acl2022_debiased(消除偏置)Contrasitve Learning
acl2022_debiased(消除偏置)Contrasitve Learning
Debiased Contrastive Learning of Unsupervised Sentence Representations
消除偏置的对比学习,用于无监督的句子表征
个人总结文章的亮点如下:
1)motivation是一个非常常见的motivation,就是说抽样得到的负例不一定很可靠,这样基于一个辅助模型搞个阈值判断,辅助模型用的SimCSE;
2)VAT的虚拟对抗训练方法扩充了一些样本,作为negative;
reference
TODO-list
- purple代表待讨论的;red代表自己批注;blue代表讨论中的记录
0. Abstract
近期,对比学习已被证明能有效的改善预训练语言模型(pretrained language models,prlm),从而获得高质量的句子表征。他的目标是拉近正面的例子以加强alignment,并推远不相关的负面例子以uniformity一整个表征空间。
之前还真没这么理解过,那就说明这个拉近正面的是一个alignment,推远负面的也就是之前接触到的一些各向同性可以把他说成一个uniformity
然而,以前的工作大多数采用批内的作为负样本或者是从训练数据中随机抽取。这样的方式可能会造成抽样偏差,即用不适当的否定词(eg:false negatives和各向异性表征)来学习句子表征,这将损害表征空间的均匀性。
这个问题感觉也是之前说过很多次的,就是in-batch不一定包含比较合理的,有些本身就可能是相似的,那我们其实不能把他们看做一个negative pair,例如两张狗图片的分别AB A’ B’数据增强
为了解决这个问题,我们提出DCLR框架(debiased contrastive learning of unsuperivised sentence representations,消除偏置的对比学习用于无监督的句子表征),以减轻这些不适当的负面因素的影响。在DLCR中,我们设计了一种实例加权方法来惩罚错误的否定,并生成基于噪声的否定,以保证表示空间的均匀性。
读到这里的话,实际上感觉和SimCSE那块那个新idea有些像?就是在loss这块权重上有一些做损失的感觉
在七个语义文本相似性任务上的实验表明,我们的方法比竞争基线更有效。我们的代码和数据可通过以下链接公开获取:
https://github.com/RUCAIBox/DCLR
1. Introduction
作为自然语言处理(NLP)领域的一项基本任务,无监督的句子表征学习旨在得出高质量的句子表征,以利于各种下游任务,特别是低资源领域或计算代价昂贵的任务,例如zero-shot文本语义匹配,大规模语义相似性比较,以及文档检索。
最近,预训练语言模型(BERT等)已经成为一种广泛使用的语义表示方法,在各种NLP任务上取得了显著的性能。然而,一些研究发现,PLM得出的句子原生句子表征在方向上并不是均匀分布的,而是在向量空间中占据一个狭窄的锥体,这在很大程度上限制了其表达能力。这里说的就是存在的各向异性问题
为了解决这个问题,对比学习已经被采用来完善PLM衍生的句子表征。他将语义上接近的邻居拉到一起以提升alignment,同时将非邻居推开以提升表征空间的uniformity。
如果为别人介绍对比学习任务的时候,可以用这段introduction,感觉这个是读到比较清楚的了,而且涵盖了很多之前的方面
在学习的过程中,positive和negative的例子都涉及到和原句的对比。对于正面例子,以前的工作在原始句子上应用数据增强策略以产生高度相似的变化。而负面例子通常是从batch或训练数据中随机抽取的,由于负面例子缺乏ground truth的注释。
这里读到motivation的时候,感觉也是相对有一些和SimCSE扩展的相似性
虽然这样的负向抽样方式简单方便,但是可能会造成抽样偏差(sampling bias),影响句子的表征学习。
- 首先,取样的否定句很可能是假否定句,他们在语义上与原句接近。如图1中所示的,根据SimCSE模型,在给定的输入句子中,约有一半的in-batch否定句子与原句的余弦相似度超过0.7。它很可能通过简单地推开这些取样的否定词来伤害句子表征的语义。这里是不是这样的一个逻辑,就是说我确实要推远和负例之间的距离,但是说余弦相似度这么高的,那可能本来就不能算做负例了
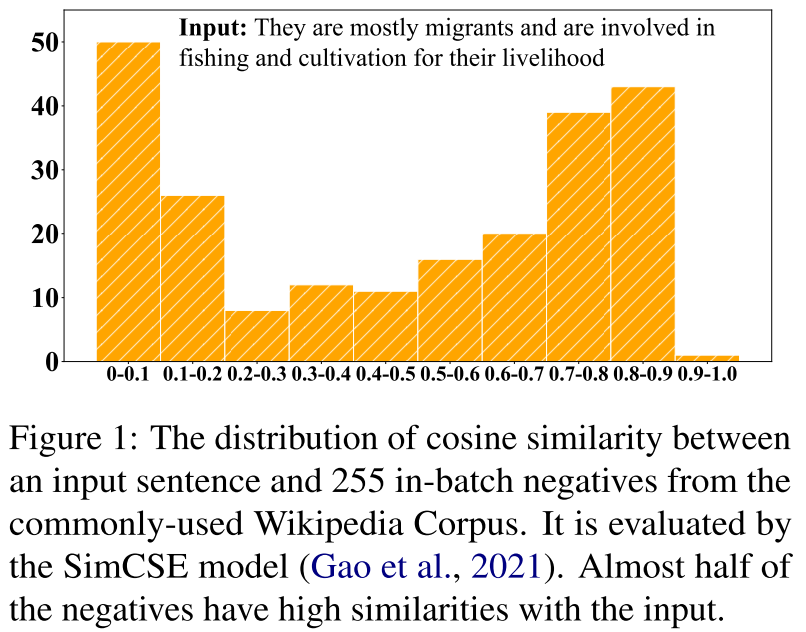
图1:一个输入句子和255个来自常用维基百科语料库的批量内否定句之间的余弦相似度分布。它由SimCSE模型进行评估。几乎一半的否定句与输入句有很高的语义相似性。
- 其次,由于各向异性问题(Ethayarajh,2019),采样的否定词的表征来自PLMs所跨越的狭窄表征锥,不能完全反映表征空间的整体语义
- 因此,只依靠这些表征来学习句子表征的统一性目标是次优的。
为了解决上述问题,我们旨在开发一种更好的对比学习方法,采用去偏的负向抽样策略。核心思想是改进随机负向抽样策略,以缓解抽样偏差问题。
首先:在我们的框架中,我们设计了一个实例加权方法,以惩罚在训练过程中抽样的虚假否定句。我们采用了一个补充模型来评估每个否定句与原句之间的相似性,然后为相似性较高的否定句分配较低的权重。通过这种方式,我们可以检测出语义上接近的假否定句,并进一步减少其影响。**这里是不是真的很接近啊,新的motivation来说,就是从权重设置加权上,去掉那一项会不会本质就是个加权这样的,那比如分母不含h1_1, h1_2,就是一个较小的权值**
其次,我们基于随机高斯噪音随机初始化新的否定词,以模拟整个语义空间内的抽样,并设计了一种基于梯度的算法,将基于噪音的否定词向最不均匀的点优化。通过学习与非均匀的基于噪声的否定词进行对比,我们可以扩展句子表征的占用空间,并提高表征空间的均匀性。
为此,我们提出了DCLR,一个针对无监督的句子表征的去偏对比学习通用框架:
- 在我们的方法中,我们首先从高斯分布中初始化基于噪声的否定词,并利用基于梯度的算法,通过考虑表示空间的均匀性来更新新的否定词;
- 然后,我们采用互补模型来产生这些基于噪声的否定句和随机抽样的否定句的权重,其中错误的否定句将受到惩罚;
- 最后,我们通过dropout(SimCSE)来增加正面的例子,并将它们与上述加权的负面例子结合起来,进行对比学习;
我们证明,我们的DCLR在七个语义文本相似性(STS)任务上,使用BERT和RoBERTa,优于一些竞争基准。
我们的贡献被归纳为以下几点:
(1)据我们所知,我们的方法是第一次尝试在无监督的句子表征的对比学习中减少采样偏差。
(2)我们提出了DCLR,这是一个去偏化的对比学习框架,它包含了一个实例加权方法来惩罚错误的否定,并生成基于噪声的否定来保证表示空间的统一性。
(3)七项语义文本相似性任务的实验结果显示了我们框架的有效性
2. Related Work
在本节中,我们从以下三个方面回顾相关工作。
2.1 Sentence Representation Learning
暂时略过了
2.2 Contrastive Learning
暂时略过了
2.3 Virtual Adversarial Traning
虚拟对抗训练(VAT)用可学习的噪声对给定的输入进行扰动,以使模型的预测与原始标签的分歧最大化,然后利用扰动的例子来提高泛化能力。**一类虚拟对抗训练方法可以被表述为解决一个最小-最大问题,这可以通过多个投影梯度上升步骤实现(Qin et al., 2019)**。这篇会不会之后还可以看看,听起来像是比较通用的方法
这个地方其实不是很看的懂,原文的表示是这样:Virtual adversarial training (VAT) perturbs a given input with learnable noises to maximize the divergence of the model’s prediction with the original label, then utilizes the perturbed examples to improve the generalization
在NLP领域,一些研究在嵌入层中进行对抗性扰动,并显示其在文本分类(Miyato等人,2017)、机器翻译(Sun等人,2020)和自然语言理解(Jiang等人,2020)任务上的有效性。
3. Preliminary
还是很少看到这个章节的出现,作为一种预先说明的知识,不占用approach部分的篇幅?
这项工作的目的是利用无标签语料库学习有效的句子表征,这些表征可以直接用于下游任务,如语义文本相似性任务。给定一组输入语句$X={x_1,x_2,…,x_n}$,目标是在无监督的情况下为每个$x_i$学习表征$h_i\in R^d$。为了简单起见,我们用一个参数化的函数来表示这个过程$h_i=f(x_i)$
在这项工作中,我们主要关注使用基于BERT的PLMs来生成句子表征。按照现有的工作,我们通过我们提出的无监督学习方法在未标记的语料库上微调PLM。之后,对每个句子$x_i$,我们用微调的PLM进行编码,并将最后一层的[CLS]标记的表示作为其句子表示$h_i$
这篇文章感觉很适合作为一个入口给别人介绍CL这个任务,他能指向很多地方
4. Approach
我们提出的DCLR框架侧重于减少句子表征的对比学习中采样偏差的影响。
在这个框架中,我们设计了一个基于噪声的负数生成策略,以减少各向异性PLM衍生的表征所造成的偏差,以及一个实例加权方法,以减少虚假negative造成的偏差。一方面生成negative,一方面把原来的伪hard-negative拉近
具体来说,我们根据高斯分布初始化基于噪声的negative,并迭代更新这些negative以达到非均匀性最大化。然后,我们利用一个互补模型为所有的negative(即随机抽样的和基于噪声的negative)产生权重。最后,我们将加权的negative和增强的positive结合起来进行对比学习。
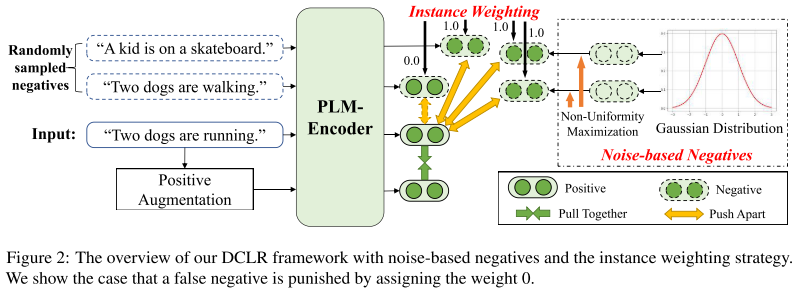
图2自己理解:输入一句话“Two dogs are runing”,而随机采样到了两句话“Two dogs are walking”,“A kid is on a skateboard”,其中“Two dogs are walking”这句话和原来那句话明显还是有一定相似的,在推远这两个的过程中我们要把他们的权值设置成0。往下走的positive augumentation可以是SimCSE的这样一个dropout再来一次,此外还用高斯分布最大化不同生成了一些Noise-based Negatives
4.1 Generating Noise-based Negatives
生成基于噪声的negatives
我们的目标是在训练过程中,在PLM的句子表示空间之外产生新的否定词,以缓解PLM的各向异性带来的抽样偏差。
对于每个输入句子xi,我们首先从高斯分布中初始化k个噪声向量作为负向表示:
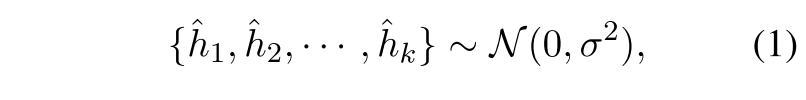
其中$\sigma$是标准差。由于这些向量是从这样的高斯分布中随机初始化的,因此他们在整个语义空间中是均匀分布的。通过学习与这些新的否定词进行对比。通过学习与这些新的否定词进行对比,有助于句子表述的统一性。这个有点不明白,他随机了这些,就认为这些随机的和什么都没关系作为negative,那么随机的这些在数量量级上,会和之前是一样的吗?
为了进一步提高否定词的质量,我们考虑迭代更新否定词,以捕捉整个语义空间内的非均匀性点。受到VAT(虚拟对抗训练)的启发,我们设计了一个非均匀性损失最大化的目标,以产生梯度来改善这些negative。非均匀性损失被表示为基于噪声的否定词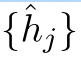 之间的对比性损失:(拉近正例h_i和h_i+,推远负例h_i和^h_i)
之间的对比性损失:(拉近正例h_i和h_i+,推远负例h_i和^h_i)
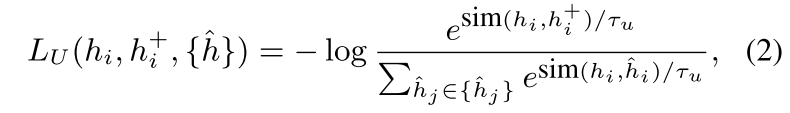
感觉对这个式子的理解还不是很到位,他这个分母看起来就像是不包含分子那一项了,那么拉近正例可能是一个拉近自己和自己另外一种dropout这样的方式,推远负例在这个式子中似乎只表示出来了推远和Noise-based Negatives的那一项,而还不涉及到和randomly sampled negatives之间的推远
其中$\tau_{u}$是温度常数,sim相似度使用的是余弦相似度。在此基础上,对于每个negative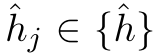 ,我们通过t步梯度上升法对其进行优化,即:
,我们通过t步梯度上升法对其进行优化,即:
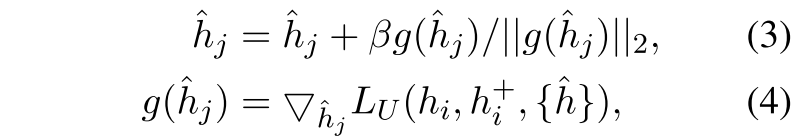
其中$\beta$是学习率,$||·||$是二范数,$g(\hat{h}_j)$表示$\hat{h}_j$的梯度,通过最大化正反馈和基于噪声的负反馈之间的非均匀性损失来实现(by maximizing the non-uniformity loss between the positive rep- resentations and the noise-based negatives)。
这样一来,基于噪音的否定词将被优化到句子表征空间的非均匀点。通过学习与这些否定词的对比,可以进一步提高表示空间的均匀性,这对有效的句子表示至关重要。最大化这个损失,然后来做梯度上升?我最开始初始化的否定词那么是一个各项同性的一个很均匀的分布,他们将被优化到句子表征空间中的非均匀点,进一步把这些用作否定词对比,怎么来提升表示空间的均匀性?
这里完全是一个Virtual adversarial training的过程,感觉自己对这个了解还不是很到位,正好顺着这里了解一下,https://zhuanlan.zhihu.com/p/549605526?utm_source=wechat_session&utm_medium=social&utm_oi=677587051885629440&utm_campaign=shareopn
4.2 Contrastive Learning with Instance Weighting
基于实例加权的对比学习,除了上述基于噪声的否定词,我们还遵循现有的工作),采用其他batch内表示作为否定词${\tilde{h}^{-}}$。正如前面讨论的,抽样的否定句可能包含与positive instance有相似语义的例子(举例:false negatives)
这个问题其实早就有所注意到,这么抽样的时候必将带来这样的问题,那么前面读过的大多数论文好像还真没有从这个方面来进行解决的,另外之前那篇token-aware的文章,这个问题如果能解决的话应该会能够更好的提升吧

为了缓解这个问题,我们提出了一种实例加权的方法来惩罚false-negative。由于我们无法获得真实的标签或语义相似性,我们利用一个补充模型(complementary model)来产生每个负数的权重。在本文中,我们采用最先进的SimCSE作为补充模型。从${\tilde{h}^{-}}$或者${\hat{h}}$中给定一个negative表征$h^{-}$,以及原始的句向量表征$h_i$,我们利用补充模型产生的权重为:
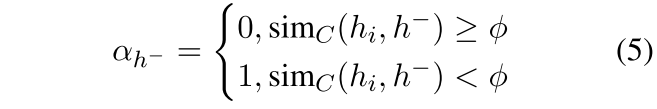
其中$\phi$是一个实例阈值超参数,$sim_C(h_i,h^{-})$是由互补模型评估的余弦相似度得分。这样一来,与原句表征有较高语义相似性的否定句将被视为假否定句,并将被赋予0的权重进行惩罚。
这个方法听起来还是相当合理的,不知道为什么之前的论文好像在这里操作较少,另外这个方法用在token级别上会不会很有用啊?
在权重的基础上,我们用一个去中心化的交叉熵对比学习损失函数来优化句子表征,即:
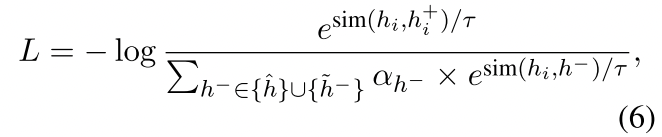
这个分母也是不包含正向的,他这个好像从各种motivation上都很像
其中τ是一个温度超参数。在我们的框架中,我们遵循SimCSE的做法,即利用dropout来增加正面的例子$h_{i}^{+}$。实际上,我们可以利用各种积极的增强策略,并将在第6.1节中对其进行研究。
BERT的表征依赖句法层面,特别长的句子只有一个词不一样,大概率他们的Similarity是非常接近的->但也有可能是hard-negative,有可能就筛掉了一批hard-negative
4.3 Overview and Discussion
在这一部分,我们介绍了我们的DCLR方法的概述和讨论
4.3.1 Overview of DCLR
我们的框架DCLR包含三个主要步骤。
1)我们生成基于噪声的negative来扩展batch内的negative。具体来说,我们首先使用通过随机的高斯噪音来初始化一组新的negative信息,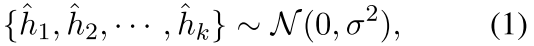 。然后,我们加入了一个基于梯度的算法,通过使用
。然后,我们加入了一个基于梯度的算法,通过使用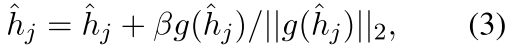 使非均匀目标最大化来调整基于噪声的否定。经过几次迭代,我们可以得到与整个语义空间内的非均匀点相对应的基于噪声的否定词,并将它们与批量内的否定词混合起来,组成否定词集。
使非均匀目标最大化来调整基于噪声的否定。经过几次迭代,我们可以得到与整个语义空间内的非均匀点相对应的基于噪声的否定词,并将它们与批量内的否定词混合起来,组成否定词集。
2)我们采用一个补充模型(即SimCSE)来计算原始句子和负数集的每个例子之间的语义相似度,并使用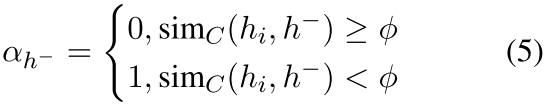 产生权重。
产生权重。
这个阈值设置还是很高的,0.85 0.9这个级别
3)最后,我们通过dropout来增加正面的例子,并利用负面的例子和相应的权重来进行对比学习,使用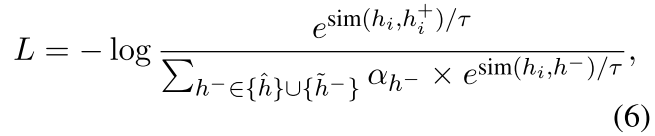 。
。
4.3.2 Discussion
如上所述,我们的方法旨在减少关于negative的抽样偏差的影响,并且与各种积极的数据增强方法(例如,token cutoff和dropout)无关。这里会不会在说这些是能够同时作用的 与传统的对比学习方法相比,我们提出的DCLR通过引入基于噪声的否定词来扩展否定词集,并增加一个权重项来惩罚虚假否定词。由于基于噪声的否定词是从高斯分布中初始化的,并不对应于真实的句子,因此它们是高度自信的否定词,可以扩大表示空间。通过学习与它们进行对比,对比性目标的学习将不会受到来自PLM的各向异性表征的限制。因此,句子表征可以跨越更广泛的语义空间,表征语义空间的统一性(uniformity)也可以得到改善。
此外,我们的实例加权方法也缓解了随机抽样策略造成的false negative问题。在补充模型的帮助下,那些与原句语义相似的false negative句子将被检测出来并受到惩罚。
5. Experiments - Main Results
5.1 Experiment Setup
追随之前的工作,我们在7个文本语义相似度(Semantic Textual Similarity,STS)任务上测试我们的性能。对于所有的工作,我们使用SentEval tookit用于evaluation;
Semantic Textual Similarity Task. We evaluate our approach on 7 STS tasks: STS 2012–2016, STS Benchmark and SICK-Relatedness. 这些数据集包含成对的两个句子,其相似性分数被标记为0到5。golden annotations和句子表征预测的score之间的相关性由Spearman关联度来衡量。根据以前工作的建议,我们直接计算所有STS任务的句子嵌入之间的余弦相似度。
Baseline Methods: 一系列非BERT和基于BERT的方法,其中BERT那个还探讨了[CLS] mean first-last AVG的方法
implementation details: Huggingface’s transformers;
- BERT-base and RoBERTa-base:start from the pre-trained checkpoints of their original papers;
- BERT-large and RoBERTa- large:utilize the checkpoints of SimCSE for stabilizing the convergence process
Following SimCSE,我们使用从维基百科中随机抽取的1,000,000个句子作为训练语料。……
5.2 Main Results
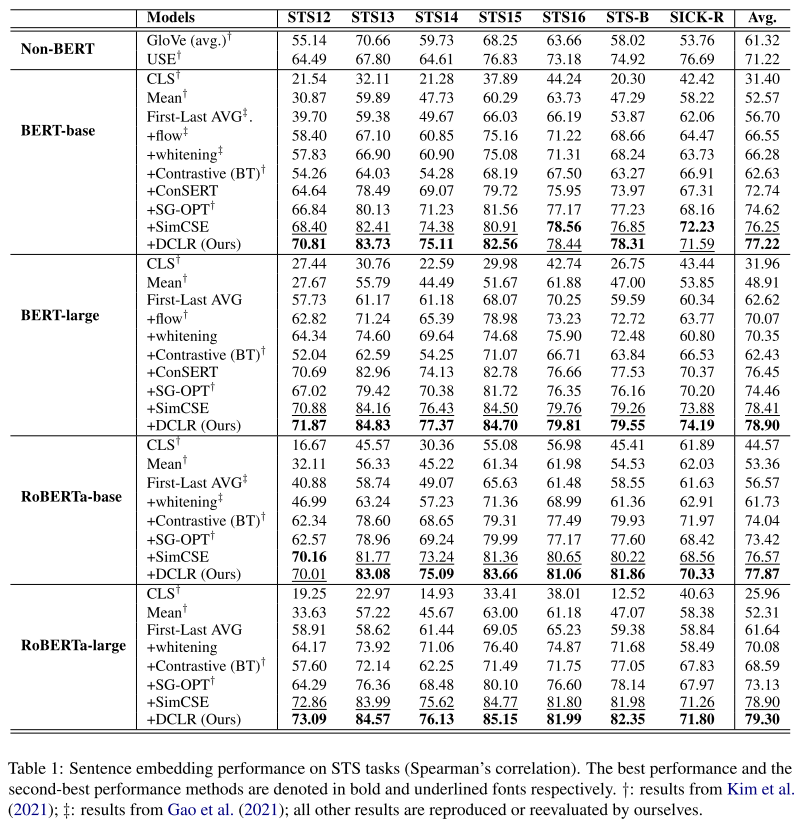
在large的上满指标上升好像不明显
为了验证我们的框架在PLM上的有效性,我们选择BERT-base和RoBERTa-base作为基础模型。表1显示不同方法七个STS任务上的结果。根据结果,我们可以发现,非BERT方法(即GloVe和USE)的表现大多优于基于PLM表示法的本地基线(i.e., CLS Mean and First-Last AVG)BERT这边说的是CLS直接用那种吧,直接用基本性能就直接崩了 。原因是,直接利用PLM的原始表征很容易受到各向异性的影响。在非BERT方法中,USE的表现优于Glove。一个潜在的原因是USE使用Transformer模型对句子进行编码,这比简单的平均GloVe embeddings更有效。
对于其他基于PLM的方法,首先,我们可以看到flow和whiteening取得了类似的结果,并以一定的幅度超过了基于原始表征的方法。这两种方法采用特定的改进策略来完善PLM的表征。第二,基于对比学习的方法在大多数情况下优于其他基线。对比学习可以提高语义相关的positive pair之间的一致性和使用阴性样本的表示空间的统一性,从而获得更好的句子表示。此外,SimCSE在所有基线中表现最好。这表明dropout是一种比其他方法更有效的正向增强方法,因为它很少伤害到句子的语义。
最后,DCLR在大多数情况下比所有的基线表现得更好,包括基于对比学习的方法。由于这些方法大多利用随机抽样的否定句(如批内否定句)来学习所有句子表征的统一性,它可能导致抽样偏差,如虚假否定句和各向异性表征。与这些方法不同的是,我们的框架采用了一种实例加权的方法来惩罚错误的否定,并采用一种基于梯度的算法来生成基于噪声的否定,向非均匀性的点倾斜。这样一来,采样偏差问题可以得到缓解,我们的模型可以更好地学习均匀性,以提高句子表征的质量。又强调了一下motivation,这里感觉还是挺合理的,本来在抽样的时候就可能会有这样的问题
6. Experiment - Analysis and Extension
在本节中,我们将继续研究我们提出的DCLR的有效性。
6.1 Debiased Contrastive Learning on Other Methods
由于我们提出的DCLR是一个通用框架,主要侧重于无监督句子表征的对比学习的负向采样,它可以应用于其他依靠不同的正向数据增强策略的方法。因此,在这一部分,我们进行了实验,以检验我们的框架是否能通过以下积极的数据增强策略带来改进:
(1)Token Shuffling 随机把输入序列中的tokens shuffle;
(2)Feature/Token/Span Cutoff 随机删除输入中的特征/token/span;
(3)Dropout 类似于SimCSE,请注意,我们只修改了消极的采样策略,以实现我们的DCLR的这些变体;
他是一个在负例那边做文章比较多的,那么可以与其他从正向那边的工作来结合
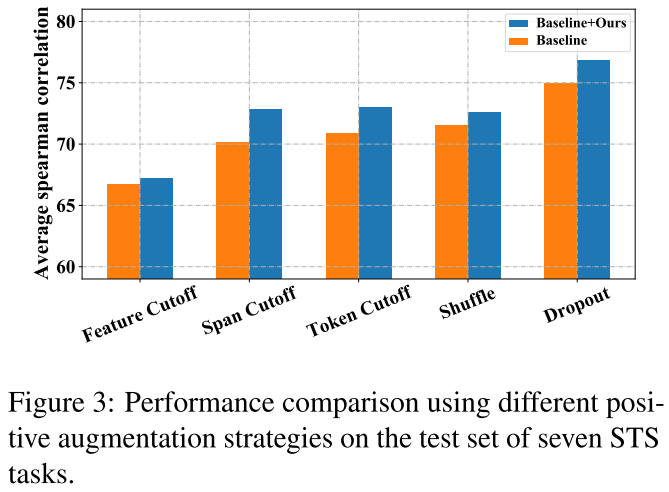
如图3所示,我们的DCLR可以提高所有这些增强策略的性能,它显示了我们的框架与各种增强策略的有效性。此外,在所有的变体中,Dropout策略导致了最好的性能。这表明Dropout是一种更有效的增强高质量positive的方法,也更适合于我们的方法。
这个是一定的吧,或者说他尝试了一下与别人结合,一边positive做文章,一边negative做文章
6.2 Ablation Study
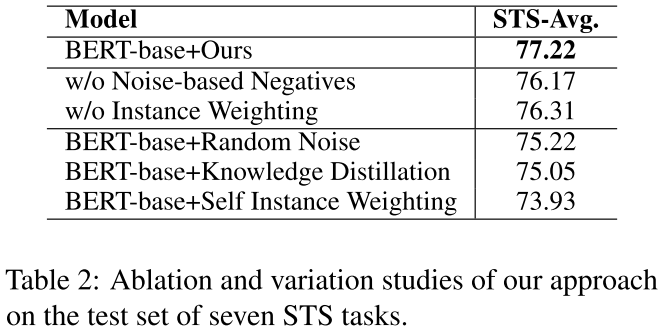
我们提出的DCLR结合了实例加权方法来惩罚错误的否定,还利用了基于噪音的否定来提高整个句子表示空间的统一性。为了验证它们的有效性,我们对七个STS任务中的两个组件分别进行了消减研究,并报告了Spearman相关度的平均值。如表2所示,去除每个组件都会导致性能下降。这表明实例加权法和基于噪声的否定句在我们的框架中都很重要。此外,去除实例加权方法会导致更大的性能下降。原因可能是错误的负面因素对句子表示学习有较大的影响。
这里是不是表格还是话写错了,看起来w/o Noise-based Negative性能下降更大一点?
此外,我们还准备了三种变体供进一步比较。
(1)Random Noise:直接生成基于噪声的negative,不需要基于梯度的优化;
(2)Knowledge Distillation(知识蒸馏):利用SimCSE作为教师模型,在培训期间将知识提炼到学生模型中。
(3)SelfInstance Weighting:采用模型本身作为补充模型来生成权重
从表2中,我们可以看到这些变化的表现不如原始的DCLR。这些结果表明第4节中提出的设计更适合我们的DCLR框架。
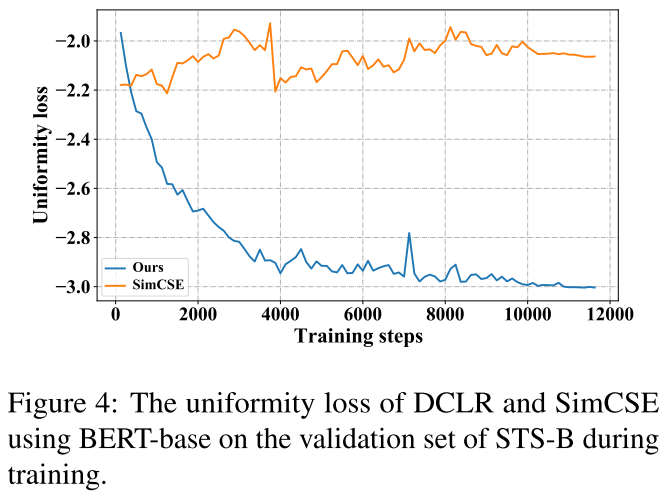
6.3 Uniformity Analysis
省略一些理论的部分
如图4所示,几乎在整个训练过程中,DCLR的均匀性损失要比SimCSE的低得多。此外,我们可以看到,随着训练的进行,DCLR的均匀性损失下降得更快,而SimCSE的均匀性损失则没有明显的下降趋势。这可能是因为我们的DCLR在表示空间之外对基于噪声的否定句进行了采样,这可以更好地提高句子表示的均匀性。
6.4 Performance under Few-shot Settings
为了验证DCLR在数据稀缺情况下的可靠性和稳健性,我们使用BERT-base作为骨干模型进行了少量实验。我们通过从100%到极小规模(即0.3%)的不同数量的可用训练数据训练我们的模型。我们报告了对STS-B和SICK-R任务的评估结果。
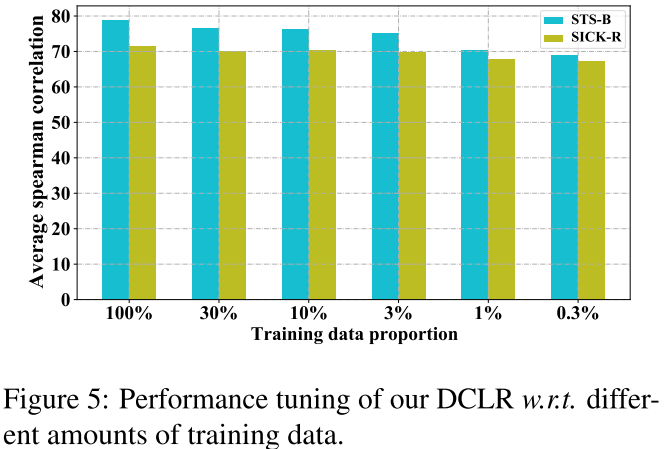
如图5所示,我们的方法在不同比例的训练数据下取得了 在不同比例的训练数据下取得了稳定的结果。在数据比例为0.3%的最极端情况下,我们的模型在STS-B和SICK-R上的性能分别只下降了9%和4%。这些结果揭示了我们的方法在数据稀缺的情况下的稳健性和有效性。这种特性在现实世界的应用中是很重要的。
6.5 Hyper-parameters Analysis
对于超参数分析,我们研究了实例加权阈值$\phi$和基于噪声的阴性体的比例k的影响。这两个超参数在我们的框架中都很重要。具体来说,我们在STS-B和SICK-R任务中使用BERT-基础模型,用不同的$\phi$和k的值来评估我们的模型。
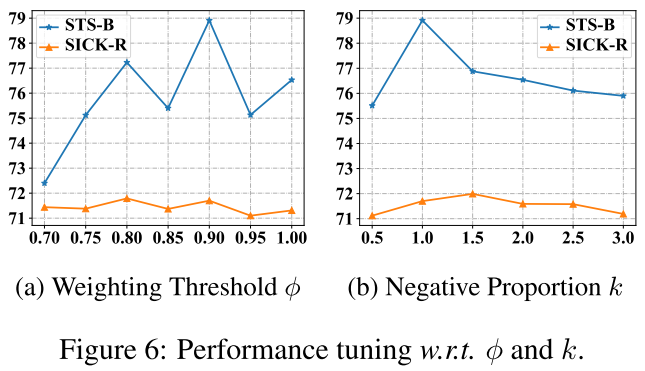
- Weighting threshold:
图6(a)显示了实例加权阈值$\phi$的影响。对于STS-B任务,$\phi$对模型性能有很大影响。过大或过小的$\phi$都可能导致性能下降。原因是较大的阈值不能实现有效的惩罚,而较小的阈值可能会导致对真否定的误判。相反,SICK-R对$\phi$的变化不敏感。原因可能是在这个任务中,假阴性的问题并不严重。
- Negative proportion:
当基于噪声的否定词的数量接近批量大小时,我们的DCLR表现得更好。在这种情况下,基于噪声的否定词更能够增强整个语义空间的统一性,而不损害对齐性,这也是DCLR表现良好的关键原因。
7. Conclusion
在本文中,我们提出了DCLR,一个用于无监督的句子表征学习的去中心化的对比学习框架。我们的核心思想是缓解由随机负向抽样策略引起的抽样偏差。为了实现这一目标,在我们的框架中,我们采用了一种实例加权的方法来惩罚训练过程中的错误否定,并产生了基于噪声的否定,以减轻各向异性的PLM衍生的代表的影响。在七个STS任务上的实验结果表明,我们的方法优于几个有竞争力的基线
在未来,我们将探索其他方法 来减少句子表征的对比性学习中的偏差(例如,debaised的预训练)。此外,我们还将考虑将我们的方法用于多语言或多模态表征学习。