acl2021_CL-for-BERT-Sentence Representations论文阅读
acl2021_CL-for-BERT-Sentence Representations论文阅读
论文全称:Self-Guided Contrastive Learning for BERT Sentence Representations
总结贡献:
- 两个bert构造正负例:①一个参数不参与优化的Bert,对所有层的transformer隐藏层做maxpooling,即(batch,len,768)->(batch,1,768),再取均值作为句子的输出表征;②一个参数优化的bert,直接用最后一层[CLS]作为句子表征;来自同一句话的①②表征构成正例,不同句子的①②表征作为负例。
- 主要用于STS语义相似度的任务,直接得到BERT表征而不依赖于数据进行fine-tune,无监督的得到初始比较好的句子representation
- 创新点:表示学习句子的[CLS]token,可被文本语义相似STS任务直接用,而且不依赖label数据的训练?
reference
https://blog.csdn.net/qq_33161208/article/details/123631813 # ACL2021 | 对比学习8篇论文一句话总结
https://www.jianshu.com/p/c33a79603f43 # NT-Xent loss
0. Abstract
尽管BERT及其变体已经重塑了NLP的格局,但如何从这种预先训练好的Transformer中最好地推导出句子嵌入(sentence embeddings)仍然是不清楚的。在这项工作中,我们提出了一种对比性学习方法,利用self-attention来提高BERT句子表示的质量。作者提出的方法以self-supervised的方式对BERT进行微调,不依赖数据的增强,并使用通常的[CLS]token嵌入作为句子向量发挥作用。此外,作者重新设计了对比性学习目标NT-Xent,并将其应用于句子表示学习。
通过大量的实验证明,该方法在各种与句子有关的任务上比竞争baseline更有效。还证明了它在推理方面的效率和对领域转移的稳健性。
作者似乎认为使用[CLS]这个token的方法有待商榷,然后在experiment那边STS(Semantic Textual Similarity,语义文本相似性) task是用来评估这个句子表征的
1. Introduction
自己对Introduction章节的理解是综述研究背景,综述一下别人的方法和存在的不足,最后再说一下自己的方法和主要贡献,大概就按照这几个方面总结一下Introduction章节
1.1 综述别人的方法和存在的不足
这个地方研究背景作者似乎很快就带过了,不单独列为一个章节了
预训练的Transformer语言模型,如BERT、RoBERTa等已经成为最近实现自然语言理解改进的重要组成部分。然而,直接将这些模型用于句子级别的任务并不简单,因为他们基本上是预先训练好的,专注于预测给定上下文的子单词标记(MLM?) 。将这些模型转化为句子编码器的最典型方式是在下游任务的监督下对其进行微调,在这个过程中,BERT作者提出将编码器最后一层[CLS]token的嵌入看做输入序列的代表。这种简单而有效的方法是可能的,因为在监督微调期间,**[CLS]嵌入作为预训练编码器和任务特定层之间的唯一通信门**,鼓励[CLS]向量捕捉整体信息。
TODO:待和zkh讨论,为什么通过[CLS]token的下游监督就能对整个BERT Encoder进行微调,或者说就是通过这一个,前面所有层的参数就都会跟着变了?
另一方面,在标记数据集不可用的情况下,不清楚从BERT推导句子embedding的最佳策略是什么。以前的研究指出,没有任何处理的使用[CLS] token作为句子的表示,就像监督微调一样(这句话没有理解,从英文上好像是差不多的意思,不清楚作者想表达的是不是不进行监督微调,直接使用?) 结果令人失望。目前,在没有监督的情况下构建BERT语句嵌入最常见的经验法则是在BERT的最后一层应用mean pooling。(这里BERT最后有个pooler,这里的mean pooling是指的那个地方吗,听起来好像不像。) 然而,这种方法可能是次优的,在一个初步的实验中,作者通过采用不同的BERT层和池化方法的不同组合来构建句子embedding,并在语义文本相似性(STS)基准数据集上进行测试。以Spearman相关度(×100)来衡量(暂时还不太了解这个指标,看起来是越高越好?) ,作者发现,选用不同层BERT-base [CLS]token的输出,还有在不同层之间选择池化方法,都对性能很有影响,而且看起来浮动很大。
作者使用了一个完全没有经过fine-tune的BERT进行训练,发现各层通过不同方法对句子的表征是有一定差异的,从而质疑BERT句子向量的做法还不够扎实,还有余地发挥BERT的更多表现力不过这里有没有一种可能,就是这个评估方法不太合理?还是对这个评估方法不太了解了
或者说,作者认为无论是简单粗暴取各层的[CLS]token,还是做mean/max pool,直接选用这些向量的做法都不好,需要把这些融合到一块来?这样作者的一个很大的亮点在于不需要数据的增强(有别于CL范式中的数据增强),而是直接用这些预训练[CLS]就可以
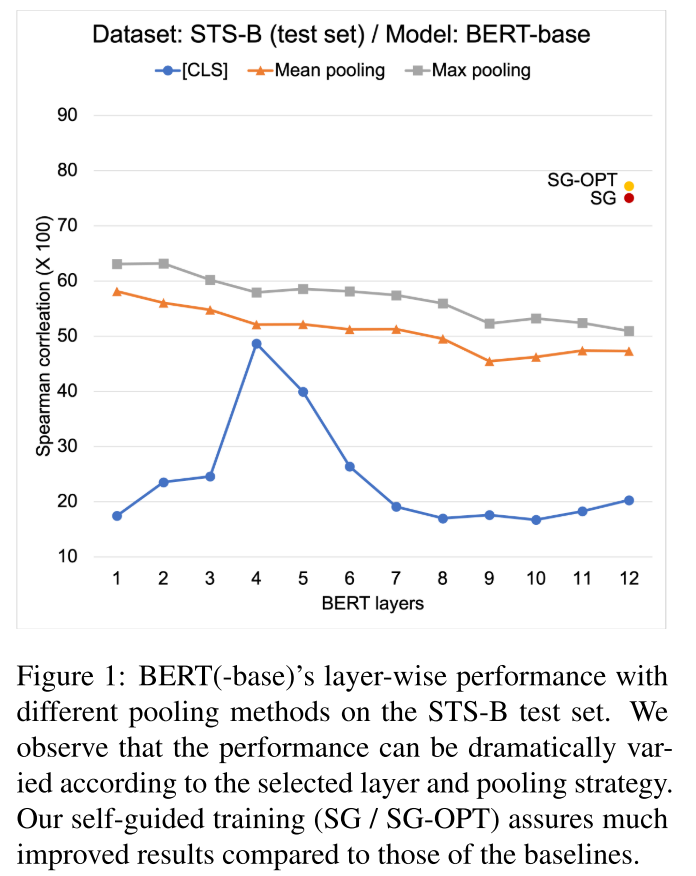
注:图中SG-OPT和SG是作者的方法产生了大幅的提升,具体方法将在后面进行说明;
1.2 作者提出的方法
在这项工作中,作者提出了一种对比性学习(CL)方法,利用新提出的self-attention机制来解决上述问题。其核心思想是将中间的BERT隐藏表征作为正样本进行回收,最终的句子嵌入应该与之接近。
由于作者的方法不需要数据增强,而数据增强在最近的对比学习框架中是必不可少的,因此它比现有的方法要简单和容易使用。此外,我们定制了NT- Xent损失(Chen et al., 2020),一个广泛用于计算机视觉的对比学习目标,以更好地使用BERT进行句子表示学习。我们证明,我们的方法在各种环境下都优于为建立BERT句子向量而设计的竞争性基线。通过全面的分析,我们还表明,我们的方法在推理方面比基线更有效率,而且对领域的转变更加稳健。
这里NT-Xent损失就是SimCLR中给出的损失函数,避免了正例自己和自己的pair计算:https://www.jianshu.com/p/c33a79603f43
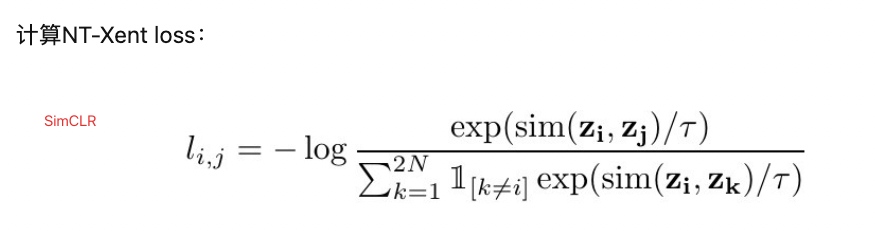
SimCLR分母中 ![1_{[k\neq i]}](/img/loading.gif)
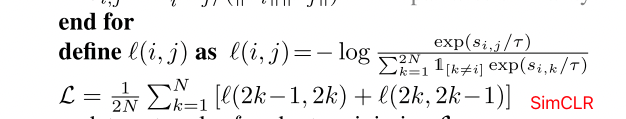
2. Related Work
related work章节主要感觉是分门别类的总结一下之前的方法,再引一下之前方法的不足,说一下自己方法的好处
2.1 Contrastive Representation Learning
对比性学习长期以来被认为是构建有意义的表征的有效方法。这里主要说的一些NLP相关的
- Mikolov等人(2013)提出通过将目标词附近的词作为正面样本,而将其他词作为负面样本来学习词嵌入。
- Logeswaran和Lee(2018)将Mikolov等人(2013)的方法推广到句子表示学习。
- 最近,一些研究(Fang和Xie,2020;Giorgi等人,2020;Wu等人,2020)建议利用对比学习来训练转化器模型,与作者方法类似
然而作者指出,这些方法一般需要数据增强技术,例如回译或训练数据的先验知识,而作者的方法不需要这一点。此外,作者专注于修改BERT以计算更好的句子嵌入,而不是从头开始训练一个语言模型。
另一方面,对比性学习也受到了计算机视觉接的广泛关注,作者通过优化其学习目标来改变Chen等人的框架,以实现基于Transformer的预训练的句子表示学习。这里说的就是SimCLR
2.2 Fine-tunning BERT with Supervision
要成功的fine-tune巨大的预训练Transformer模型绝对不是简单的事情,特别是当目标领域数据的数量有限时。为了缓解这其中的稳定性问题,已有一些研究者提出了各种方法。特别的,Gunel等人(2021)提出在目标任务的监督下,在微调BERT过程中利用对比学习作为辅助训练目标。相比之下,我们处理的是在没有这种监督的情况下调整BERT的问题。
也就是说作者这个方法好像不依赖于下游任务,直接用句子的representation进行CL?这里不确定作者最终评估的目标是不是直接就是BERT的那个表征token,而不微调下游,直接应用在一些能表征STS语义文本相似性指标的数据集上
2.3 Sentence Embeddings from BERT
由于BERT及其变体最初被设计为在每个下游任务上进行fine-tune以达到最优性能,因此如何从他们中提取一般句子的表征仍然是模糊的,这在不同的句子相关任务中广泛适用。
继Conneau等人(2017)之后,Reimers和Gurevych(2019)(SBERT)提议通过在BERT的最后一层进行平均池化来计算句子嵌入,然后在自然语言推理(NLI)数据集上对池化的向量进行微调(Bowman等人,2015;Williams等人,2018)。sentenceBERT
同时,其他一些研究集中在更有效地利用BERT中嵌入的知识来构建没有监督的句子嵌入。具体来说,Wang和Kuo(2020)提出了一种基于线性代数算法的池化方法,从BERT的中间层中抽取句子向量。Li等人(2020)建议从BERT最后两层获得的嵌入的平均值中学习一个使用流模型的球形高斯分布的映射,并利用重新分配的嵌入来代替原始BERT表示。
作者遵循Li等人(2020)的设置,在训练期间只利用纯文本,然而,与所有其他即使在训练后也依赖某种池化方法的人不同,我们直接完善了BERT,使典型的[CLS]向量可以作为句子嵌入的功能。
3. Method
Overview&some motivation
由于BERT大多需要某种类型的adaption以正确的应用于感兴趣的任务,因此,直接从BERT中得出句子的嵌入而不进行微调可能是不可取的。 虽然Reimers和Gurevych(2019)试图通过典型的监督微调来缓解这个问题,但我们限制自己以无监督的方式修改BERT,这意味着我们的方法只需要一堆原始句子来训练。只需要句子,不需要label,self-supervised?
在可能的无监督学习策略中,我们专注于对比性学习,对比性学习可以内在的促使bert意识到不同句子嵌入之间的相似性。考虑到句子向量被广泛用于计算两个句子的相似性,对比性学习所引入的归纳偏置有助于BERT在此类任务中的良好工作。问题是,句子层面的对比学习通常需要数据增强,或训练数据的先验知识,例如顺序信息以做出可信的正/负样本。我们试图利用BERT的隐藏表征来规避这些限制(指的是依赖多余的数据构建等限制?) ,这些表征很容易获得,作为嵌入空间中的样本。
3.1 Contrastive Learning with Self-Guidance
作者的目标是开发一种不受数据增强等外部程序影响的对比性学习方法。一个可能的接解决方案是在embedding空间中利用虚拟的对抗性训练,然而不能保证再加入NT-Xent随机噪声时,句子嵌入的语义会保持不变(However, there is no assurance that the semantics of a sentence embedding would remain unchanged when it is added with a NT-Xent random noise)。adversarial的方法自己感觉来说有一类的问题是生成的东西不够准确,或者说额外需要一个生成操作,这不像是数据增强那种感觉,所以对抗性训练的时候会有生成的额外开销和负担? 作为一种替代方法,我们建议利用来自BERT中间层的隐层表征,这些表征在概念上保证能够代表相应的句子。作者称我们的方法为self-guidance的对比学习,因为作者利用BERT本身的内部信号来微调它;

training的framework在上面这个图中被表示。首先把BERT拷贝为两份,并分别称作${\rm BERT}_F$(BERT-fixed)和${\rm BERT}_T$(BERT-tuned)。${\rm BERT}_F$ 在训练期间是固定的用来提供一个训练信号${\rm BERT}_T$是微调的以构建更好的句子嵌入。将${\rm BERT}_F$和${\rmBERT} _T$分开训练的原因是,我们想预先让${\rm BERT}_F$计算的训练信号不随着训练的过程而继续退化,这也在${\rmBERT}_T=={\rm BERT}_F$的时候经常发生这里是否可以理解为如果两个是一样的,那怎么都是一样的,肯定会越训练越差了 。上述的这一设计反映了我们的理念,即我们的目标是动态的混合存储在BERT不同层的知识,以产生句子嵌入,而不是通过额外的训练引入新的信息(这里应该指的是传统的fine-tune方式吧) 。请注意,在我们的设置中,来自${\rm BERT}_T$最后一层的[CLS]token,即${\rm c}_i$被认为是我们在微调期间/之后,旨在优化/利用的最终句子嵌入。
step2: 注意这个第二步是在${\rm BERT}_F$上的操作 第二步,给定b个sentence作为一个mini-batch,标记为$s_1,s_2,…,s_b$,分别把每句话$s_i$输入进${\rm BERT}F$中计算token-level的hidden representation$H{i,k}\in R^{len(s_i)×d}$ P.S. 第一次看到不标注公式号码的论文。。
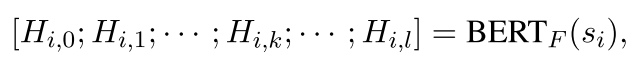
这里0<=k<=l, (作者对0层的解释是non-contextual layer,不知道指的是不是embedding后那个layer?),l代表BERT中隐层layer的数目,len(s_i)是这个tokenize sentence的长度,d是BERT的hidden_size。然后,在各个$H_{i,k}$之间使用一个池化操作(pooling function)$p$在所有BERT层中得出不同的句子级视图$h_{i,k}\in R^{d}$,这里$h_{i,k}=p(H_{i,k})$,最后通过采样策略$\sigma$获取一个$h_i$

由于我们在定义p和σ时没有具体的限制,employ max pooling as p and a uniform sampler as σ for simplicity
除非另有说明。对采样器的这种简单选择意味着每个hi,k都有相同的重要性,考虑到已知不同的BERT层专门用于捕获不同的语言概念,这是有说服力的(Jawahar等人,2019)。
step3:这个第三步指的是在${\rm BERT}_T$上的操作 ,计算$s_i$的sentence embedding $c_i$

其中$BERT(·)_{\rm [CLS]}$代表从BERT中最后一层获取的${\rm [CLS]}$token。
step4:随后我们将计算出的向量打包一下,然后和SimCLR中一样算一个loss,c_i,h_i就可以看做SimCLR中的两种aug方法

把所有$L_{m}^{base}$求和然后除以2b,并加入一个regularizer $L^{reg}=||{\rm BERT}_F-{\rm BERT}_T||_2^2$,以避免两个之间“太远了”(这里作者注解了,把bert第0层也fix住,为了stable learning),这些过程和SimCLR基本是很像的,除了加上了一个regularizer以外
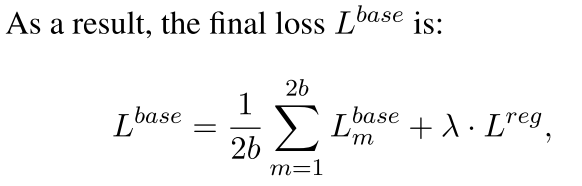
额外贴一个SimCLR的
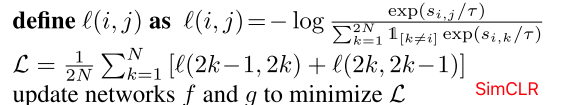
总而言之,我们的方法完善了BERT,使 句子嵌入ci与hi有较高的相似性,hi是句子si的另一种表示,在f投影的子空间中,与cj,j!=i和hj,j!=i相对不相似。训练完成后,我们删除除BERTT以外的所有成分,只用ci作为最终的句子表示。
3.2 Learning Objective Optimization
在第3.1节中,我们依赖于一般NT-Xent损耗的简单变体,该变化由四个因素组成。
在不丧失一般性的情况下,给定句子si和sj,因子如下(图3):
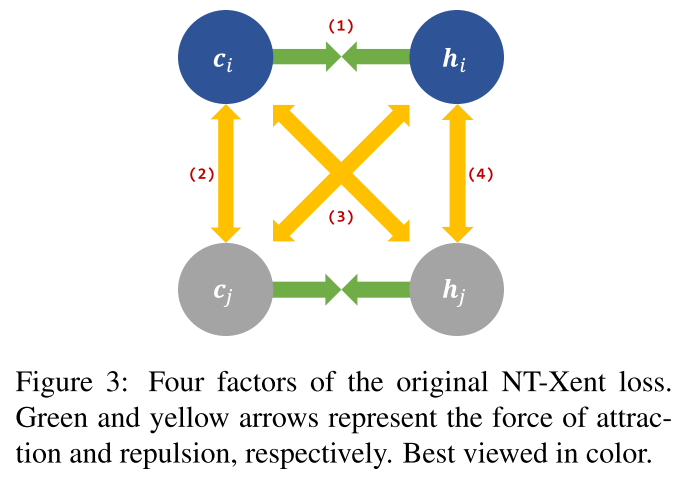

绿色和黄色的箭头代表吸引和排斥的力量,解释一下图里的四条边这个地方就是把NT-Xentloss又给画图表述了一下吧,感觉没什么创新
(1)$c_i$应当与$h_i$相互接近:主要的组成部分反映了我们核心的motivation,即BERT句子向量(ci)应该与BERT的中间视图(hi)一致。
(2)$c_i$应当与$c_j$相互排斥:使得两个句子得到的这些要远离
(3)$c_i$应当与$h_j$相互排斥
(4)$h_i$应当与$h_j$相互排斥
传统的拉进ci cj;;
尽管这四个因素都发挥了一定的作用,但有些成分可能是无用的,甚至对我们的目标造成了负面影响。一些研究工作(Chen和He(2020))指出在图像表示学习中,只有(1)是至关重要的,而其他的都是不重要的。同样地,我们对训练损失进行了三个主要的修改
第一:因为我们的目的是借助于hi来改善ci。我们重新定义我们的损失,更多地关注ci,而不是将ci和hi视为等同的实体。换句话说,”hi”的功能只是作为鼓励接近或远离的点。鼓励接近或远离,而不被认为是要优化的目标。这一修改的结果删除了(4)
把c_i作为anchor,而不是像SimCLR那样搞个互相的? 这样忽略掉h作为anchor对其他的
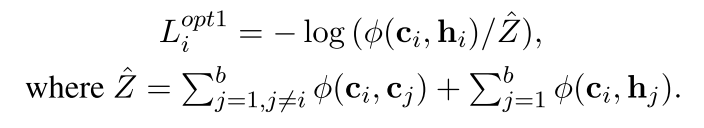
此外,我们发现(2)对于提高性能也是不重要的,因此得出了
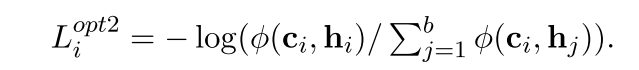
opt1和opt2分别去掉了hi hj之间的,ci和cj之间的,也就是(2) (4)
最后,我们将(1)和(3)的信号多样化,即允许多种观点{hi,k}来指导ci。这里也就是用了多层的$h_{i,k}$
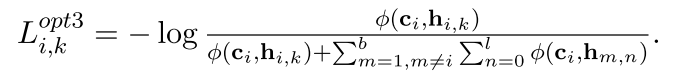
我们期望通过这一改进,学习目标可以通过考虑提供额外的(和免费的)样本来提供更精确和富有成效的训练信号。我们的优化损失的最终形式是。

opt1保留1,扔掉4;;opt2扔掉2;;;opt3加强3;;;这些都有一种以c_i作为anchor的感觉
ablation分别搞: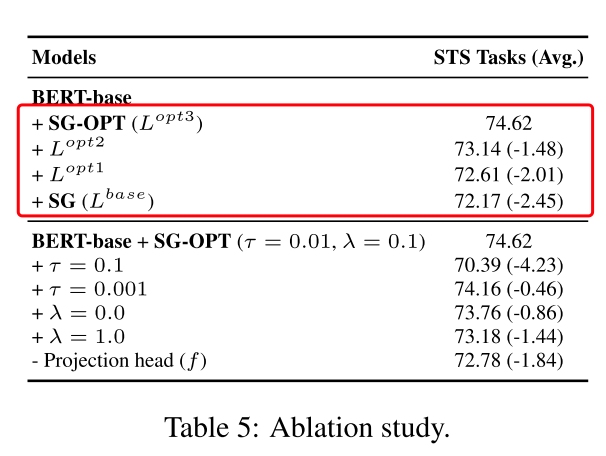
4. Experiment
4.1 General Configurations
在预训练的编码器方面,我们利用BERT(Devlin等人,2019)来处理英语数据集,而MBERT则是BERT的多语言变体,用于处理多语言数据集。(In terms of pre-trained encoders, we leverage BERT (Devlin et al., 2019) for English datasets and MBERT, which is a multilingual variant of BERT, for multilingual datasets.)
…
4.2 Semantic Textual Similarity Tasks


cosine similarity、Spearman correlation