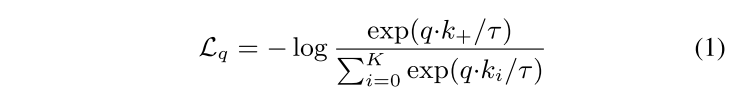cvpr2020_MoCo-MomentumCL论文阅读
cvpr2020_MoCo-MomentumCL论文阅读
Momentum Contrast for Unsupervised Visual Representation Learning
中文翻译为:用于无监督视觉表征学习的动量对比
个人总结贡献如下:
- Momentum方式进行对比学习,优化了memory bank方法中,bank中由于参数更新导致各项差距过大的问题,这里momentum使得bank中的每次只在之前的基础上微微改变,这样bank中的representation之间差异不会很大;
- 这种方式避免了mini-batch导致的
References
- CVPR2020-MoCo-无监督对比学习论文解读:https://www.zhihu.com/search?type=content&q=CVPR2020%20MoCo;https://zhuanlan.zhihu.com/p/34283945
- Moco解读:https://zhuanlan.zhihu.com/p/382763210
X. 对照博客1简单理解下流派的发展
首先学习以往无监督对比学习是如何做的
X.1 end-to-end模式
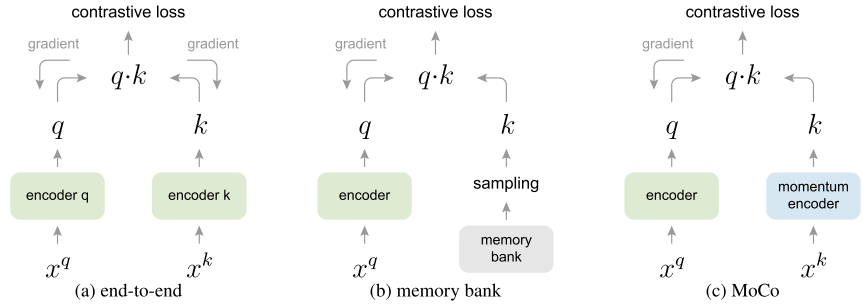
第一种为end-to-end模式,博客作者给了下面这样一个图
希望拉进正样本之间的距离,推远负样本之间的距离。这样存在的一个问题是负样本的数量受到batch_size大小的限制,在没有庞大GPU集群的支持下,负样本的数量是不会特别多的。这也是很快创新改进memorybank方法的创新点之一,解决负样本数量的问题。
X.2 Memory Bank模式
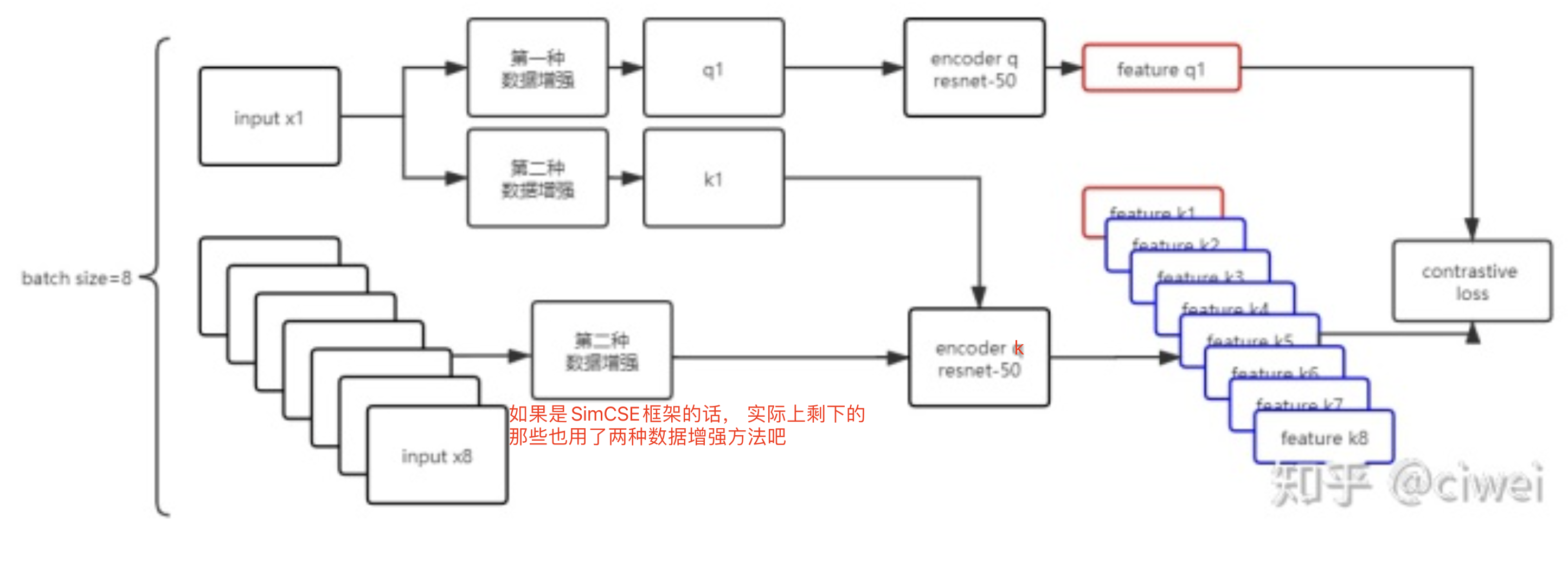
给了这么一张图,对照博客作者的文字理解下这张图:开始时生成一个大小为k的队列,队列里面的feature都是随机初始化的,这个就是Memory Bank。然后开始训练,每迭代一次,将新生成的feature k1加入到队列中,并让队列中最老的feature出队,由于feature是已经经过编码的了,所以一次可以输入大量的负样本,解决了end-to-end方法中负样本数过少的问题。
MoCo指出来的问题是,Memory bank存在的问题是随着训练的不断进行,encoder q的参数在不断更新,这导致memory bank中的负样本feature差别过大,有的是刚更新的,有的是用很久以前参数生成的特征,这不利于对比学习。
MoCo的创新点也就在这里,通过引入momentum encoder来让memory bank中feature差异变得更小,也就是让特征更加平滑。

X.3 MoCo模式
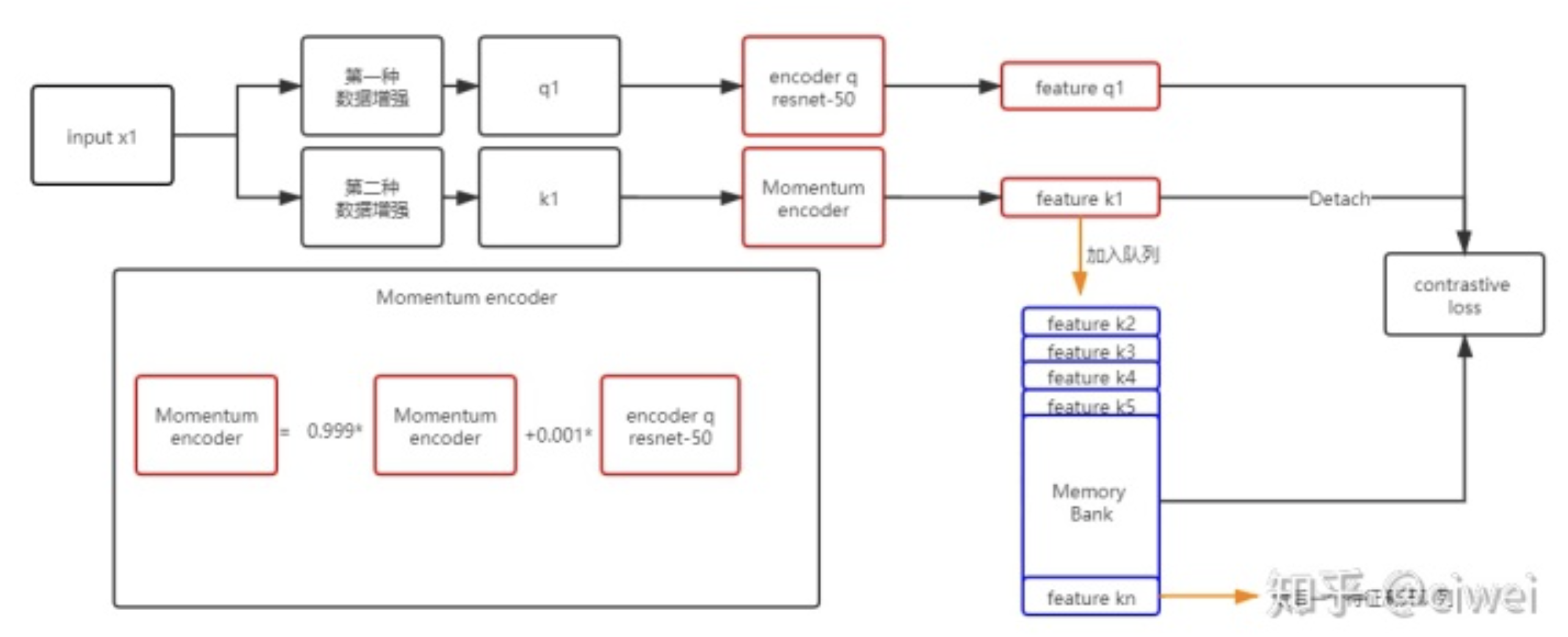
feature k1的获取不是通过encoder q了,而是通过encoder q参数的历史组合得到,momentum encoder和encoder q的网络结构完全相同 ,仅是参数不一样。
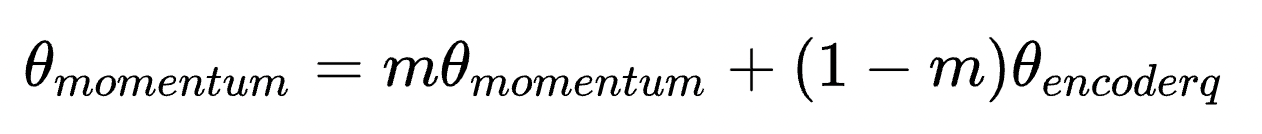
这样Memory Bank中的feature区别就会变小,解决了Memory bank存在的问题。
维护的memory bank是针对k的,维护更大的一个memorybank?为什么要维护更大的一个memory bank,早期的研究,认为不能无限的增大batch,认为越大的负例队列,中间出现hard-negative越大,但有些研究又说hard-negative更有用的—— 做题的时候,错题本作用更大的,怎么出现hard-negative?一次batch越大hard-negative越大;;;;但伪正例的可能性也越大?
0. Abstract
我们提出了Momentum Contrast(MoCo)用于无监督的视觉表征学习。从对比学习作为词典查找的角度出发,我们构建了一个带有队列和移动平均编码器的动态词典(这里这个词典不知道该怎么理解,英文使用的是dictionary,是指的key-value?) 。这使得我们能够即时构建一个大型的、一致的字典,以促进对比性的无监督学习。MoCo在ImageNet分类的普通线性协议下提供了有竞争力的结果。更重要的是,MoCo学到的表征可以很好地转移到下游任务中。在PASCAL VOC、COCO和其他数据集的7个检测/分割任务中,MoCo的表现优于其有监督的预训练对应物,有时甚至以较大的幅度超过它。这表明,在许多视觉任务中,无监督和有监督的表示学习之间的差距已经基本消除。
1. Introduction
无监督的表征学习在自然语言处理中非常成功,例如GPT和BERT。但在计算机视觉中,有监督的预训练仍然占主导地位,而无监督的方法通常落后于此。原因可能来自于它们各自信号空间的差异。语言任务有离散的信号空间(word、subword unit等),用于建立标记化的字典,无监督学习可以基于此。相比之下,计算机视觉则进一步关注字典的建立,因为原始信号是在一个连续的、高维的空间中,并不是为人类交流而构建的(例如,与单词不同)。怎么理解这里的dictionary,一些博客中指出原始的自监督学习方法里面这一批负样本就相当于是有个字典(dictionary),字典的key就是负样本,字典的value就是负样本通过encoder之后的内容,字典的大小就是batch_size
最近的几项研究提出了使用与对比性损失有关的方法进行无监督视觉表征学习的有希望的结果[29]。尽管有不同的动机,这些方法可以被认为是建立动态字典。词典中的 “键”(tokens)是从数据(如图像或斑块)中采样的,并由一个编码器网络表示。无监督学习训练编码器进行字典查询:一个编码的 “查询 “应该与它匹配的键相似,而与其他键不相似。学习被表述为最小化对比性损失
TODO:待补充
3. Method

自己尝试解读一下这个流程,把一个x经过两种aug方法后变成x_q和x_k两个,然后经过f_q和f_k层的foward变成q和k,注意这里在初始化的时候让f_k的params=f_q的params。k.detach()代表不追踪k的梯度。
l_pos代表了q和k的相似度,也就是positive pair。l_neg代表了q和queue(长度为k)中的所有的相似度,也就是negative pair。通过式1来计算一个contrastive loss(InfoNCE),之后SGD的方法对f_q网络层的参数进行update。
注意重点在这里:每迭代loader中的一个样本x,需要更新f_k的参数,但是这里是一个momentum的更新方式,每次更新的很少。最后维护queue,把negative样本给放进去。