naacl2022_Entity-aware CL for sentence emb论文阅读
naacl2022_Entity-aware CL for sentence emb论文阅读
EASE:Entity-Aware Contrasitve Learning of Sentence Embedding
实体感知的对比学习用于句子的embedding表征
Entity-aware CL for sentence embedding,个人总结文章的亮点如下:
1)hyperlink entity这个运用的很巧妙,因为维基百科这个超链接在多语言都是一样的,相当于一种能够额外获取得到的标注了,在这种超链接的引导下构建了自监督获取的positive pair;
2)同样因为hyperlink entity和维基百科的数据特点,使得具有多语言可以对齐的语料进行数据训练;
3)做实验的数据集非常全面,分为单语/多语,内部有STS、STC、还有许多跨语言的数据集;
reference
-
TODO-list
- 多语言环境一般数据集指的是什么样的,是不同语言混到一块吗还是怎么样?
- 多语言目前了解的还有点少,有些不清楚多语言相关的是在做什么,是多语言共用一个模型吗?
- 待讨论:这些测试集的结果,是不是都是先完成基准的预训练后,然后再拿给下游模型做fine-tune的这样一个训练过程,或者STS那种是预训练完了后就直接评估,但是一些下游带着标签的,就是还要fine-tune一下的?
- 似乎一些引用的是自己复现的指标,这种在可信性上感觉会有一定问题?
0. Abstract
我们提出了EASE,一种通过句子和其相关实体之间的对比学习来学习句子嵌入的新方法。使用实体监督的好处有以下两点:(1)实体已经被证明是文本语义的一个强有力的指标,因此应该为语义嵌入提供丰富的训练信号;(2)实体的定义是独立于语言的,因此提供了有用的跨语言对齐监督;
这里背后的motivation会不会有,一句话的实体对整个语义是更加重要的?
我们对EASE与其他无监督模式在单语言和多语言环境中进行了评估。我们表明EASE在英语语义文本相似性(STS)和短文聚类
(STC)任务中表现出有竞争力或更好的性能,并在多语言环境中,它在各种任务中的表现明显优于基线方法。
多语言环境一般数据集指的是什么样的,是不同语言混到一块吗还是怎么样?(这个问题加到todo-list里面去了)
1. Introduction
目前学习句子嵌入的主流方法使用特定的的训练监督来微调通用的与训练语言模型,如BERT。监督的类型可以是自然语言推理数据,相邻的句子,或多语言模型的平行数据库。
这里说的是一个pretraining - fine tuning的过程
在本文中,我们探讨了一种监督的类型,在文献中还没有被充分探讨过的监督类型:来自维基百科的实体超链接注释(entity hyperlink annotations)。该种方式的优势有两个方面:(1)实体已经被证明是文本语义的一个有力的指标,因此应该为句子嵌入提供丰富的训练信号;(2)实体的定义是独立于语言的,因此提供了一个有用的跨语言对齐监督。维基百科广泛的多语言支持减轻了对平行资源的需求,以训练对齐的多语言句子嵌入,特别是对于低资源语言。为了证明基于实体监督的有效性,我们提出了EASE(实体感知的对比学习用于句子的embedding表征),他在单语和多语的环境下都能产生高质量的句子嵌入。
到这里还是一个详细版的abstract,多语言这块强调的很多
EASE学习句子嵌入,有两类目标:(1)我们新颖的实体对比学习损失函数,在句子和他们相关的实体之间,图1;(2)自监督的对比学习损失,加入dropout的noise;
- 实体CL的目标是将句子与其相关实体的嵌入拉近,同时将不相关的实体分开,该目标预计将根据实体所捕获的语义来安排句子的嵌入。为了进一步利用维基百科中的知识并改进学习到的嵌入,我们还引入了一种基于实体类型的硬性否定词挖掘方法;
- 第二个目标,即带有dropout噪声的自监督CL目标,与第一个目标相结合,使得句子嵌入能够捕获细粒度的文本语义;这里引用了SimCSE
我们将我们的模型与其他最先进的无监督的句子嵌入模型进行了评估,并表明EASE在语义文本相似性(STS)和短文聚类(STC)任务上表现出有竞争力或更好的性能。
和知识图谱结合?
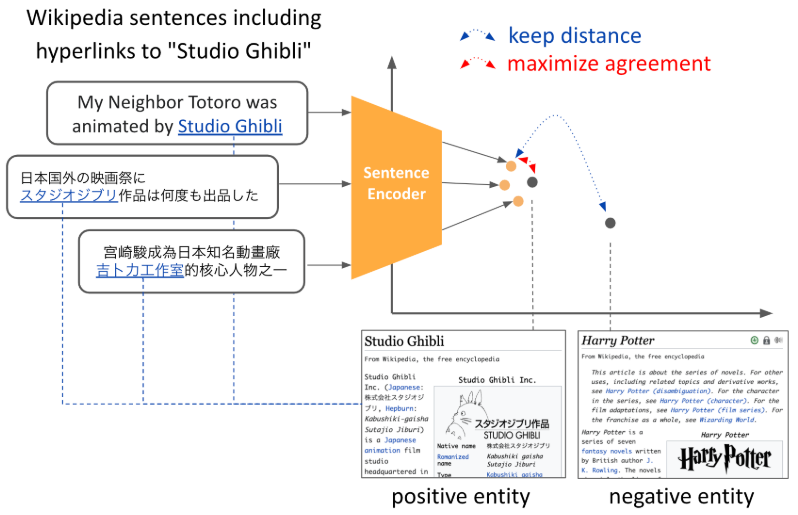

图1:EASE背后的主要概念说明。使用一个对比学习框架,句子的嵌入其超链接实体的临近区域,而与不相关的实体分开。在此,我们为多语言模型分享不同语言的实体嵌入,以促进表示的跨语言对齐。
读到这里才明白,这里这个超链接实体运用的很巧妙,就是维基百科什么的一般会有那个超链接,然后把这个超链接实体的信息运用上了;相当于一种能够额外获取得到的标注了,还能在多语言之间对齐
我们还将EASE应用于多语言环境。为了便于评估多语言句子嵌入的高级语义,我们构建了一个多语言文本聚类数据集,MewsC-16(16种语言的多语言新闻短文聚类数据集)。多语言EASE是使用各语言共享的实体嵌入进行训练的。我们表明,鉴于来自共享实体的跨语言对齐监督,多语言EASE在多语言STS、STC、平行句子匹配和跨语言文档分类任务中明显优于基准。
我们进一步证明了多语言实体CL在低资源语言的一个更现实的场景中的有效性。利用多语言实体法,我们对一个有竞争力的多语言句子嵌入模型LaBSE(Feng等人,2020)进行了微调,并表明该调整提高了该模型所支持的低资源语言的平行句子匹配性能。
最后,我们通过研究EASE模型和句子嵌入的多语言特性来分析该模型。消减的模型和句子嵌入的多语言特性,以阐明模型改进的来源。
多语言任务目前了解还比较少,有点不清楚是怎么做的各个操作,加入到todo那里了
2. Related Work
主要从2.1 Sentence Embedding、2.2 Contrastive Learning、2.3 Multilingual Sentence embeddings三个方面来说
2.1 Sentence Embedding
句子嵌入,即使用稠密向量的形式表示句子的含义已经得到了积极的研究。最早的方法之一是段落向量,其中句子嵌入被训练来预测文本中的单词。随后人们探索了各种训练任务,包括重建或预测相邻的句子和解决自然语言推理(NLI)任务。
最近,随着BERT等通用预训练语言模型的出现,对预训练模型进行微调以产生高质量的句子嵌入变得越来越普遍,重新审视上述的监督信号,并使用基于对比学习(CL)的自我监督目标。在本文中,我们提出了一个基于实体监督的CL目标。我们用实体CL和带有dropout噪声的自我监督CL来训练我们的EASE模型,并表明实体CL提高了句子嵌入的质量。
Contrastive Learning:对比表示学习的基本思想是将语义相似的样本拉近,将不相似的样本分开。句子嵌入的对比学习可以根据所使用的positive pair的类型进行分类。作为代表性的例子,有几种方法在NLI数据集中使用“蕴含”对作为positive pair。
为了减轻对注释数据集的需求,自监督方法也在被积极研究。典型的自我监督方法涉及使用数据增强技术生成positive pair,包括离散操作,如单词删除、shuffle,回译,中间的BERT隐藏表示,以及transformer层内的dropout噪音(SimCSE)。
Contrastive tension (CT)-BERT将两个单独编码器对同一句子的输出视为正对。DeCLUTR使用同一文件的不同span。与这些在句子之间进行CL的方法相比,我们的方法在句子和其相关实体之间进行CL。 换句话说,也是一种构建positive pair的方法
Multilingual sentence embeddings(多语言的话语embedding):另一个与之密切相关的研究方向是学习多语言的句子嵌入,这些句子嵌入可以捕捉到多种语言的语义。早期有竞争力的方法通常利用序列对序列的目标与平行语料库来学习多语言句子嵌入;最近微调的多语言预训练模型已经取得了最先进的性能。然而,这类方法的一个缺点是,为了对某一特定的语言对取得强有力的结果,它们需要丰富的平行或语义相关的句子对,而这不一定容易获得。在这项工作中,我们探索了维基百科实体注释的效用,这些注释是跨语言对齐的,并且已经有300多种语言。我们还表明,在多语言情况下,实体注释有效地改善了英语和低资源语言之间的句子嵌入的一致性,而现有的多语言模型并不支持这种一致性。
再次强调了一下这里在多语言上的贡献,主要是这种多语言“标注”易于获得
2.2 Learning Representations Using Entity-based Supervision
实体已经被习惯性地用于建立文本语义模型。最近提出的一些方法通过从实体的相关文本或实体掩码的句子中预测实体来学习基于实体的监督的文本表示。在提出的EASE模型中,现有的基于BERT的自监督CL方法被扩展,使用基于实体的监督和精心设计的硬否定句,hard-negative。此外,通过利用实体的语言无关性,它被应用于多语言环境。
感觉总结下来是这三大贡献:超链接的引导下自监督获取这种positive pair、多语言的数据易于获取、精心设计hard-negative
3. Model and Training Data
在本节中,我们描述了我们的句子嵌入学习方法EASE的组成部分,该方法使用维基百科中的实体超链接注释进行训练;
3.1 Contrastive Learning with Entites
给出一个句子和一个语义相关的positive实体对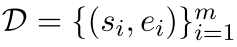 ,我们训练我们的模型来预测句子实体表征$e_{i} \in R^{d_e}$,从句向量表征$s_{i} \in R^{d_s}$中。按照Chen等人SimCLR的对比学习框架,我们对N个配对的mini-batch $(s_i, e_i)$,通过下式计算训练损失:
,我们训练我们的模型来预测句子实体表征$e_{i} \in R^{d_e}$,从句向量表征$s_{i} \in R^{d_s}$中。按照Chen等人SimCLR的对比学习框架,我们对N个配对的mini-batch $(s_i, e_i)$,通过下式计算训练损失:
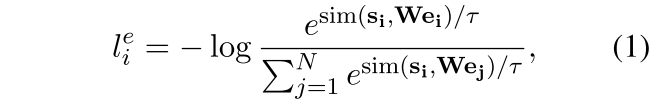
其中$W \in R^{d_e×d_s}$是一个可学习的矩阵参数一句话的表征和其中一个实体的表征两者互为接近这个在感官上感觉不是很有道理啊,所以在这里加入了一个W来平衡这个事情?也就是说一个词经过一个学习来变成一个句子的?如果从扩展来说这里会不会可以搞成多个词的,或者做一个词义选择后来怎么搞一下 。$\tau$是温度超参数,sim(·)使用的是cosine相似度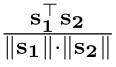 。
。
- Data:我们从2019年1月版本的维基百科转储中构建句子-实体配对数据集。我们使用ployglot将文章中的文本拆分为句子。对于每个句子,我们提取超链接实体作为语义相关的实体[脚注:在初步实验中,我们还尝试从实体和其页面上的第一句话中构建实体-句子配对数据,结果发现目前的方法表现更好]。每个实体都构成了该句子的一个训练实例 $(s_i, e_i)$。我们把实体限制在那些在训练语料库中作为超链接出现十次以上的实体。它们被转换为维基数据实体,利用从2020年3月版本的维基数据转储中获得的语言间链接,在不同语言间共享[脚注:https://en.wikipedia.org/wiki/Help:Interlanguage_links]。
3.2 Hard Negative Entites
自己对Hard Negative的理解是更难学一点的样本,比如在NLI那边的针对那句话的矛盾可以是一个特殊的Hard Negative,在权重的时候多分配一些
根据前人的研究,引入Hard Negative(与anchor难以区分的数据这里是不是不太对 )对改善CL模型是有效的。我们引入了一种hard negative挖掘方法,可以找到与正面实体相似但与句子无关的负面实体。**这里作者理解的hard negative是难区分的样本,而不是那种应当更加原理的样本**
具体来说,对于每个正面实体,我们收集满足以下两个条件的硬性负面实体候选:
- 具有相同类型的实体被作为positive的实体(entities with the same type as the positive entity);按照Xiong等人的工作,实体类型被定义为Wiki数据上“实例instance of ”关系中的实体。如果有不止一种合适的类型,我们会随机选择一种;有一种父层级选择的感觉
- 不出现在同一维基百科页面上的实体;不在一个界面出现,那么可能就不是很相关的感觉 这里我们的假设是,同一页面上的实体与正面实体在主题上相关,因此不适合作为负面数据。最后我们随机选择其中一个候选来构建硬性的负面训练数据。
例如,”吉卜力工作室 “实体的类型是 “动画工作室”,而硬性否定的实体候选者之一是 “华特迪士尼动画工作室”(For example, the “Studio Ghibli” entity has the type “animation studio” and one of the hard negative entity candidates is “Walt Disney Animation Studios”)
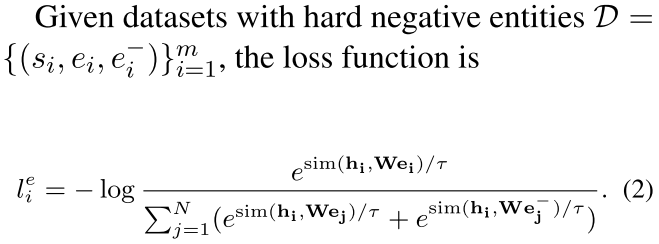
对于一个句子的表征hi,他和ei应该接近,而在分母这里要同时和所有ej-和ej远离,这里会不会也有问题,就是负负得正了,比如ej-和ei在同个wiki页面中出现了?
3.3 Pretrained Entity Embeddings
我们使用在维基百科上预训练的英语实体嵌入来初始化实体嵌入。这些嵌入是使用开源的Wikipedia2Vec工具和2019年1月的英文维基百科转储来训练的。向量维度被设置为768,这与基础预训练模型的隐藏表征相同,其他超参数为其默认值。实体嵌入矩阵的参数nn.Embeddings() 在训练过程中被更新。
这里怎么还是感觉很怪,这个Wikipedia2Vec工具是EMNLP2020年demo的论文,去翻了一下感觉他表示出来的内容不一定借助了BERT,那么这篇论文里实体表征空间会不会和句子的表征空间是不一样的?只是维度一样?所以在这里作者加入了一个W来做一个线性变换,期望能学习变换到相同的空间?
这里应该本质上就是一个Embedding层,用one-hot那种+词表来实现的;
3.4 Self-supervised Contrastive Learning with Dropout Noise
这里是SimCSE上提出的dropout noise,在SimCSE中,一句话输入两次在不同dropout的作用下生成两个表征,两个表征之间互为正例
有dropout噪声的self-supervised CL,它把一个句子放进去,用dropout作为噪声来预测自己,是一种以无监督方式学习句子嵌入的有效方法。我们将这个方法加入到我们的实体CL方法中。
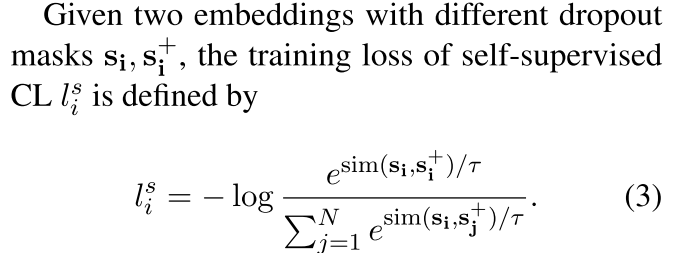
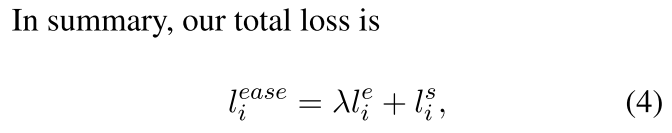
自己组合一个,最终的损失函数被如下表示:
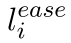 =
=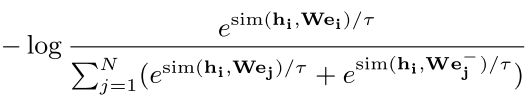 +
+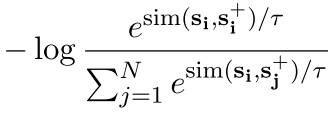
句子-实体之间的对比损失,加上句子-句子之间的对比损失(SimCSE)
4. Experiment: Monolingual(单语-英语)
我们首先在单语环境中评估EASE,我们仅使用英语维基百科数据对单语预训练的语言模型进行微调。
exp章节选一些比较关键内容选写在这里
4.1 Setup
选用100w的pairs的英语entity-sentence作为训练数据。在这个设置下,我们从BERT或者RoBERTa的checkpoint上训练sentence embedding,并选用[CLS]作为一句话的sentence embedding。我们只在训练的时候在output sentence embedding后面加入一个线性层,这与SimCSE的设置相同。
我们将我们的方法与无监督的句子嵌入方法进行比较,包括GloVe的平均嵌入(Pennington等人,2014)、原始BERT或RoBERTa的平均嵌入,以及之前最先进的方法,如Sim- CSE(Gao等人,2021)、BERT-CT(Carlsson等人,2021)和DeCLUTR。
我们使用两个任务来评估句子嵌入 任务。STS(Semantic Textual Similarity)和STC(Short Text Clustering)。这些任务被认为是衡量句子嵌入的程度,以涵盖细粒度和广泛的语义结构。
- STS:STS是对捕捉句子分级相似性的能力的一种衡量标准
- STC:句子嵌入的另一个方面是捕捉分类语义结构的能力,即把同一类别的句子紧紧地贴在一起,而把不同类别的句子远远地分开。
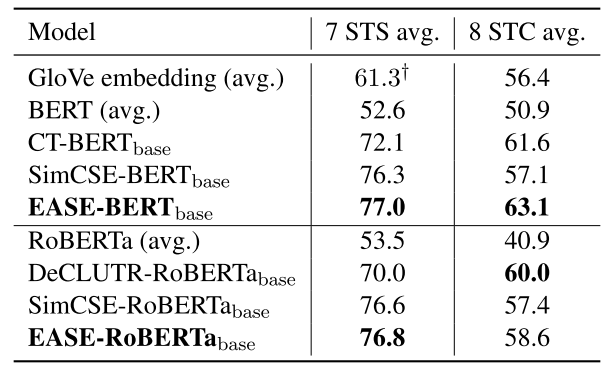
4.2 Results
实验结果如下,这里作者应该只说了是部分sota,然后展现了有竞争力的性能


5. Experiment: Multilingual
为了进一步探索实体注释作为跨语言对齐监督的优势,我们在多语言环境中测试了易用性:我们使用多种语言的维基百科数据微调多语言预训练语言模型。维基百科自动提供了这个,并且是相对对齐的数据
5.1 Setup
我们为每种语言抽取50000对样本,并将它们一起用作18种语言实体-句子配对数据的训练数据
这样综合在一起的话大概是100w这个数据级别
【脚注:We chose 18 languages (ar, ca, cs, de, en, eo, es, fa, fr,it, ja, ko, nl, pl, pt, ru, sv, tr) present in both the MewsC-16 dataset (see Section 5.2) and the extended version of STS 2017】
作为我们的主要基线模型,我们使用使用与EASE相同的多语言数据(即实体-句子配对数据中的句子)训练的SimCSE模型
【脚注:我们使用在英语维基百科上训练的实体嵌入,与单语环境下的实体嵌入相同(第3节)。维基百科上训练出来的实体嵌入与单语设置中的实体嵌入相同(第3.3节)。请注意,所有语言的实体都被转换为维基数据的实体,这些实体可通过第3.1节所述的语言间链接在不同语言间共享。「They are converted into Wikidata entities, which are shared across lan- guages, using inter-language links obtained from the March 2020 version of the Wikidata dump」】
we start fine-tuning from pre-trained checkpoints of mBERT or XLM-R and take mean pooling to obtain sentence em- beddings for both training and evaluation on both EASE and SimCSE,We also tested other pooling methods, but mean pooling was the best in this experiment for both models
这里的话,mean pooling又是best的了
mBERT - multilingual bert https://aclanthology.org/2020.acl-main.747/
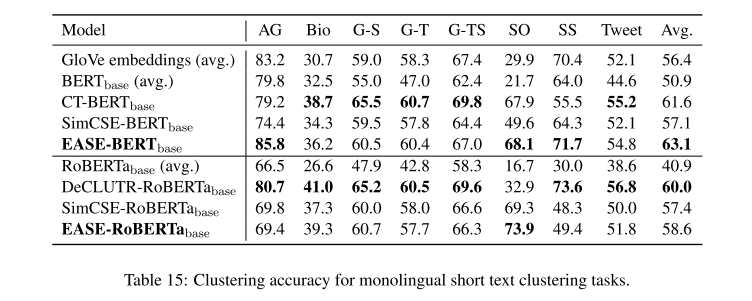
5.2 Multilingual STS and STC
STS 2017 dataset:which contains annotated sentences for ten language pairs: EN-EN, AR-AR, ES-ES, EN-AR, EN-DE, EN-TR, EN-ES, EN-FR, EN-IT, and EN- NL
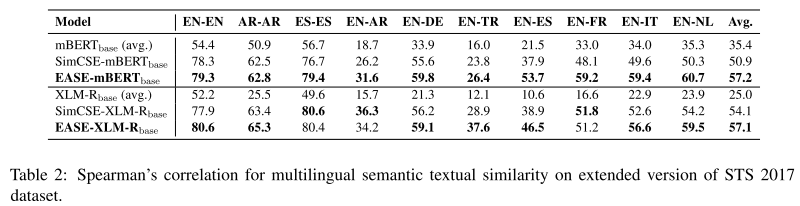
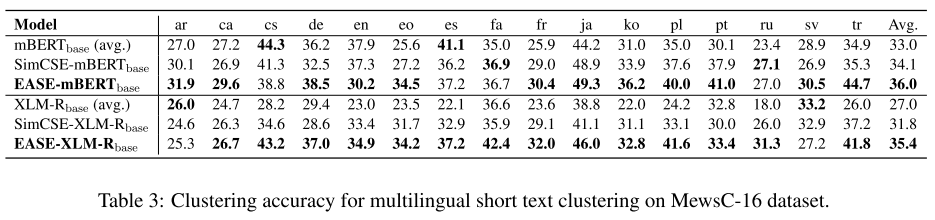
STC上,作者新建了一个数据集MewsC-16:Multilingual Short Text Clustering Dataset for News in 16 languages
5.3 Cross-lingual Parallel Matching
on the Tatoeba dataset以更直接地评估其捕捉跨语言语义的能力,这项任务是在给定一组平行句子的情况下,为每个查询句子检索出正确的目标句。
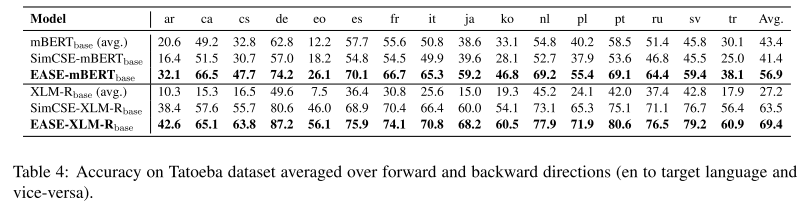
英语作为目标句子/初始句子
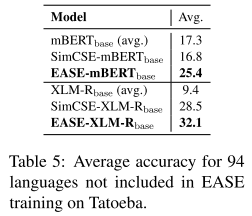
在Tatoeba全94个数据集上的验结果
5.4 Cross-lingual Zero-shot Transfer
MLDoc,a cross-lingual document classification dataset that classifies news articles in eight languages into four categories
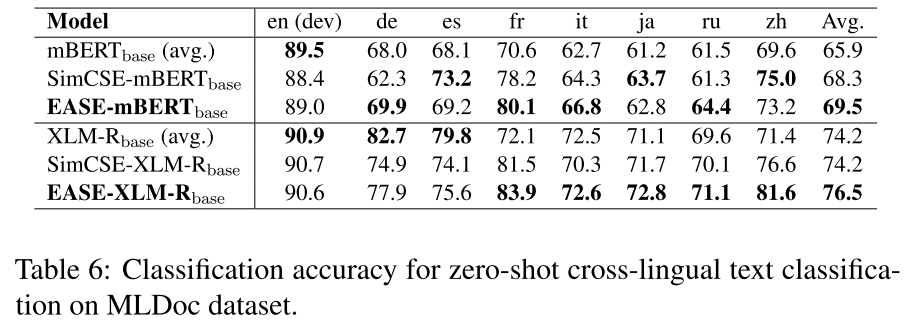
6. Case Study: Fine-tuning Supervised Model with EASE
In contrast, EASE requires only the Wikipedia text corpus, which is available in more than 300 languages
Wiki上感觉是提供了多语言的对齐数据
7. Analysis
7.1 Ablation Study
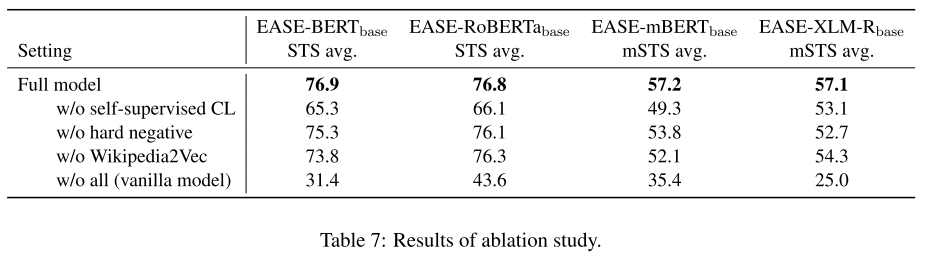
只使用entity-CL(w/o self-supervised CL)仍然显著提升了baseline的性能。
7.2 Alignment and Uniformity
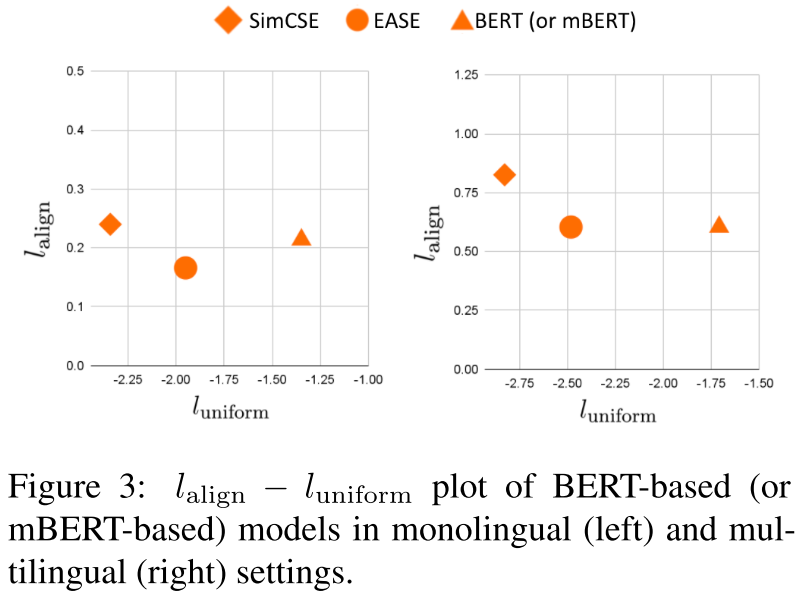
7.3 Qualitative Analysis※
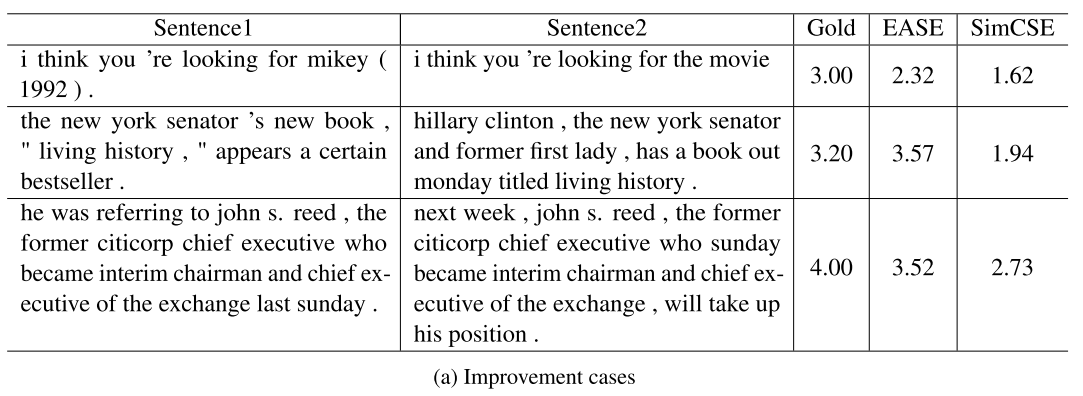
自己理解了一下效果增加的这几个case:
- mikey和movie在训练的时候是一个instance of 的关系,正例了
- 两边实体很像
- 两边实体很像

理解了一下效果降低的这几个case:
- idea 和 question,可能就就很像,但是忽略了句子其他非实体单词的意思
- 数量词
- 完全说的是不同的事情?
作者对这两个表格的解释是:
表8a显示了EASE如何改善句子嵌入的典型案例。我们发现,EASE的嵌入对同义词和语法差异更加稳健,因为它们更了解句子之间的主题相似性,从而导致更准确的分数推断。
如表8b中的恶化案例所示,EASE嵌入有时对主题相似性过于敏感,使其难以捕捉整个句子的正确含义
8. Discussion and Conclusion
我们的实验表明,EASE中的实体监督提高了单语环境下的句子嵌入质量,特别是在多语环境下的句子嵌入质量。正如最近的研究表明,实体注释可以作为anchor来学习高质量的跨语言表征,我们的工作是对其效用的另一种证明,特别是在句子嵌入中。一个有希望的未来方向是探索如何更好地利用实体的跨语言性质。
我们的实验也证明了维基百科作为一个多语言数据库的效用。如第6节所述,维基百科的实体注释可以弥补学习跨语言表征的平行资源的不足。维基百科目前支持300多种语言,其中约有一半的语言有超过10,000篇文章。此外,维基百科还在不断增长;预计它将包括越来越多的语言。
然而,对维基百科训练数据的依赖可能会限制模型在特定领域的应用(例如,一般或百科全书领域)。为了将EASE应用于其他领域,人们可能需要对该领域的文本进行手动或自动注释。未来的工作可以研究实体CL在其他领域的有效性,并可能将其与实体链接系统相结合。
最后,我们注意到EASE中的监督信号本身是有噪声的。不同的实体作为话题指标有不同的特点,而包含相同实体的句子不一定有共同的意义。未来的工作可以通过考虑一个实体在句子中的使用方式来解决这个问题,以获得更可靠的监督。
这个weakness感觉还是挺好发现的吧,在这里能不能搞出一种实体自选择的手段,比如词性?