Contrastive Learning 论文整理
Contrastive Learning 论文整理
1. A Simple Framework for Contrastive Learning of Visual Representations
1.1 简介&总结
SimCLR,对比学习开创性的工作,是一种无监督(或者称为自监督的)的方法通过一张图片的两种数据增强方法之间互为正例,在一个batch批次为N的数据中,通过两种数据增强方法构建2N个例子,那么每个i会与其它2N-2个互为负例,这样通过infoNCE损失函数完成拉近正样本,推远负样本。注意这里引入了projection head将隐层表征$h_i$线性变换后的$g_i$用来计算对比损失,但是在使用表征的时候仍然使用$h_i$;
1.2 算法实现过程
- Figure2:A simple framework for contrastive learning of visual representations

一个样本$x$经过两种数据增强方法生成$\tilde{x}_i$和$\tilde{x}_j$(例如计算机视觉中常用的裁剪,旋转等等);
他们经过同样的$f(·)$层线性学习提取得到图像的特征(这里一般是ResNet类的Encoder的特征提取结构,对应到NLP就一般是一个BERT类的Transformer-Encoder架构),得到的图像表征是$h_i$和$h_j$;
将图像表征$h_i$和$h_j$通过projection head $g(·)$层,得到表征$z_i$和$z_j$;
通过InfoNCE等函数拉近positive pair之间的距离,推远negative pair之间的距离(注意这里分母不包含h1_1、h1_1这一项自己到的自己的,但是包含正例之间的h1_1、h1_2这一项);
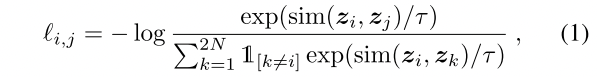
- 在使用表征进行下游任务的时候,使用$f(·)$而丢弃$g(·)$
- Algorithm1:summarizes the proposed method

- 对于一个batch大小为N的数据批次,指定温度常数$\tau$,以及数据增强方法$T$、encoder结构$f$,projection head结构$g$;
- 把batch中的每个数据使用两种$T$中的数据增强方法,生成共计2N个数据;
- 将这2N个数据分别通过$f(·)$和$g(·)$,得到表征$h_{2k-1} h_{2k}$和$z_{2k-1} z_{2k}$;
- 对于2N个数据,两两计算相似度,这里使用的是余弦相似度;
- 将2N中的每个样本作为anchor,与其他所有样本计算损失,这个计算损失的过程中分母不包含自己到自己这一项,而分子是其与其另外一种的数据增强方式之间互相为正例;
- 更新网络参数,优化损失函数$L$,最终在使用表征的时候选用$f(·)$而丢弃$g(·)$;
2. CLINE: Contrastive Learning with Semantic Negative Examples for Natural Language Understanding
2.1 简介&总结
CLINE,ACL2021年的工作,这时候还是这种数据增强的手段比较经常出现,一句话经过同义词替换生成对抗性的例子(Adversarial example),经过反义词替换生成对比性的例子(contrast example),原句和同义词替换后的互为positive pair,和反义词替换后的互为negative pair;
损失函数使用三种加在一块,Masked Language Modeling(MLM,同BERT)、Replaced Token Detection(RTD)还有Contrastive Objective(CTS)。前两者MLM和RTD提升语义表达能力,CTS则是一个对比性目标
2.2 算法实现过程
- Figure1:An illustration of our model, note that we use the embedding of [CLS] as the sentence representation
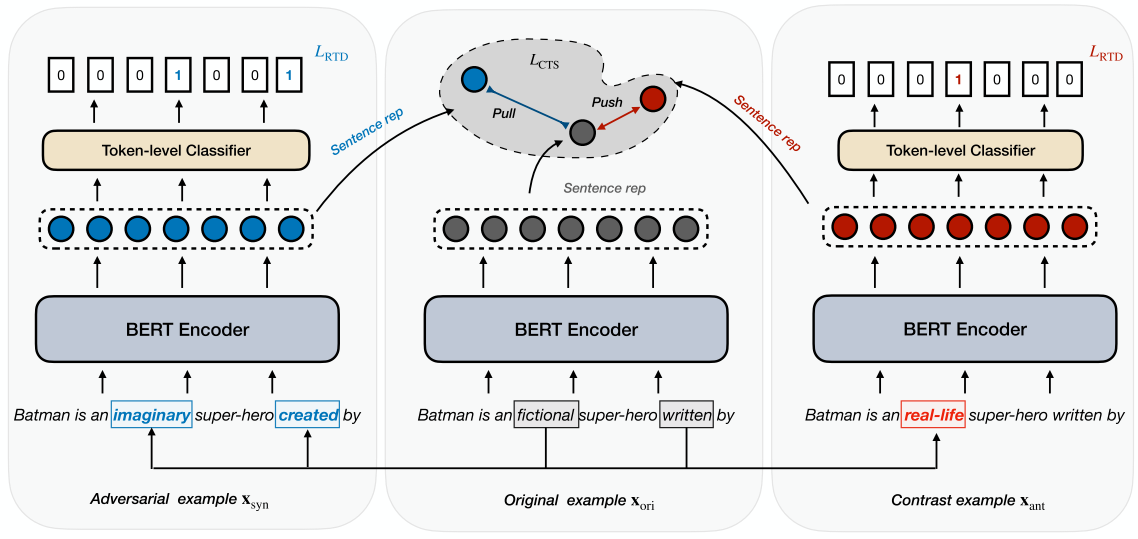
给定原数据(一句话)$x^{ori}$,对其使用spaCy算法库进行分词(segment)与词性标注(POS,part of speech tagging),之后对于$x^{syn}$同义词替换40%,对于反义词$x^{ant}$替换20%完成数据预处理;
将他们经过同样的一个BERT $h=E_\phi(x)$,获取$h^{ori}$、$h^{syn}$、$h^{cnt}$三种表征
损失函数第一项$L_{MLM}$:同BERT中的MLM任务,这个应该是直接集成在这个方法基础上的,作者没有给新的公式;
损失函数第二项$L_{RTD}$:只对于同义词替换和反义词替换的数据进行,预测哪些词是被同义词/反义词替换了的,过一个线性层sigmoid后得到每个位置被替换的概率(注意这里是sigmoid,看做一个多分类任务)。
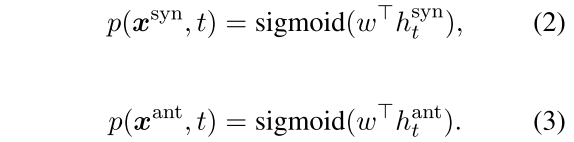
通过交叉熵损失函数计算这个$L_{RTD}$:
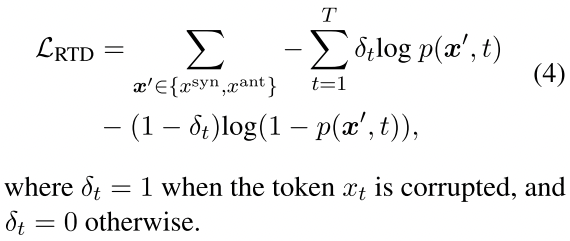
损失函数第三项$L_{CTS}$:对比性学习损失,相似性计算方式选择点乘相似度,这里没有引入温度常数$\tau$,一个句子的表征使用的是[CLS]token的embedding:
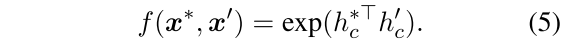
拉近$x^{ori}$和$x^{syn}$之间的距离,推远$x^{ori}$和$x^{ant}$之间的距离,这里在损失函数的计算上不涉及到和其他样本之间的关系,只是和自己的ori和ant之间来计算,最后也没有什么mean的操作
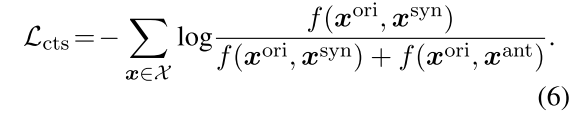
最终损失函数被表征为多项加在一起:
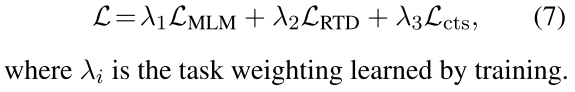
3. Self-Guided Contrastive Learning for BERT Sentence Representations
3.1 简介&总结
使用两个BERT构造正负例:①一个是不参与参数优化的BERT,对所有transformer层的隐藏层做maxpooling,即(batch,len,768)->(batch,1,768),再取均值作为句子的输出表征;②一个是参数优化的BERT,直接用最后一层[CLS]作为句子表征。这样处理之后,来自同一个句子的①②构造positive pair,来自不同句子的①②构建negative pair。
3.2 算法实现过程
- Figure2:Self-guided contrastive learning framework, we clone BERT into two copies at the begining of training. BERT_T(except Layer 0) is then fine-tuned to optimize the sentence vector c_i while BERT_F is fixed.
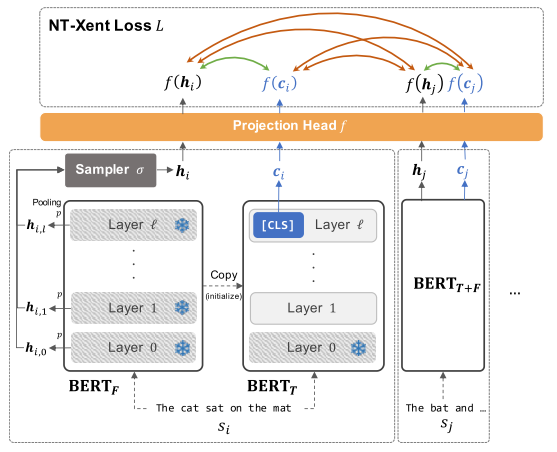
将BERT拷贝为两个副本,其中$BERT_F$在训练中被fix住,而$BERT_T$在训练时候的参数会更新,这里的意思应该也是会把pretrained的参数给load进去后fix住,否则不可能凭空来更新的;
在一个mini-batch中给定b句话$s_1,s_2, .. ,s_b$,输入到$BERT_F$中来获取这句话在每个层的隐藏表征$H_{i,k} \in R^{len(s_i)×d}$

在各层的这个表征$H_{i,k}$之中,存储的是每个token的一个tensor的shape,使用池化方法$p$获取一个集合的单个token的表征,即$h_{i,k}=p(H_{i,k})$,在这里作者选用的是最大池化。
从多个层中通过采样方法$\sigma$随机选择一个层的$h_i$,这里选用的是uniform sampler,这背后的motivation是把每一个看做是同样重要的,而不同BERT层表征了不同的语言concept
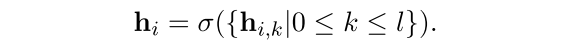
把$s_i$输入到$BERT_T$中,这里选用BERT最后一层的[CLS]token作为最后的输出表征:
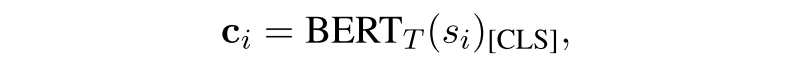
计算损失函数$L^{base}_{m}$,图中的绿色代表需要拉近,橙色代表需要远离,损失函数是类似SimCLR的那种,相似度使用的是余弦相似度,并且使用了projection head,这里也使用到了时间常数$\tau$:
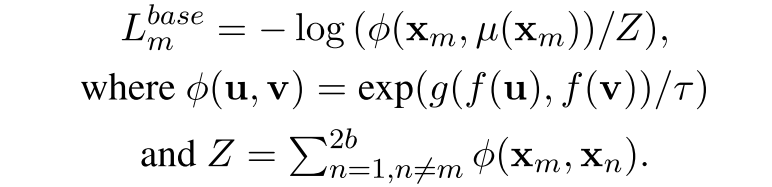
额外在对比性学习损失函数$L^{base}_{m}$的基础上,使用了一个regularzation的损失函数,这是由于$BERT_F$是一个fix住的,在训练的过程中他的表征空间可能要和$BERT_T$远离了
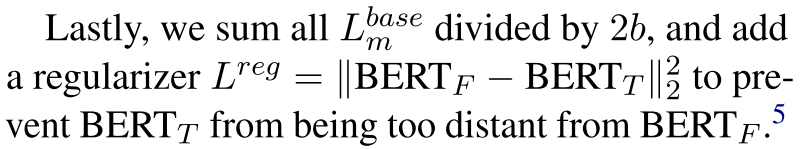
最终的损失函数通过下面这个式子来一起表示:

Figure3:Four factors of the original NT-Xent loss,green and yellow arrows represent the force of attraction and repulsion, respectively(attraction and repulsion:吸引力和排斥力)
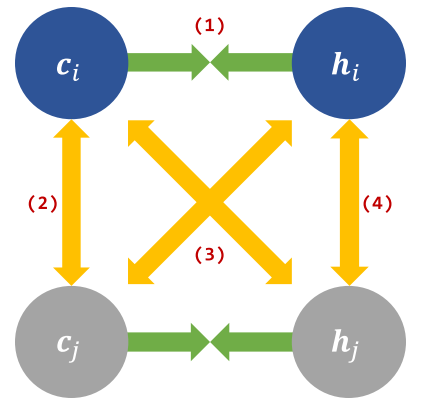
原始的损失函数要拉近图中的绿色边,而推远图中的黄色边,作者认为尽管这四种都起到确定的作用,一些元素可能是useless的或者甚至起到了与目标相反的目标,具体来说最近有报告说,在图像表示学习中,只有(1)是至关重要的,而其他都是不重要的。
原始的方法中,分母是(2b-1项,除了自己和自己):
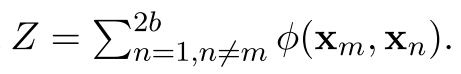
第一种提升方法,加强$c_i$和$h_i$之间的关系
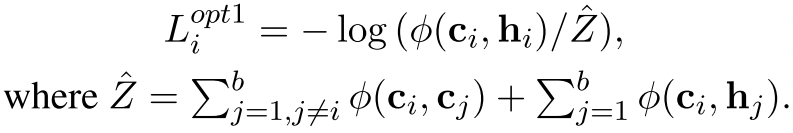
$h$是$BERT_{FIX}$那边出来的,这种情况下删除掉了第(4)种类型的边,也就是只使用ci作为anchor
第二种提升方法,删除第2种类型的边:
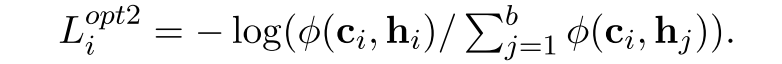
使用$BERT_{FIX}$那边multiple的${h_{i,k}}$来引导$c_{i}$
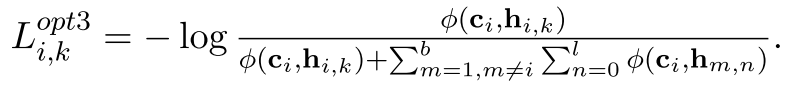
这种操作下的损失函数要把l的那个维度也给除掉,因为前面多了一维度求和
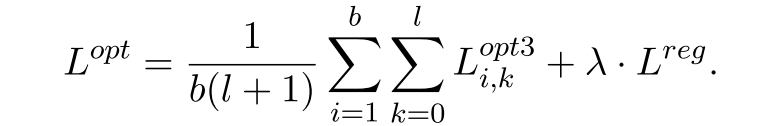
额外注:上边这个方法是在损失项上做文章,不过在各种方式下分母都没有忽略掉h1_1和h1_2那个意思的那一项,这个里面的数学原理可能还不是太明白
4. SimCSE: Simple Contrastive Learning of Sentence Embeddings
4.1 简介&总结
SimCSE是EMNLP2021年的论文,这个为后续的工作带来了非常多的经典,分为有监督学习和无监督学习两种方式,使用简单的Transformer架构中的dropout作为一句话的positive pair并与其他的生成negative pair。有监督学习在此基础上借助了NLI数据集,一个前提,和他蕴含的关系是positive pair,而和他矛盾的关系是negative pair,特别的针对这个前提的矛盾,额外加入一个权重来强化hard-negative的表现;
从alignment和uniformity两个方面还进行了一些理论分析,这里也从后续的一些论文阅读到,拉近正面的是一个alignment,而推开负面的使得表征具有各向同性的性质是一个uniformity
4.2 算法实现过程
- Unsupervised SimCSE
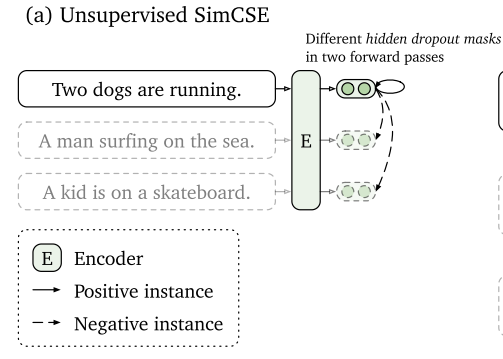
这里的方法解释也比较简单,一句话输入两次encoder,通过内部的随机dropout生成两种表征,两者互为正例,且与其他采样样本生成的两种表征互为负例
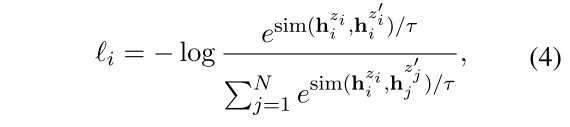
for a mini-batch ofN sentences. Note that z is just the standard dropout mask in Transformers and we do not add any additional dropout
- Supervised SimCSE
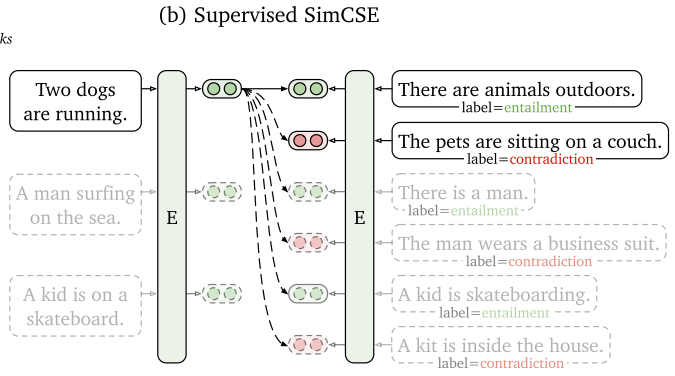
额外选用了NLI(自然语言推理,Natural Language Inference)的含标注数据集作为训练集,并将$(x_i, x_{i}^{+})$这样一个扩充到$(x_i, x^{+}{i},x{i}^{-})$,额外引入到一个hard negative。如图中所表示的,前提被给定为“Two dogs are running”,与其具有蕴含(entailment)关系的句子是“There are animals outdoors”,与其具有矛盾(contradiction)关系的句子是“The pets are sitting on a couch”,这个矛盾的句子关系是需要推得更远的,损失函数被表示为下面这个式子:
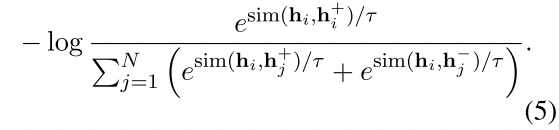
这里因为本身就没有自己和自己(h1_1和h1_1),所以分母也没有包含这一项,但是分母同样的包含了h1_1,h1_2那一项
在ablation study章节作者给出了这个式子的加权值表示,以希望进一步引导hard-negative,其中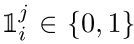 是一个指示符,只有当i==j的时候等于1,也就是说当$\alpha=1$的时候,是不是特殊hard-negative的权重都是1,而当$\alpha $大于1的时候,那么将受到指示因子的作用,只有那一项的权重将是$\alpha$其他项的系数还是1
是一个指示符,只有当i==j的时候等于1,也就是说当$\alpha=1$的时候,是不是特殊hard-negative的权重都是1,而当$\alpha $大于1的时候,那么将受到指示因子的作用,只有那一项的权重将是$\alpha$其他项的系数还是1
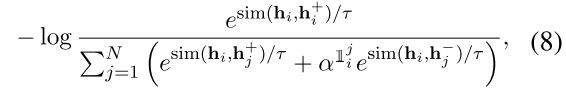
不过从做这个ablation实验来看,这个地方的实验现象不是很明显,但是加不加入hard-negative的现象还是很明显的

5. Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning
5.1 简介&总结
这篇有点不完全属于对比学习领域的工作,更像是一种比较通用的方法能够即插即用的放置到各个任务中。主要分为一种任务无关的CHILD-TUNING_F和一种任务相关的CHILD-TUNING_D,这样做背后的motivation大概可以解释为大型预训练语言模型已经具有比较强的表征能力,那么我们在下游微调的时候其实不需要完全更新全部参数,可以每次掩码掉一部分参数是不更新的
- 其中任务无关的就是随机一个矩阵,在反向传播的时候随机掩码掉一些梯度并且把其余部分的梯度放缩到期望与原来相同,从代码来说基本就是魔改了一下AdamW的实现;
- 其中任务相关的作者的实现可能和公式有些对不上,应该主要是依据梯度的大小做了一些操作;
此外作者还加入了一些数学公式的推导,证明了方法的有效性。方法相对即插即用(特别是task-free那个),代码可见:https://github.com/alibaba/AliceMind/tree/main/ChildTuning
5.2 算法实现过程
- overall:Figure1: The illustration of CHILD-TUNING, Left: It forwards on the whole network while backwarding on a subset of network(i.e., child network) Right: To archieve this, a task-free or task-driven mask is performed on the gradients of the non-child network, resetting them to zero (grey diagonal grids)
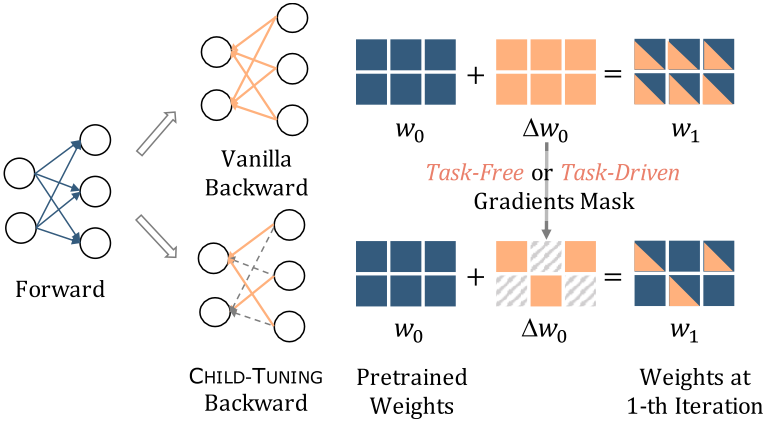
CHILD-TUNING的图示,左图:在前项传播的时候保持整个网络,而在网络的一个子集上执行backward。右图:为了实现这一点,对非子网络的梯度进行task-free或者task-driven的掩码,将其重置为0(灰色对角线网格)
首先考虑optimizer更新梯度的原始公式,如式子1所示:
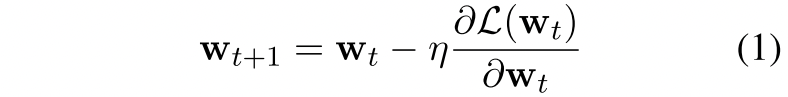
在CHILD-TUNING中,创建一个形状与$w_t$相同的掩码:
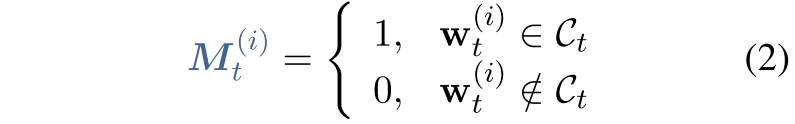
将其与式(1)进行点乘,这样就表明了CHILD-TUNING方法的原理,也比较好理解:
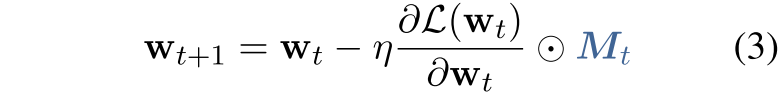
如下是一个算法流程,这个算法流程是以AdamW作为基础的optimizer更新公式,主要就是一个mask的生成过程:

- CHILD-TUNING_F(task-free)
生成一个满足伯努利分布的mask,这里说成伯努利分布其实有点故意说的复杂了,实际上只是一个均匀分布,如果当$p_F$等于1的时候那么与vanilla的方法相等

这里在梯度上要保持原来的期望:Note that we also en- large the reserved gradients by $1/{p_F}$ to maintain the
expectation of the gradients
此外,在每个步骤的时候都随机一个mask,因为每个步骤的时候这个代价是不大的,不需要什么额外的计算过程;
- CHILD-TUNING_D(task-driven)
通过统计fisher信息制作mask: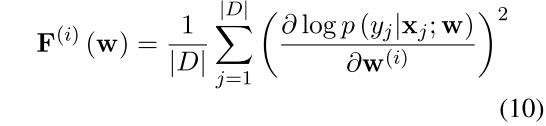
比起CHILD-TUNING_F来说,这个统计起来的时候比较复杂,所以只能在一开始的时候随机一次,并在fine-tuning的过程中保持不变:$C_0=C_1=···=C_T$
6. Momentum Contrast for Unsupervised Visual Representation Learning
6.1 简介&总结
Momentum的方式进行对比学习,优化了memory bank方法中,bank中由于参数更新导致各项表征差距过大的问题,这里momentun使得bank中已经存储的表征值每次只在之前的基础上微微改变了,这样bank中的represetation之间差异不会很大
和memory bank方法类似,解决了end-to-end方法中负样本数过少的问题
6.2 算法实现过程
- 从以往的对比学习发展到MoCo
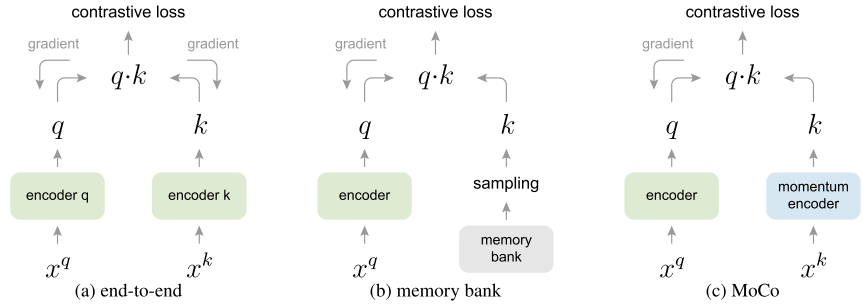
- 他人博客的一个对于MoCo方法的图解
获取把x经过两种增强q1k1后的表征,feature q1通过一个encoder q(resnet-50)来获得,feature k1则是通过momentum encoder来获取,momentum encoder的参数更新非常缓慢,仅慢慢随着encoder q的变化而变化(初始化为encoder q) ,这样存入memory bank中的参数会小
,这样存入memory bank中的参数会小
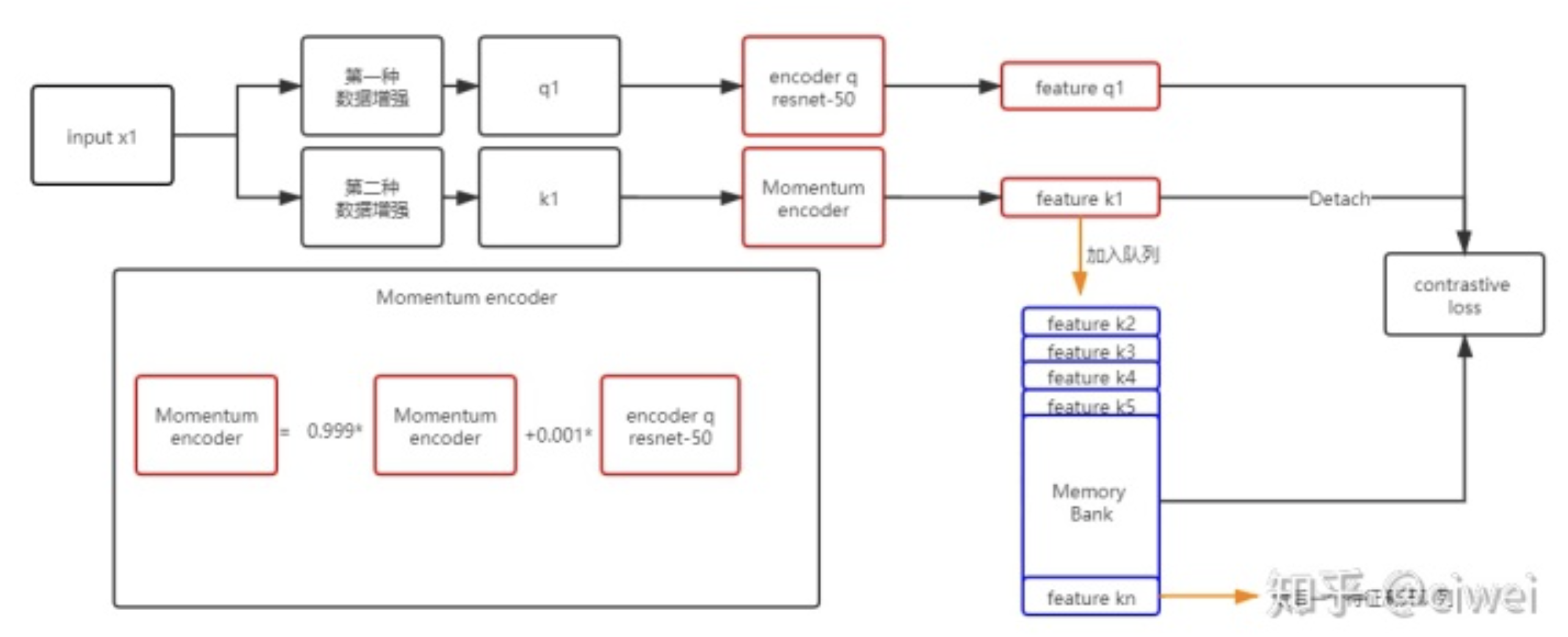
- 作者给的Algorithm:
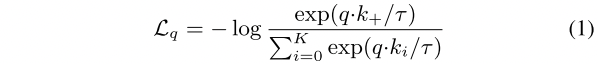

把一个x经过两种aug方法后变成x_q和x_k两个,然后经过f_q和f_k层的foward变成q和k,注意这里在初始化的时候让f_k的params=f_q的params。k.detach()代表不追踪k的梯度。
l_pos代表了q和k的相似度,也就是positive pair。l_neg代表了q和queue(长度为k)中的所有的相似度,也就是negative pair。通过式1来计算一个contrastive loss(InfoNCE),之后SGD(随机梯度下降)的方法对f_q网络层的参数进行update。
重点:每迭代loader中的一个样本x,需要更新f_k的参数,但是这里是一个momentum的更新方式,每次更新的很少。最后维护queue,把negative样本给放进去。
7. TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning
7.1 简介&总结
利用标记感知对比学习改进BERT预训练,首次将对比学习用于改进Transformer模型的token level表示(之前大多工作好像是句子级别的),并在token级别上盖上了各向异性这样一个问题,这背后的motivation是目前的大多未经特殊调整的Transformer对于词的一个表征大多是各向异性的,就是说表征两个词之间差距太小了,需要调整来更加分散变为各向同性的
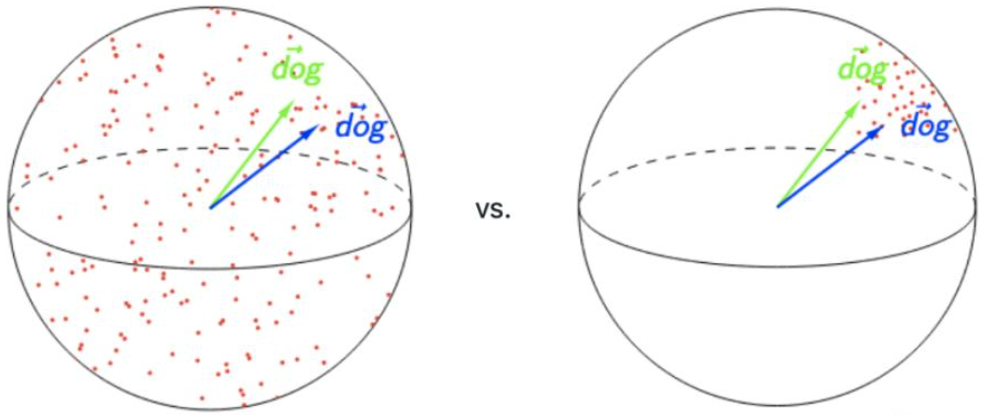
各向异性的缺点在于,最后学到的向量都挤在一起,彼此之间的余弦相似度很高,并不是一个很好的表示。一个好的表示应该同时满足Alignment和Uniformity,前者表示相似的向量距离应该相近,后者表示向量在空间上应该尽量均匀,最好是各向同性的
不过从阅读论文的感觉来说,在token级别这么做是真的合理么,token级别那不是负例的实际上是更加可能的,比如两个单词他们本来在语义上就应该接近一些,以及一些指代关系的存在,会不会让这里有些问题?
7.2 算法实现过程
- Figure1: An overview of TaCL. The student learns to make the representation of a masked token closer to its “reference” representation produced by the teacher (solid arrow) and away from the representations of other tokens in the same sequence (dashed arrows).
TaCL的概述。学生模型学会使被掩码的token的表示更接近教师模型产生的 “reference”表示(实线箭头),并远离同一序列中其他标记的表示(虚线箭头)。
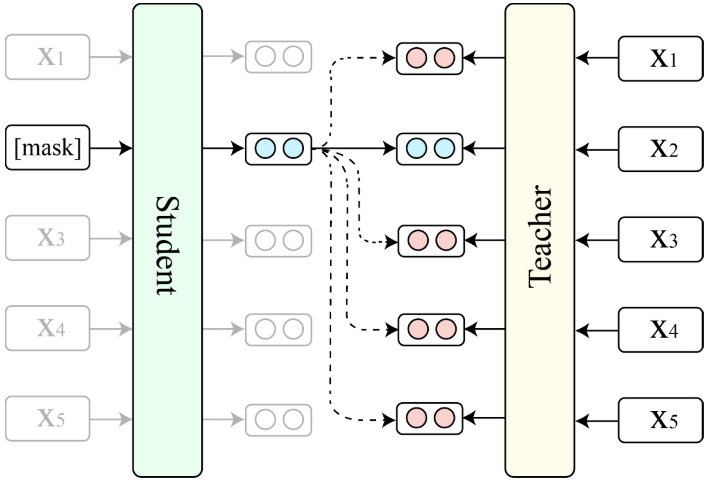
- 学生模型Student和教师模型Teacher都是从相同的预训练BERT模型中初始化的。在训练过程中固定Teacher的参数,只优化Student的参数;
- 给定序列$x=[x_1,x_2, …, x_n]$,我们使用与BERT相同程序随机掩码$x$,并将掩码后的$\hat{x}$送入到学生模型中,以产生上下文表征
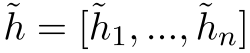 。将未掩码的$x$送入到教师模型中获取表征
。将未掩码的$x$送入到教师模型中获取表征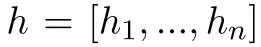 ,提出标记感知的对比性学习目标作用于两者之间,$L_{TaCL}$被定义为式1:
,提出标记感知的对比性学习目标作用于两者之间,$L_{TaCL}$被定义为式1:


这里额外给出的解释是说只把mask掉的作为一个token级别的anchor
- 截止这里的话其实方法实现就差不多了。在直觉上,学生学会了使被掩码token的表示更加接近于教师模型产生的reference表示,而远离同一序列中的其他标记。因此,Student模型学到的标记表征将对不同的标记更具辨别力,因此更能遵循各向同性的分布。
- 最后,作者把MLM(masked language modeling)和NSP(next sentence predicition)也加入到预训练fine-tune这个过程的目标:
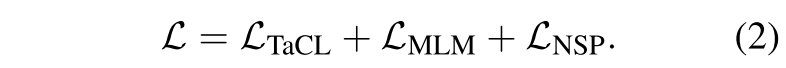
- 总结来说,学生的学习是无监督的,可以使用原始的训练语料库来实现。学习完成后,我们在下游任务中对学生模型进行微调。
8. EASE:Entity-Aware Contrasitve Learning of Sentence Embedding
8.1 简介&总结
实体感知的对比学习用于句子的embedding表征,比较巧妙的应用了维基百科数据以及一些句子中存在的超链接。这个超链接和平常想象的超链接是一样的,也就是说句子中会有超链接,有点相当于一种能够额外获取到的数据了。这样自监督的构建了一些positive pair,并且由于维基百科数据收集的特点,能够在多语言语料之间完成对齐;
另外还有一些可能存疑的问题是,把一个实体和一个句子当做positive pair这样的感觉,那么如果切换了训练数据场景这个特征就会显得很奇怪,毕竟一句话中的实体还是很多的,可能这块也是利用了训练数据的特点吧。
8.2 算法实现过程
- Figure1: Illustration of the main concept behind EASE. Using a contrastive framework, sentences are embeded in the neighborhood of their hyperlink entity embeddings and kept apart from irrelevant entities. Here, we share the entity embeddings across languages for multilingual models to facilitate cross-lingual allignment of the representation
EASE背后的主要概念说明。使用一个对比性框架,句子被嵌入到其超链接实体的邻近区域,并与不相关的实体分开。在这里,我们为多语言模型分享不同语言的实体嵌入,以促进表述的跨语言对齐。
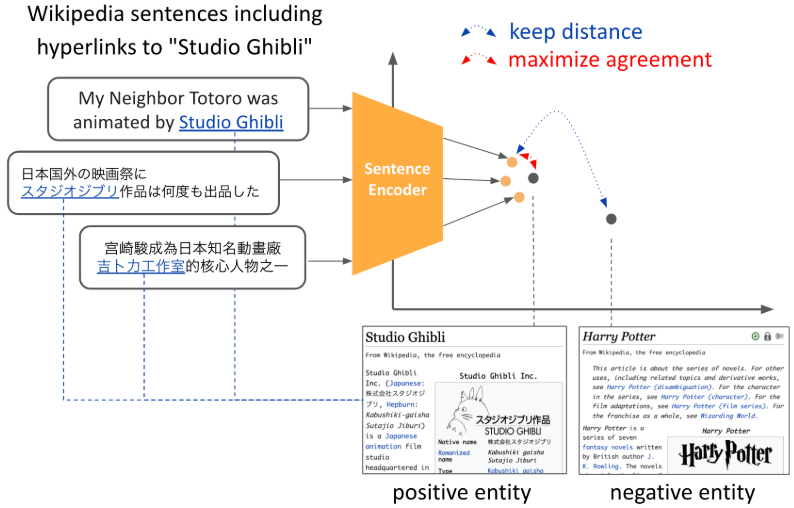
基于实体的对比学习,给出一个句子和一个语义相关的positive实体对
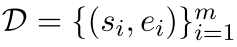 ,我们训练我们的模型来预测句子实体表征$e_{i} \in R^{d_e}$,从句向量表征$s_{i} \in R^{d_s}$中。按照Chen等人SimCLR的对比学习框架,我们对N个配对的mini-batch $(s_i, e_i)$,通过下式计算训练损失:
,我们训练我们的模型来预测句子实体表征$e_{i} \in R^{d_e}$,从句向量表征$s_{i} \in R^{d_s}$中。按照Chen等人SimCLR的对比学习框架,我们对N个配对的mini-batch $(s_i, e_i)$,通过下式计算训练损失: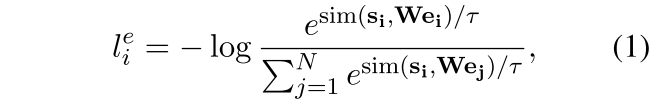
注意这里在ei的表示前面加了一个$W \in R^{d_e×d_s}$是一个可学习的矩阵参数,否则从自己的感觉来说,一个句子的表征和一个实体的表征这样拉近推远,可能会使得噪声很大吧。
hard-negative entites:
- 具有相同类型的实体被作为positive实体,例如“ABC工作室”和“工作室”,这是一种“instance of”的关系,如果有不止一种合适类型的实体,那么会随机选择一种(略微有一些父层级选择的感觉);
- 不出现在同一维基百科页面上的实体被看做是negative的,比如“吉卜力工作室”实体的类型是“工作室”,然后“华特迪士尼动画工作室”就是不出现在同一个页面上的实体,那么把他作为一个negative,还是一个相对较难的hard-negative;(原文给出的描述是:For example, the “Studio Ghibli” entity has the type “animation studio” and one of the hard negative entity candidates is “Walt Disney Animation Studios”)
经过上面的处理后,现在有一个包含hard-negative的集合$D={(s_i,e_i,e^{-}{i})}{i=1}^{m}$
损失函数被如下定义,注意这里分母是普通的negative加上额外的hard-negative:
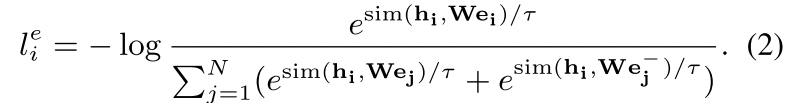
- 一些细节:
实体的嵌入表征使用了开源的Wikipedia2Vec工具(EMNLP2020-demo),向量维度被设置为与基础预训练模型隐藏表征相同的768,实体嵌入矩阵的参数在训练过程中被更新;
最后把SimCSE的方法生成的损失函数给加上:有dropout噪声的self-supervised CL,它把一个句子放进去,用dropout作为噪声来预测自己,是一种以无监督方式学习句子嵌入的有效方法。我们将这个方法加入到我们的实体CL方法中,最终的损失函数被如下表示:
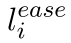 =
=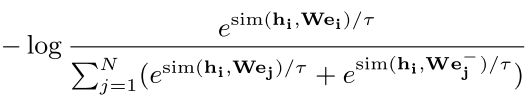 +
+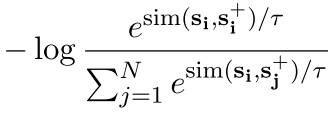
句子-超链接实体之间的对比损失 + 句子-句子之间的对比损失(SimCSE)
9. Virtual Augmentation Supported Contrastive Learning of Sentence Representations
9.1 简介&总结
虚拟增强支持的句子表征的对比学习,有一种反向思路的感觉,通过邻域样本制造hard-negative:离自己相对较远而离邻居相对较近的一个微小扰动,但感觉不是negative这样的,就相当于创建了一个比较难(距离比较远)的positive-pair;
先在邻域内找到与$e_i$相似的K个样本$N(i)={k:e_khasthetop-Ksimilaritywithe_i}$,然后来对比学习加上SimCSE的损失函数,使用中无监督的Virtual Augmentation方法,
9.2 算法实现过程
- Figure1: Illustration of VaSCL. For each instance $x_i$ In a randomly sampled batch, we optimize (i) an instance-wise contrastive loss with the dropout induced augmentation obtained by forwarding the same instance twice, i.e., x_i and x_i’,denote the same text example; and (2) a neighborhood constrained instance discrimination loss with the virtual augmentation proposed
- 对于随机抽样批次中的每个实例$x_i$,我们优化(i)实例对比损失,通过两次输入同一实例,即x_i和x_i’,表示同一文本实例,得到的dropout诱导增强(这是);以及(2)邻域约束的实例歧视损失,提出的虚拟增强
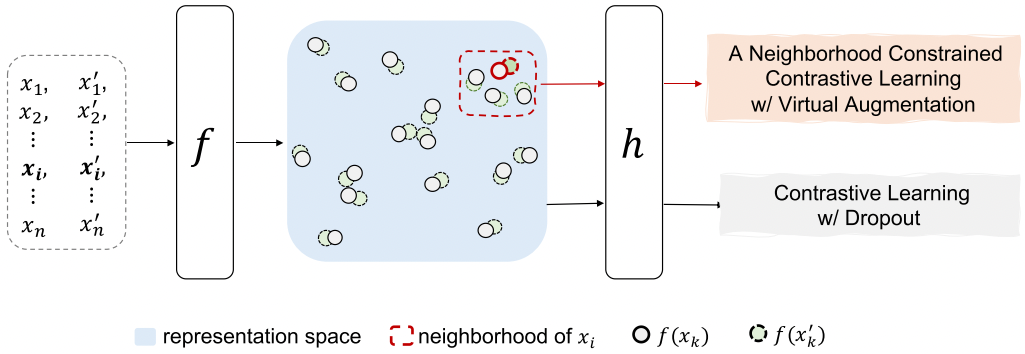
首先构建邻域,在此基础上进行数据增强,邻域被看做是语义相似的样本,首先使得$B={i}_{i=1}^{M}$代表随机采样选取的大小为M的一批数据。我们首先对于第i个实例,选择其最K近邻的邻居$N(i)$(首先将第1个实例的邻域N(i)近似为它在表示空间中的K个最近的邻居)
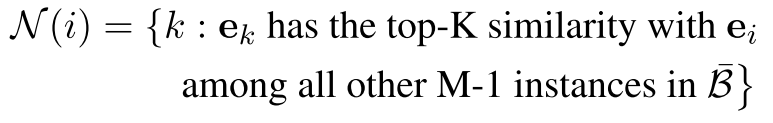
定义一个实例级别的对比损失,关于第1个实例和他的邻域
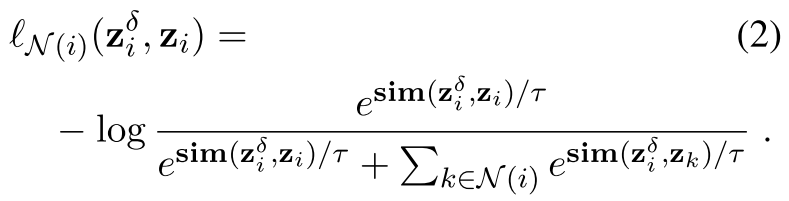
其中
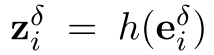 代表perturbed representation
代表perturbed representation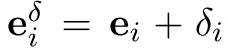 在contrastive learning head的输出表征。这里,初始扰动δi被选为各向同性的高斯噪声。方程(2)显示了将受扰动的第i个实例归类为自身而不是其邻居的负对数可能性。
在contrastive learning head的输出表征。这里,初始扰动δi被选为各向同性的高斯噪声。方程(2)显示了将受扰动的第i个实例归类为自身而不是其邻居的负对数可能性。即是说,当扰动和自身接近的时候loss小,而当扰动和其他邻居更加接近的时候loss大。这里是在e_i这个表征层面的操作
确定上述最佳扰动的方法如下,取最大的扰动(这个扰动的二范式,也就是自身长度大小那种感觉不能超过△,然后这个扰动使得他离K近邻的这些neighbor相对更近,而离自己较远,那么来说的话,这是一个很好的hard样例,扰动了一下但是和原句一个意思,然后又比较难):
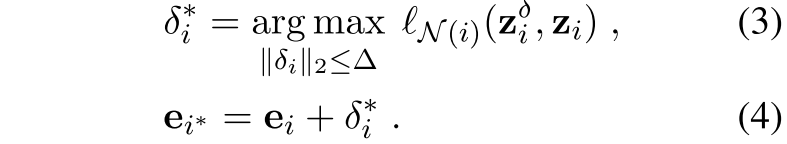
对比学习损失函数如下,将$N_A(i)$表示第i个实例的增强邻域,即
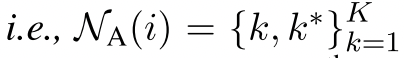 。$e_k$代表原始的第k个实例的嵌入表征,$e_k*$代表相关的增强后的表征。注意这里$e_k*$是以方程(4)中定义的同样方式获得的,关于它自己的邻域$N{(k)}$。然后,我们将第i个实例及其数据增强与它的数据增强邻域$N_A(i)$内的其他实例区分开来,如下所示:
。$e_k$代表原始的第k个实例的嵌入表征,$e_k*$代表相关的增强后的表征。注意这里$e_k*$是以方程(4)中定义的同样方式获得的,关于它自己的邻域$N{(k)}$。然后,我们将第i个实例及其数据增强与它的数据增强邻域$N_A(i)$内的其他实例区分开来,如下所示: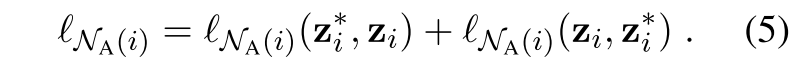
即是:分别以第i个实例的增强,和第i个实例作为anchor:原句和其虚拟的困难样本形成positivepair相互拉近,原句和原句的虚拟样本分别于K邻域内的负样本 虚拟困难样本拉远
最后再把SimCSE的loss给拼上:对于每个有M个样本的随机抽样的mini-batch B,我们最小化如下的损失函数
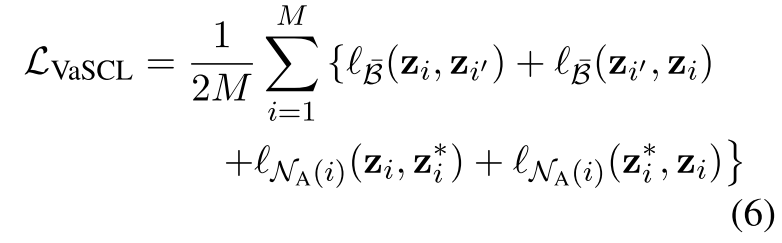
加上噪声后h1和h1_比较远,h2和h1_有可能比较近;;;保留恒等性又不能太近了
10. Debiased Contrastive Learning of Unsupervised Sentence Representations
10.1 简介&总结
1)motivation是一个非常常见的motivation,就是说抽样得到的负例不一定很可靠,这样基于一个辅助模型搞个阈值判断,辅助模型用的SimCSE;
2)VAT的虚拟对抗训练方法扩充了一些样本,作为negative;
10.2 算法实现过程
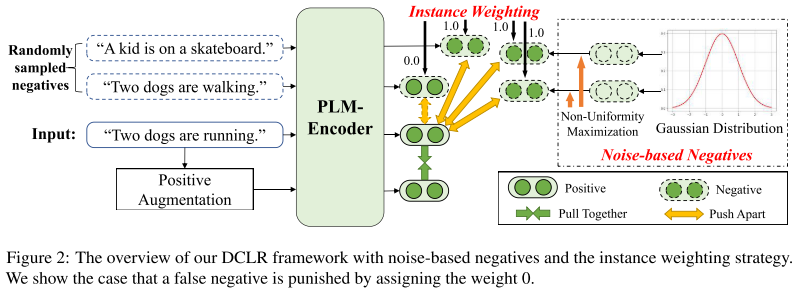
自己理解:输入一句话“Two dogs are runing”,而随机采样到了两句话“Two dogs are walking”,“A kid is on a skateboard”,其中“Two dogs are walking”这句话和原来那句话明显还是有一定相似的,在推远这两个的过程中我们要把他们的权值设置成0。往下走的positive augumentation可以是SimCSE的这样一个dropout再来一次,此外还用高斯分布最大化不同生成了一些Noise-based Negatives
DCLR包含三个主要步骤。
1)我们生成基于噪声的negative来扩展batch内的negative。具体来说,我们首先使用通过随机的高斯噪音来初始化一组新的negative信息,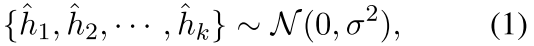 。然后,我们加入了一个基于梯度的算法,通过使用
。然后,我们加入了一个基于梯度的算法,通过使用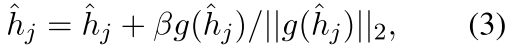 使非均匀目标最大化来调整基于噪声的否定。经过几次迭代,我们可以得到与整个语义空间内的非均匀点相对应的基于噪声的否定词,并将它们与批量内的否定词混合起来,组成否定词集。
使非均匀目标最大化来调整基于噪声的否定。经过几次迭代,我们可以得到与整个语义空间内的非均匀点相对应的基于噪声的否定词,并将它们与批量内的否定词混合起来,组成否定词集。
2)我们采用一个补充模型(即SimCSE)来计算原始句子和负数集的每个例子之间的语义相似度,并使用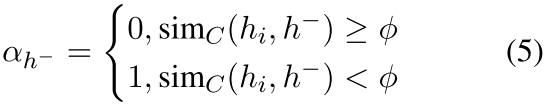 产生权重。
产生权重。
3)最后,我们通过dropout来增加正面的例子,并利用负面的例子和相应的权重来进行对比学习,使用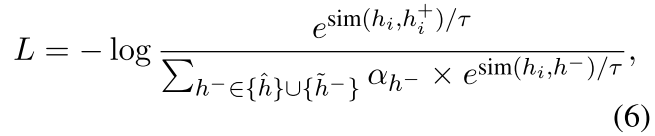 。
。