naacl2022_Token-aware Contrastive Learning论文阅读
naacl2022_Token-aware Contrastive Learning论文阅读
TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning
TaCL:利用标记感知对比学习改进BERT预训练;
Token-aware CL,个人总结文章的亮点如下:
1)首次将对比性学习用于改进Transformer模型的token level表示(之前看到的一些好像都是句子级别的)
2)在token级别改善了各向异性这样一个问题,方法比较简单,并在GLUE这种比较广泛使用的数据集上取得了很好的效果;
reference
- NLP名词解释:各向异性(Anisotropic):https://zhuanlan.zhihu.com/p/468922604
- GLUE基准数据集介绍及下载:https://zhuanlan.zhihu.com/p/135283598
TODO-list
- 「MLM通常会输出token表示的各向异性分布,它占据表示空间的一个狭窄子集」这句话还不是很理解,可能需要看看作者在后面是怎么补充的。并且作者为什么说这些表征不理想,对于那些需要对不同token辨别语义的任务来说?原始方法的weakness在哪?
参照博客中的解释,「Anisotropic means word embeddings occupy a narrow cone in the vector space」,也就是说“各向异性”表示词嵌入在向量空间中占据了一个狭窄的圆锥形体(还不是很懂)
各向异性:在向量空间上的含义就是分布与方向有关系,而各项同性就是各个方向都一样,一些学者的研究发现Transformer学到的词向量在空间的分布是这个样子的:
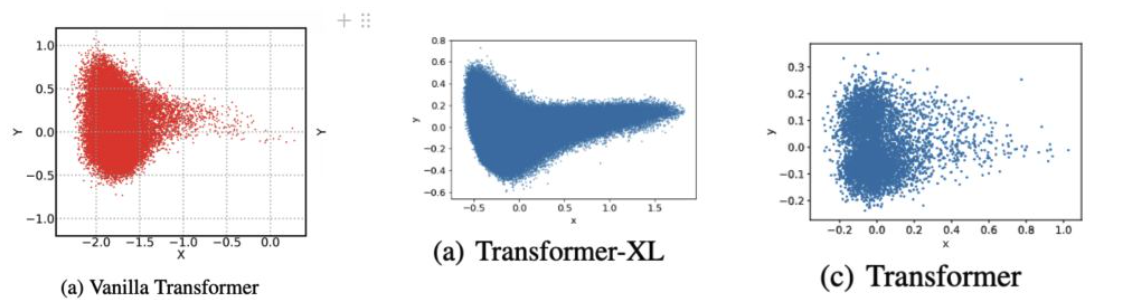
各向异性的缺点在于,最后学到的向量都挤在一起,彼此之间的余弦相似度很高,并不是一个很好的表示。一个好的表示应该同时满足Alignment和Uniformity,前者表示相似的向量距离应该相近,后者表示向量在空间上应该尽量均匀,最好是各向同性的
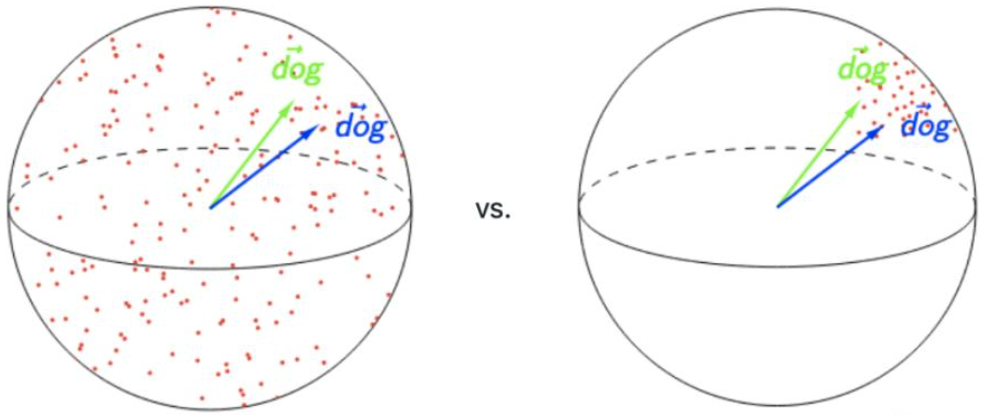
左图是理想的表示,右图则有各向异性的缺点。
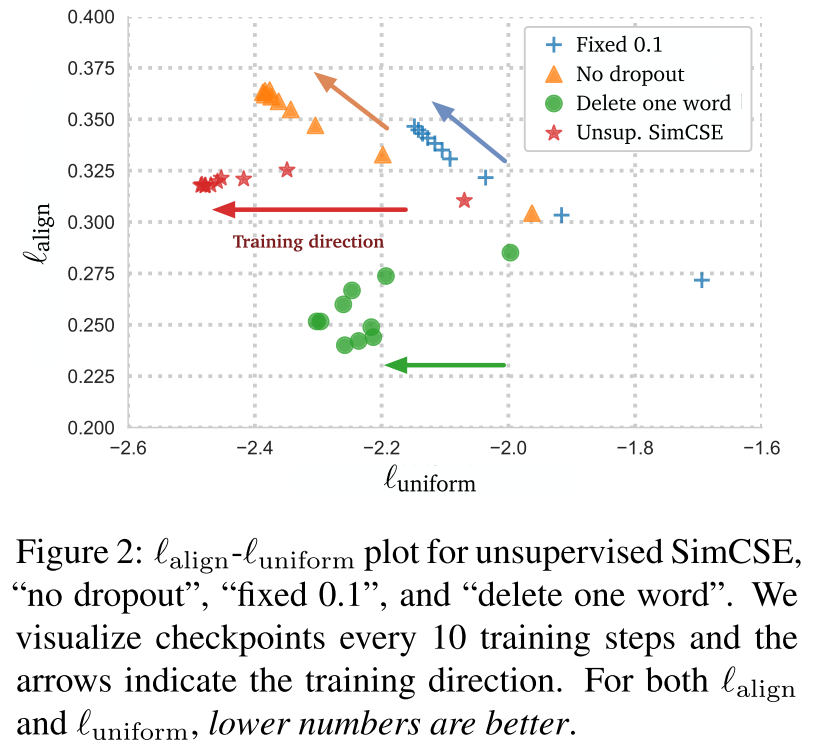
此外补充,SimCSE的方法,作者认为通过那个简单dropout的监督,满足了更好的alignment和uniformity(下图来自SimCSE,在训练过程中keep了alignment,减小了各向异性使得更加uniform)
这种token级别的任务,在下游的句子级别任务上是怎么微调的,因为很多只用CLStoken的话, 这种各向同性,各向异性的分布就在MHSA的过程中被解释过去了?作者没有解释好像,具体这个是怎么用的,在对比实验中也没有做比如CLStoken,还有一句话取平均这样不同方法的效果,是否需要发邮件问问?
改善了整个bert的表征,Improving BERT … 对比学习为什么是有效的,表征空间 词转化成one-hot,映射成表征空间后,希望所有的词,几万个词在字典的分布应该是比较分散的(各向同性)-> 对比学习的基本思想;;预训练模型给了一个很好的初始化,
这种从token级别简单的对比学习,似乎有明显的缺点?比如一句话中存在的指代关系,还有一些同义词,貌似没有处理?待讨论
0.Abstract
在过去的几年里,像BERT这样的Masked Language Modeling语言模型已经彻底改变了自然语言理解领域。然而,现有的预训练MLM通常会输出token表示的各向异性分布,它占据表示空间的一个狭窄子集。(这个话还不太明白,在TODO-list中解决吧) 这样的标记表征并不理想,特别是对于那些需要对不同标记进行辨别语义的任务来说。(同样不明白,哪些任务需要对不同标记进行辨别语义,比如NER类的?但那种是序列建模的任务,和CL感觉本质上不是很像)
在本文中我们提出TaCL(Token-aware Contrastive Learning,利用标记感知对比学习改进BERT预训练),一种新的持续的预训练方法,鼓励BERT学习各向同性的和有鉴别力的符号表征分布。TaCL是完全无监督的(fully unsupervised),不需要额外的数据。
我们在大量的英文和中文benchmarks上测试了我们的方法,结果表明,TaCL比原来的BERT模型带来了一致和明显的改进。此外,我们还进行了详细的分析,以揭示我们方法的优点和内部工作原理。
连续学习,提升bert的表征能力,学到更均匀的表达,
1. Introduction
自从BERT的兴起,掩码语言模型(Masked Language Modeling,MLM)已经成为几乎所有自然语言理解任务的事实上的主干。尽管它们取得了明显的成功,但许多现有的以MLM目标预训练的语言模型都存在着各向异性的问题《How contextual are contextu- alized word representations? comparing the geome- try of bert, elmo, and GPT-2 embeddings.》。也就是说,他们的标记表示位于表示空间的一个狭窄的子集,因此在捕捉不同标记的语义差异方面,辨别力较差,功能较弱。
通过博客还有一些其他资源的学习,如果不满足各向异性的话,可能所有token之间的意思都非常相近,那么不同token 的语义差异辨别力确实会差一些
最近,通过无监督的句子级对比学习来不断训练MLM,取得了很大的进展,目的是为了创造出更有辨识度的句子级句子表征。(使得具有语义相似的句子靠的更近,语义不同的句子距离较远,也就是对比学习本质上的motivation,这是一个在句子级别上的motivation和实践) 然而,这些表征值被评估为句子嵌入,没有证据表明他们会对其他成熟的NLU任务有益。我们表明,这些方法的对像SQuAD这样具有挑战性的任务几乎没有任何好处。SQuAD是机器阅读理解任务的数据集,之前类似SimCSE的评测都是在STS那种数据集上的,那种数据集有一种衡量embedding好坏的感觉,还不是太过于涉及下层任务?
在本文中,我们认为,获得更具辨别力(discriminative)和可转移性(transferrable)的表征的关键在于对比学习性和同向性的token-level的特征。为此,我们提出了TaCL(利用标记感知对比学习改进BERT预训练),这是一种新的持续的预训练方法, 鼓励BERT学习更具辨别力的token表征。
下面这块开始比较重点说方法的,大概能初步了解下方法
具体来说,我们的方法设计两个模型(一个学生和一个教师),它们都是由同一个预先训练好的BERT初始化的。在学习阶段,我们冻结教师的参数,并不断优化学生的模型:(1)原来BERT所具有的MLM和NSP训练目标;(2)新提出的TaCL训练目标。TaCL损失是通过对比学生对被掩码的标记的表述和教师在没有掩码输入标记的情况下产生的“参考”表述而得到的。在图1中,我们对方法进行了阐述。

这张图一眼看过去的话是一个token level的,一个被掩码的token的表征应当更接近teacher给出的那个未被掩码词的表征,而原理其他词的表征
换句话说,这里是token级别的各向异性优化?而SimCSE像是sentence级别各向异性的优化!!!
我们在广泛的英文和中文基准数据集上广泛地测试了我们的方法,并说明TaCL在大多数评估的数据集上带来了明显的性能改进(3.1.1节)。这些结果验证了更具辨别力和各向同性的标记能带来更好的模型性能。此外,我们还强调了与目前最先进的句子级别技术对比,在NLU任务中使用我们标记级方法的好处(3.2.1节)。我们进一步分析了TaCL的内部运作和它对标记表示空间的印象(3.2.2节)。
这里的3.2.1节看起来是和SimCSE作为baseline motivation十分接近的方法,使用token级别,优化句子级别,超越SimCSE?
据我们所知,我们的工作是首次将对比性学习用于改进Transformer模型的token level表示。我们希望这项工作的发现能够促进对比学习和表征学习在更细粒度上的交叉方法的进一步发展。
2. Token-aware Contrastive Learning
我们的方法包含一个学生模型S和一个教师模型T,两者都是从相同的预训练BERT模型中初始化的。在训练过程中我们固定T的参数,只优化S的参数。给定序列x=[x1, x2, …, xn],我们使用与BERT作者(devlin等)相同的程序随机掩码x,并将掩码后的序列x~送入到学生模型中,以产生上下文表征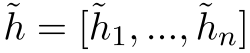 。同时,将未掩码的序列x输入到模型T中获取
。同时,将未掩码的序列x输入到模型T中获取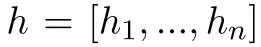 ,这一过程如figure1所示。所提出的标记感知对比性学习目标$L_{TaCL}$被定义为式1:
,这一过程如figure1所示。所提出的标记感知对比性学习目标$L_{TaCL}$被定义为式1:


这里说的是只把mask掉的作为一个token级别的anchor
在直觉上,学生学会了使被掩码的标记的表示更加接近于教师产生的“参考”表示,而远离同一序列中的其他标记。(这是对比学习这样一个任务的特性) 因此,学生学到的标记表征对不同的标记更具辨别力,因此更能遵循各项同性的分布。同BERT作者一样,我们将MLM和NSP同样加入损失函数中,在持续的预训练阶段,学生模型的总体学习目标$L$被定义为:
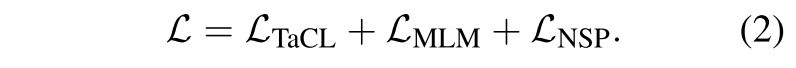
请注意,学生的学习是完全无监督的,可以使用原始的预训练语料库来实现。学习完成后,我们在下游任务中对学生模型进行微调。
3. Experiment
对于英文的基准数据集,我们使用BERT_base还有BERT-large模型。对于中文的基准数据集,我们使用BERT_base模型。超参数的设置作者描述如下:
After initializing the student and teacher, we continually pre-train the student on the same Wikipedia corpus as in Devlin et al. (2019) for 150k steps. The training samples are truncated with a maximum length of 256 and the batch size is set as 256. The temperature τ in Eq. (1) is set as 0.01. Same as Devlin et al. (2019), we optimize the model with Adam optimizer (Kingma and Ba, 2015) with weighted decay, and an initial learning rate of 1e-4 (with warm-up ratio of 10%).
3.1 Evaluation Benchmarks
对于英文,作者使用了GLUE数据集,以及SQuAD1.1 2.0数据集——评估该模型在token级答案提取任务中的表现的数据集。报告了精确匹配(EM)和F1得分的dev集结果。
对于中文,作者使用了NER(named entity recognition)和CWS(chinese word segment)这两个相关的任务。
个人笔记——GLUE数据集中的各个任务介绍
对于英文的基线数据集,我们使用GLUE数据集,其中包含各种句子级分类任务。参考博客中的学习来说:为了让NLU任务发挥最大的作用,一些机构创建了一个多任务的自然语言理解基准和分析平台,就是GLUE(General Language Understanding Evaluation)。其中包括9项NLU任务,涉及到自然语言推断、文本蕴含、情感分析、语义相似等多个任务。
作者的方法是token级别的,在这些句子级别的任务上,他是怎么应用转化过来的?下文如果看到的话会补充在TODO-list中
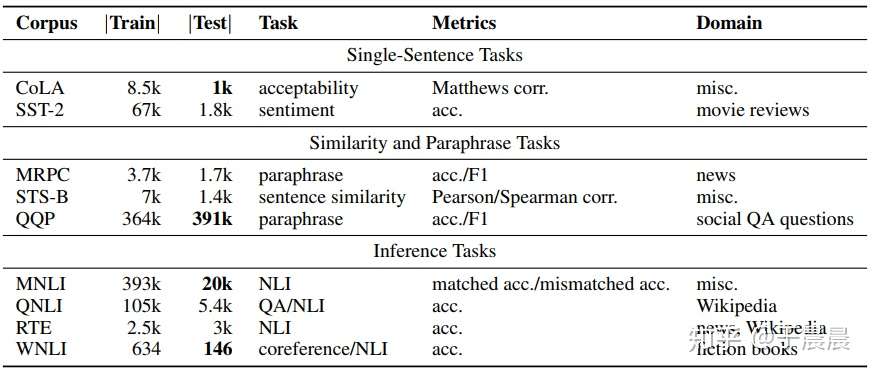
CoLA:The Corpus of Linguistic Acceptability,语言可接受性语料库,单句子分类任务,每个句子被标注为是否合乎语法的单词序列。任务是一个二分类任务,标签共两个,0表示不合乎语法,1表示合乎语法;
SST-2:The Stanford Sentiment Treebank,斯坦福情感树库,单句子分类任务,包含电影评论中的句子和他们情感的人类注释。类别包括正面情感和负面情感。即针对句子级别,分为正面情感和负面情感;
MRPC:The Microsoft Research Paraphrase Corpus,微软研究院释义语料库。相似性和释义任务,是从在线新闻源中自动抽取句子对语料库,并人工注释句子对中的句子是否在语义上等效。类别不平衡,68%的正样本。标签为1代表两句话互为释义,标签为0代表两句话不互为释义;
STS-B:The Semantic Textual Similarity Benchmark,语义文本相似性基准测试,相似性和释义任务,是从新闻标题、视频标题、图像标题以及自然语言推断数据集中提取的句子对集合,每对都是由人类注释的,其相似性评分为0-5(大于等于0且小于等于5的浮点数)。任务就是预测这些相似性得分,本质上是一个回归问题,但是可以归类为句子对的5分类任务;
QQP:The Quora Question Pairs,Quora问题对数据集,任务是确定一堆问题在语义上是否等效;
MNLI:The multi-genre natural language inference corpus,是通过众包方式队进行文本蕴含标注的集合,给定前提(premise)语句和假设(hypothesis)语句,任务是预测前提语句是否包含假设(蕴含,entailment),与假设矛盾(contradiction),或者两者都不(中立,neutral)。前提语句是从数十种不同来源手机的;
QNLI:Question-Answering NLI,判断问题(question)和句子(sentence,维基百科段落中的一句)是否蕴含,蕴含和不蕴含的二分类任务;
RTE:The Recognizing Textual Entailment datasets,自然语言推断任务,将一系列挑战赛数据集整合而来,判断句子1和句子2是否互为蕴含,二分类任务;
WNLI:Winograd NLI,Winograd自然语言推断,判断句子对是否相关,蕴含和不蕴含,二分类任务;
感觉这些方法都是句子级别上的一些下游任务,也都是NLU领域上一些下游任务,任务特点和NER那类的不是很相关;
个人笔记——SQuAD数据集
机器阅读理解相关
※这里记录一些Experiment章节中的重点内容
- 主实验结果
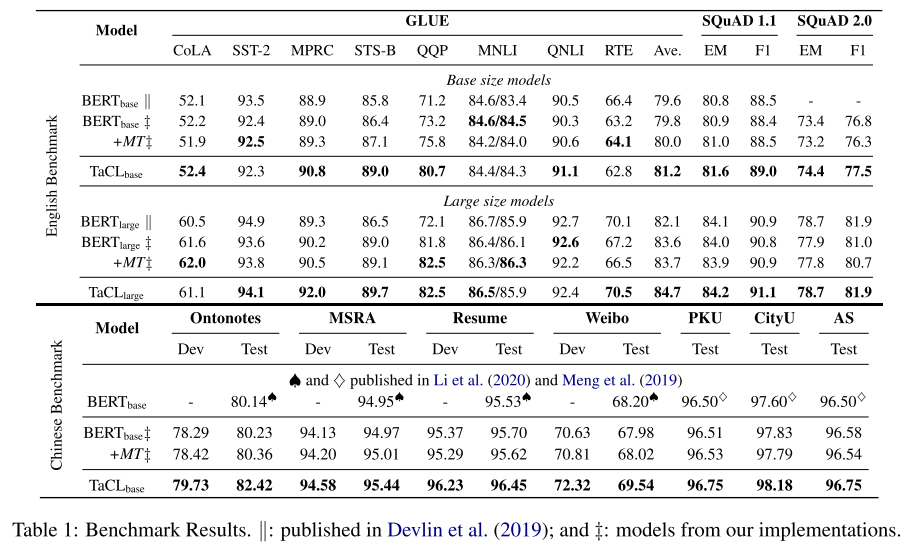
表1:BERT+MT代表BERT with more training(by continually pre-training the original BERT on Wikipedia for 150k steps3 using the original BERT pre-training objectives);双竖线代表作者原文报告的指标,++代表复现的指标;
这些结果表明,学习各向同性的标记表示空间有利于模型的性能,特别是在以token为中心的任务上这里指的是作者自己补充的一些数据集? 。
这里还是很关心,这种token级别的方法,作者是咋用到句子级的任务上的啊?
- 和其他一些sentence级别方法的对比:

This could be attributed to the fact that such methods only focus on learning sentence-level representations while ignoring the learning of individual tokens
这可能是由于这类方法只注重学习句子层面的表征,而忽略了对单个标记的学习。这种行为对于像SQuAD这样需要信息性标记表示的任务来说是不可取的。
尽管如此,消减的模型-1表明,原始的BERT预训练目标(LMLM和LNSP)在一定程度上弥补了句子级对比方法造成的性能下降。
另一方面,消减的模型-2表明,我们的标记意识对比目标通过学习更好的标记表征,帮助模型取得更好的结果
- Token Representation Self-similarity,token表征的自相似性

其中hi和hj是由模型产生的xi和xj的标记表示。直观地说,较低的s(x)表明序列x中的标记的表征彼此之间的相似度较低,因此具有较强的辨别力。也就是说一个只该和自己的表征比较相近
这里感觉有个很大的问题,就是说指代关系,或者it那些词的话,他们应当是互为正例的?在一句话中的指代,以及一些同义词,这个作者是否忽略掉了?
我们从中文和英文维基百科中抽取了5万个句子,并计算了不同层次上的表征的自相似性。图2显示了TaCLbase和BERTbase在所有句子中的平均结果。我们看到,在中间层,TaCL的自相似度比BERT的高。相反,在顶层(第12层),TaCL的自相似性明显低于BERT的自相似性,这表明TaCL的最终输出标记表示更具有辨别力
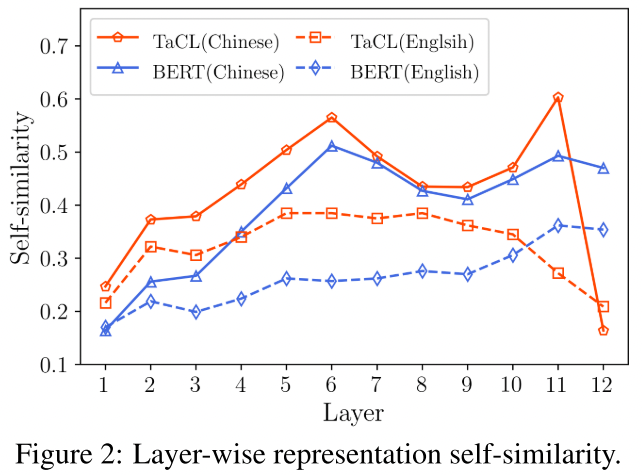
最后的chinese 11-12层降幅很大啊
- Qualitative analysis:
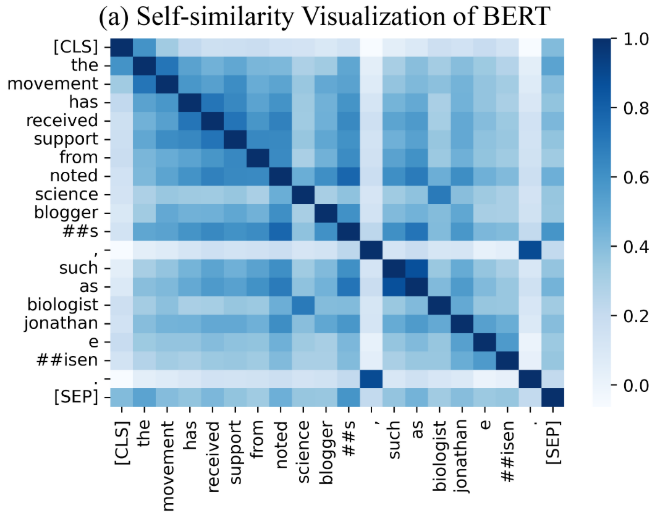
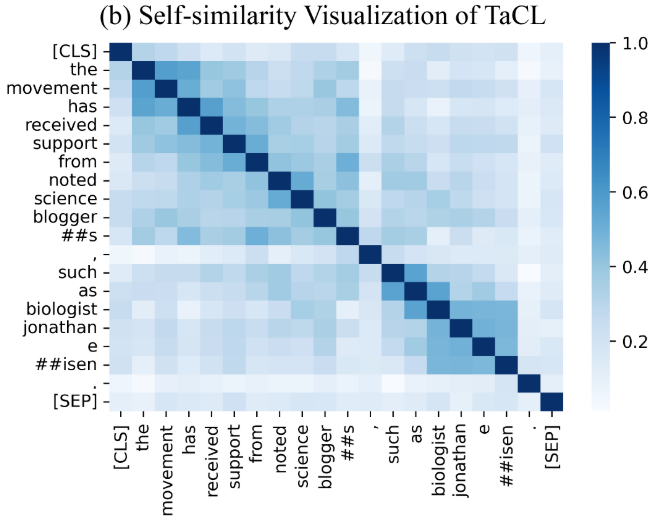
Figure 3: Self-similarity Matrix Visualization: (a) BERT and (b) TaCL. (best viewed in color)
我们看到,与BERT(图3(a))相比,TaCL(图3(b))的自相似性在对角线外的部分要低得多。这进一步突出了TaCL的单个标记表示更具有辨别力,这反过来导致了模型性能的提高,正如所证明的那样
还是觉得有个很大的问题,是不是某些词就应该表征更加接近的,比如a中很明显的逗号和句号
4. Conclusion
在这项工作中,我们提出了TaCL,一种新的方法,应用标记感知的对比学习来持续地对BERT进行预训练。我们在广泛的英文和中文基准上进行了广泛的实验。结果表明,我们的方法在所有被评估的基准上都带来了明显的性能改进。然后,我们深入研究了TaCL的内部工作,并证明我们的性能提升来自于更有鉴别力的标记代表的分布。
证明手段似乎有些单薄