_{A}=6.5%$,$r_{B}=24.0%$。(Roberta)
这些值是通过网格搜索得到的。首先,一个粗略的网格被放置在那里,α的步长为0.1,辍学率rA和rB为10%。对于λ,粗网格包括不同的大小{0.1, 0.01, 0.001}。其次,在一个细网格上,步长分别为0.01和1%。
3.2 Evaluation Setup
STS tasks and TransferTasks
3.3 Main Results
- STS
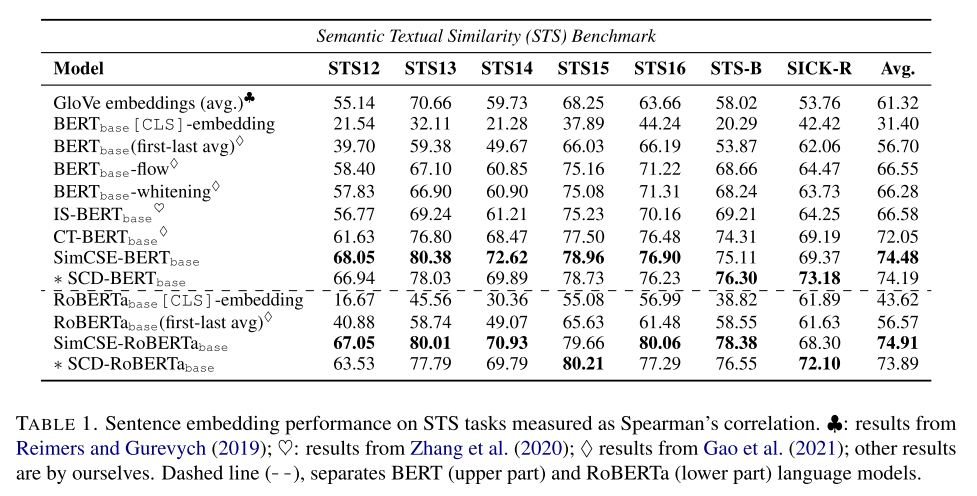
只在部分数据集上超过了别人,而且这个地方如果从evaluation的trick来说还是很多的,还有个地方是为什么这里引用的SimCSE的指标这么低啊,这个感觉也是有问题的?
- downstream transfer tasks
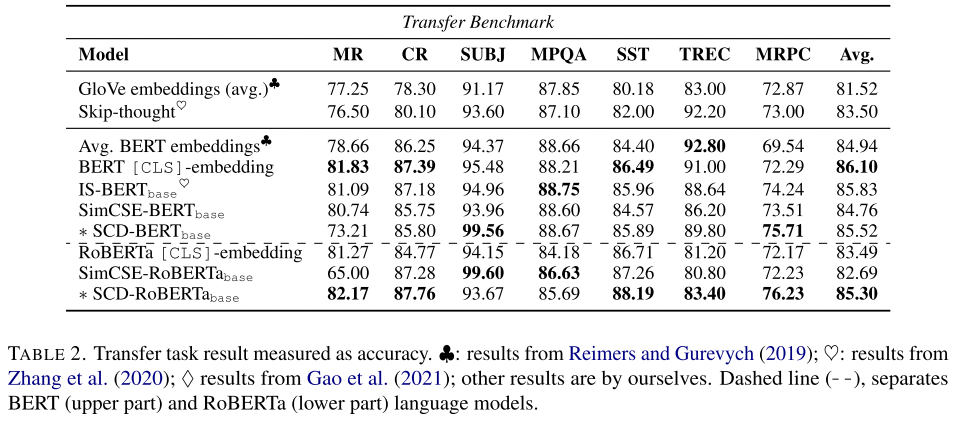
这这里也是,作者这个指标引的不太对啊,而且也不是一定比别人好。
要是在实验用对比的话,可以说指标是这里来的,或者reproduce和他这个指标差不多
3.4 Analysis
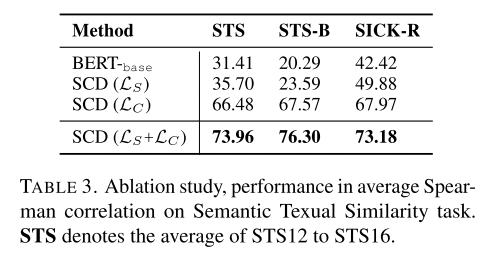
3.4.1 Ablation Study
这里似乎没说是验证集还是测试集,应该指的是测试集了
3.4.2 Uniformity and Alignment Analysis:
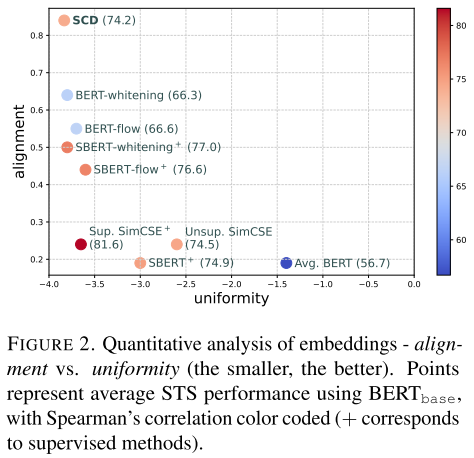
uniformity比较好,但是Alignment不太行
4. Conclusion & Future Work
我们提出了一种自我监督的表征学习方法,它利用了通过dropout获得的增强样本的自我对比度。尽管它很简单,但它在多个基准上取得了与先进技术相当的结果。未来的工作将涉及特定样本的增强,以改善嵌入,特别是表征的一致性。