acl-findings2022_Virtual Augumentation CL论文阅读
acl-findings2022_Virtual Augumentation CL论文阅读
Virtual Augmentation Supported Contrastive Learning of Sentence Representations
虚拟增强支持的句子表征的对比性学习
个人总结文章的亮点如下:
1)hard-negative角度,有一种反向的思路的感觉,邻域内的样本制造hard-negative:离自己相对较远而离邻居相对更近的一个微小扰动,但感觉不是negative这样的,只能说创造了一个hard的positive-pair?
reference
- 亚马逊提出无监督虚拟增强句子表征学习框架,效果超越SimCSE:http://www.360doc.com/content/21/1217/20/7673502_1009176247.shtml
TODO-list
- 感觉还是之前讨论的那个问题,在这里相当于pretrain了后,那么我在下游任务的时候是怎么个微调的过程?或者说下游这些任务不需要微调?
0. Abstract
尽管取得了巨大的成功,但对比性表征学习仍依赖于使用特定领域知识精心设计的数据增强。这一挑战在自然语言处理领域中被放大了,由于自然语言的离散性,在数据增强方面不存在一般规则。
像图像的话因为本质上都是一样的,那么可以直接旋转、裁剪、加噪声等,但是由于自然语言不同语言特性不同,而且增强的方法可能会对语义有着本质上的改变,感觉在增强方面几乎就没有什么很通用的
我们提出通过虚拟增强支持的句子表征对比学习(VaSCL,Virtual augmentation Supported Contrastive Learning)来应对这一挑战。我们从数据增强本质上构建每个训练实例的邻域的解释出发,反过来利用邻域来产生有效的数据增增强。
论文是从hard-negative这个角度来说的,我的一个原句的hard-negative的构建,可以通过在原句子基础上添加噪声,然后让这个噪声更加接近其K近邻样本而非原句,选一个噪声和原句有一种最远感觉的(在K个sample时候loss最大),这样带噪声的就是一个额外特殊的hard-negative了。
注意hard-negative不一定指的是对立的那种contradiction样本,而是说难学习的,比如扰动后的话毕竟还是基于原句子一个很微小扰动得到的,那么他理应当和原句形成一个positive pair
利用对比学习的大批量训练,我们通过一个实例在表示空间中的K-nearest in-batch邻居来近似其邻域。然后,我们定义一个关于这个邻域的实例判别任务,并以对抗性训练的方式生成虚拟增强。
我们查看了VaSCL在广泛的下游任务上的表现,并为无监督的句子表示学习设定了一个最先进的方法。
1. Introduction
通用句子表征学习一直是自然语言处理中的一个长期问题。利用分布式单词表征作为基础特征来产生句子表征是早期阶段的一个常见策略。然而这些方法都是针对不同的目标任务而设计的,因此产生的句子表征通用性较差。
这个问题促使人们在设计通用的句子级学习目标或任务方面做出更多的研究努力。其中自然语言推理(NLI)数据集上的监督学习已经在各种下游任务上建立了基准的迁移学习性能。尽管取得了可喜的进展,但收集注释的高成本阻碍了其广泛的适用性,特别是在目标领域注释很少,但与NLI数据集有很大差别的情况。NLI数据集一般是给定一个假设,然后对这个假设有人工标注的蕴含、中立、矛盾类型的句子对。一些CL工作将矛盾类型特别当做hard-negative
另外一方面,随着最近自监督对比学习的成功,句子表征的无监督学习又重新引起了人们的兴趣。这些方法依赖于两个主要部分:数据增强和实例级的对比性损失。流行的对比性学习目标(SimCLR那边的infoNCE)及其变体,已经在经验性上证明了它们在NLP中的有效性。然而,文本的离散性使得为有效的文本增强生成简历普遍的规则成为挑战。
人们提出了各种基于对比学习的方法来学习句子的表征,其主要区别在于如何生成增强的内容。有点令人惊讶的是,最近的一项工作(SimCSE)从经验上表明dropout(例:通过向编码器提供同一实例两次而获得的数据增强),超越了在文本上操作的普通数据增强策略, 包括删除单词或同义词替换等。在另一面,这一观察再次验证了在NLP中实现有效的数据增强的内在困难。
这段Introduction感觉写的不错
在本文中,我们通过提出一个邻域引导的虚拟增强策略来应对这一挑战,以支持对比性学习。简而言之,数据增强本质上是构建每个实例的邻域,而语义内容被保留下来。我们通过利用实例的邻域来指导扩增的生成,将这种解释引向相反的方向。受益于对比学习的大批量训练,我们通过一个实例的K-nearest in-batch neighbor对其进行近似。然后我们在这个邻域内定义一个实例判别任务,并以对抗性训练的方式生成虚拟增强。
这里大概看到method能明白是什么意思,在abstract里面略微有写
我们在广泛的下游任务上评估了我们的模型,并表明我们的模型始终以很大的优势超过了以前的最先进结果。我们进行了深入的分析,并表明我们的VaSCL模型导致了一个更分散的表征空间,不同粒度的数据语义得到了更好的捕捉。
各向异性、各项同性相关的分析?alignment and uniformlity
2. Related Work
2.1节Universal Sentence Representation Learning;2.2节Contrastive Learning;2.3节Consistency Regularization;
2.1 Universal Sentence Representation Learning
可以说(Arguably),获得句子表征的最简单和最常见的方法是word-bag及其变体。然而,word-bag存在着数据稀少和对词的语义缺乏敏感的问题词袋的方法应该是一些统计特征上的利用? 。在过去的20年里,分布式单词表征已经成为产生句子表征的更有效的基础特征。缺点是这些方法是针对目标任务的,因此产生的句子表征的迁移学习性能有限。
最近的努力集中在直接设计句子级别的学习目标或任务。在监督学习制度上,一些研究者证明了利用NLI任务促进通用句子表征的有效性。该任务涉及将每个句子对归入三个类别之一:蕴含(entailment)、中立(neutral)、矛盾(contradiction)。
Reimers和Gurevych(2019b)通过使用预训练的Transformer(BERT、RoBERTa)作为骨干,进一步增强了性能。另一方面,Hill等人(2016年);Bowman等人(2015b)提议使用去噪或变分自动编码器(VAE,variational auto encoder)进行句子表示学习。Kiros等人(2015);Hill等人(2016)将分布假设扩展到句子层面,并训练编码器-解码器为每个句子构建周围语境。或者,Logeswaran和Lee(2018)提出了一个模型,学习区分目标语境句子和所有对比句子。
2.2 Contrastive Learning
对比学习是近期句子表征学习成功的顶峰。Gao等人(2021);Zhang等人(2021)通过利用NLI中的entailment句子作为positive pair来优化适当设计的对比性损失函数,大大推进了之前的最先进成果。然而,我们专注于无监督的对比学习,并通过数据增强形成positive pari,因为这种方法更具成本效益,并适用于不同领域和语言。沿着这条路线,最近提出了几种方法,其中增强是通过dropout、回译、周围环境采样或在不同语义层面进行的扰动获得。
dropout这个方法是很有特点的,解决了数据增强不很稳定的特点
2.3 Consistency Regularization
我们的工作也与一致性的正则化密切相关,一致性的正则化通常用于促进更好的性能,通过正则化使得模型的输出在合理的输入变化下保持不变,这些变化通常是数据增强引起的。随机的数据增强,如dropout、cropping、rotation和flipping产生有效的正则化。Berthelot等人(2019,2020);Verma等人(2019)通过应用Mixup(Zhang等人,2017)及其在随机数据增强之上的变体来增强性能。
然而,数据扩充长期以来一直是NLP的一个挑战,因为没有有效的文本转换的一般规则。当考虑到违反一致性正则化时,一个替代方案就会出现,反过来可以用来寻找模型最敏感的扰动。在本文中,我们利用一致性正则化来促进表征空间中某一实例的信息性虚拟增强,同时利用其近似的邻域来正则化共享与原始实例相似的语义内容的增强。
这里加粗那句话是说,如果数据增强不当就会使得模型被很敏感的扰动了,那么反过来就是说寻找使得模型最为敏感的扰动。
3. Method

这里先把method的主图贴出来:
base:加上噪声不能影响基础的语义
可能认为N-1一定不存在正例,要么K近邻就会出问题;;;shifting的效果太小了?
3.1 Preliminaries
这里基本是复述了一下SimCLR这种比较经典的对比学习框架是怎么实现的,以及SimCSE这种比较“新奇”有代表性的方法
自我监督的对比性学习通常旨在解决实例辨别任务。

注意这里给出了“contrastive learning head”也就是zi的表述,指的是那种在hi后面再接一个线性层,用那个线性层输出作为对比学习输入的方式。
直观地说,方程(1)定义了在同一批B中的所有2M-1个候选者中,将第i个实例分类为其正面的对数可能性。
Dropout based contrastive learning:正如方程1所暗示的,对比性学习的成功依赖于有效的positive pair的构建,然而,由于自然语言的离散型,在NLP中很难产生强大而有效的数据转换。这一挑战在最近的一项工作中得到了进一步的证明(SimCSE),这一工作表明,通过dropout获得的数据增强胜过常见的文本扩充策略,如裁剪、删词或同义词替换。
Dropout通过随机掩盖其输入或隐藏层节点,为数据增量提供了一种自然的方式。使用Dropout作为伪数据增强的有效性可以追溯到Bachman等人(2014); Samuli和Timo(2017); Tarvainen和Valpola(2017)。尽管如此,仅用Dropout的增强强度是很弱的,有改进的余地,我们在下一节进行研究。
3.2 Neighborhood Constrained Contrastive Learning with Virtual Augmentation
邻居约束下的对比性学习与虚拟增强
从本质上讲,数据增强可以被解释为在保留语义内容的前提下,构建训练中的邻域。这个解释还是非常直观的,就是说构建出来的应该是邻域的,那么反过来说邻域的信息可被用来进行一些构建? 在本节中,我们从相反的方向进行解释,首先对一个实例的邻域进行近似,在此基础上生成数据增强。
更加具体的来说,首先使得$B={i}_{i=1}^{M}$代表随机采样选取的大小为M的一批数据。我们首先对于第i个实例,选择其最K近邻的邻居$N(i)$(我们首先将第1个实例的邻域N(i)近似为它在表示空间中的K个最近的邻居)
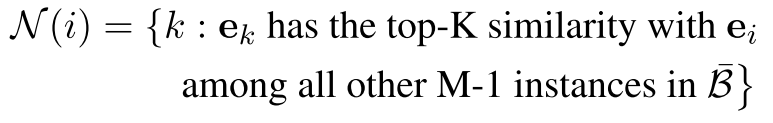
然后我们定义一个实例级的对比性损失 关于第1个实例和它的邻域,定义如下。
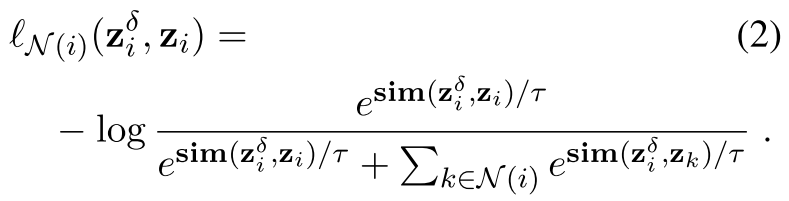
在上式中,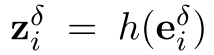 代表perturbed representation
代表perturbed representation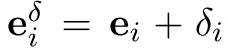 在contrastive learning head的输出表征。这里,初始扰动δi被选为各向同性的高斯噪声。正如它所暗示的那样,方程(2)显示了将受扰动的第i个实例归类为自身而不是其邻居的负对数可能性。
在contrastive learning head的输出表征。这里,初始扰动δi被选为各向同性的高斯噪声。正如它所暗示的那样,方程(2)显示了将受扰动的第i个实例归类为自身而不是其邻居的负对数可能性。
当扰动和自身接近的时候loss小,而当扰动和其他邻居更加接近的时候,loss大;另外这里是在ei层面上做的操作,引导ei学习表征更好,更好的表示一个句子?
然后,通过确定在这个邻域内最大程度地扰乱其实例级特征的最佳扰动,保留第i个实例的增强。这就是
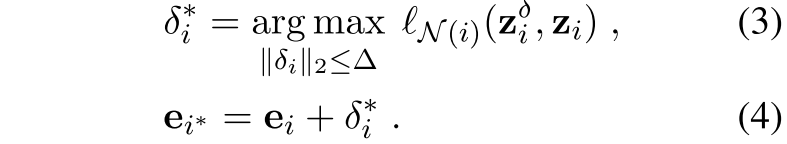
取最大的扰动(这个扰动的二范式,也就是自身长度大小那种感觉不能超过△,然后这个扰动使得他离K近邻的这些neighbor相对更近,而离自己较远,那么来说的话,这是一个很好的hard样例,扰动了一下但是和原句一个意思,然后又比较难)
将$N_A(i)$表示第i个实例的增强邻域,即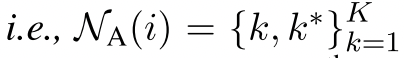 。$e_k$代表原始的第k个实例的嵌入表征,$e_k*$代表相关的增强后的表征。注意这里$e_k*$是以方程(4)中定义的同样方式获得的,关于它自己的邻域$N{(k)}$。然后,我们将第i个实例及其数据增强与它的数据增强邻域$N_A(i)$内的其他实例区分开来,如下所示:
。$e_k$代表原始的第k个实例的嵌入表征,$e_k*$代表相关的增强后的表征。注意这里$e_k*$是以方程(4)中定义的同样方式获得的,关于它自己的邻域$N{(k)}$。然后,我们将第i个实例及其数据增强与它的数据增强邻域$N_A(i)$内的其他实例区分开来,如下所示:
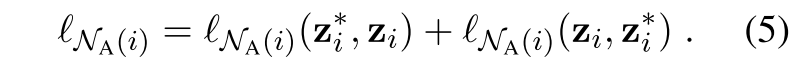
分别以第i个实例的增强,和第i个实例作为anchor:原句和其虚拟的困难样本形成positivepair相互拉近,原句和原句的虚拟样本分别于K邻域内的负样本 虚拟困难样本拉远
生成的hard-negative;;;一个batch中找到k,
- Putting in all together:因此,对于每个有M个样本的随机抽样的mini-batch B,我们最小化如下的损失函数:
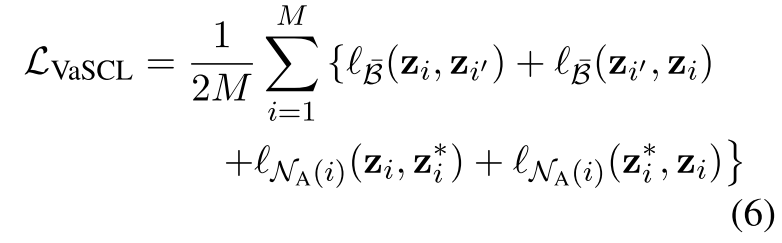
就是SimCSE的loss加上作者这个K邻居集中的loss
结合起来,对每个训练实例提出了两个实例判别任务:将每个实例及其dropout引起的变化与其他批次中的实例分开;将每个实例及其虚拟增强与它的前K个最近的邻居及其虚拟增强分开。
1 | |
4. Experiment
这里着重记录一下看到里面一些比较有亮点的ablation实验等,别的简单带过一下
在这一节中,我们主要针对SimCSE(Gao等人,2021)对VaSCL进行评估,SimCSE利用dropout(Srivastava等人,2014)引起的噪声作为数据增强。我们表明,VaSCL在涉及不同粒度的语义理解的各种下游任务中,一致地优于SimCSE。我们仔细研究了VaSCL的规则化效应,并从经验上证明VaSCL导致了一个更分散的代表空间,语义结构被更好地编码。这里就是更加各向同性?
4.1 Evaluation Datasets & 4.2 Main Results
- Table1:Semantic Textual Similarity
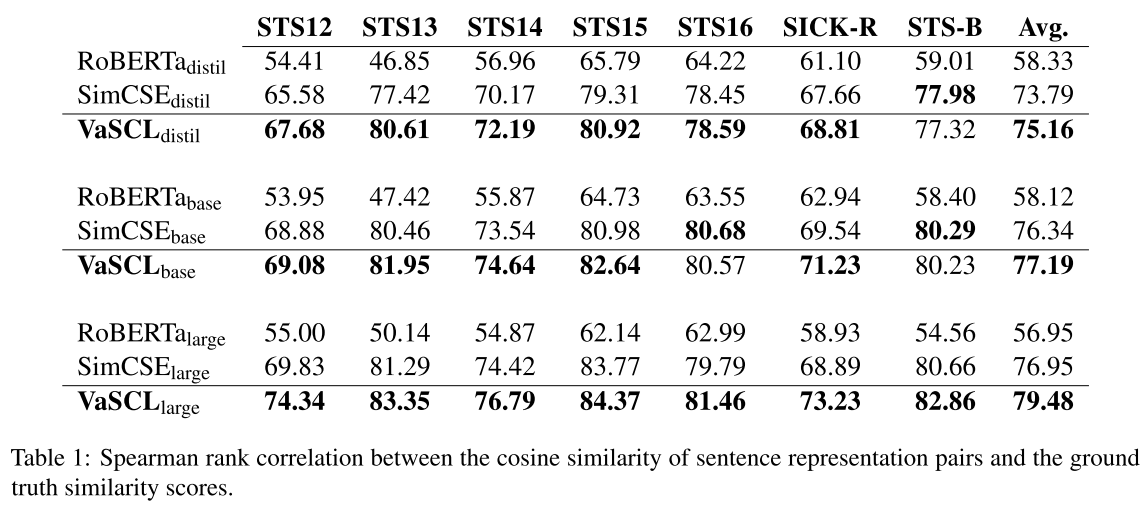 主实验结果相比SimCSE还是超越了相当程度的
主实验结果相比SimCSE还是超越了相当程度的
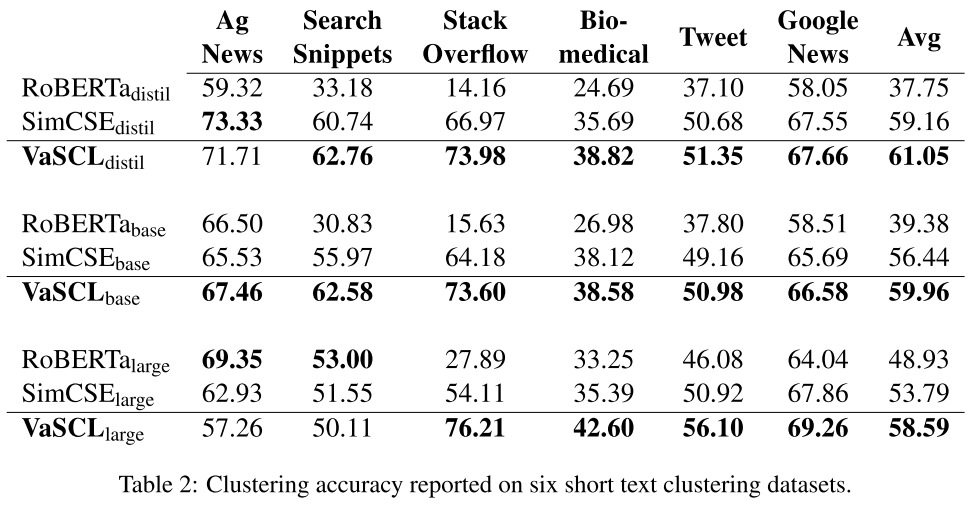
- Table2:Short Text Clustering(The clustering accuracy is computed by using the Hungarian algorithm (Munkres, 1957)
- Table3:Intent Classification
我们冻结Transformer,用基于softmax的交叉熵损失对线性分类层进行微调。我们合并训练集和验证集,从中为每个类别抽取K个训练和验证样本
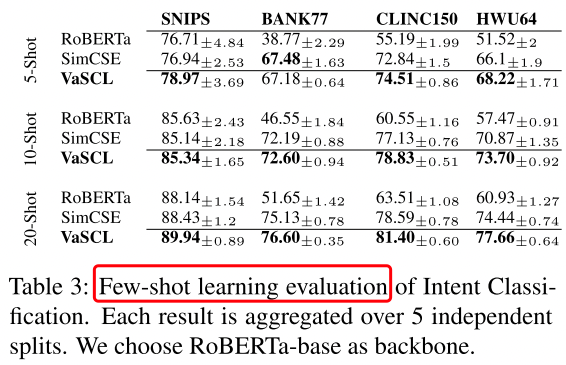
这里感觉还是之前讨论的那个问题,在这里相当于pretrain了后,那么我在下游任务的时候是怎么个微调的过程?或者说下游这些任务不需要微调?
4.3 Analysis
- Neighborhood Evaluation on Categorical Data
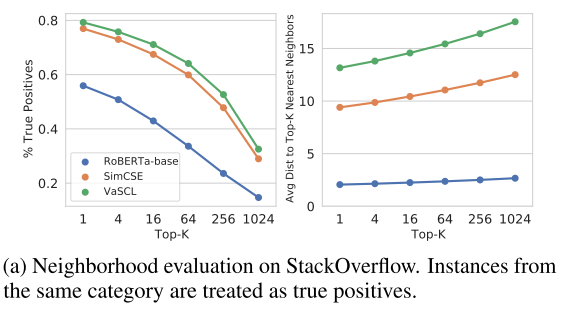
左边图表明,相似的样本还是足够的近,K很大了相似占比还是相对的多
右边图表明,这个特征空间在VaSCL和SimCSE的作用下拉的比较开,也就是说和K近邻的平均距离非常远!
- Fine-grained Semantic Understanding 细粒度的语义理解

这个图有点没看懂,之后还要详细看一下
contradiction 和 entailment就分的更开了,
4.4 Explict Data Augmentation
显式增强差很多?在STS和STC任务上,加上后性能都下降了,也就是说不能和传统的方法混用?但是在10-shot 的intent cls上上升了;
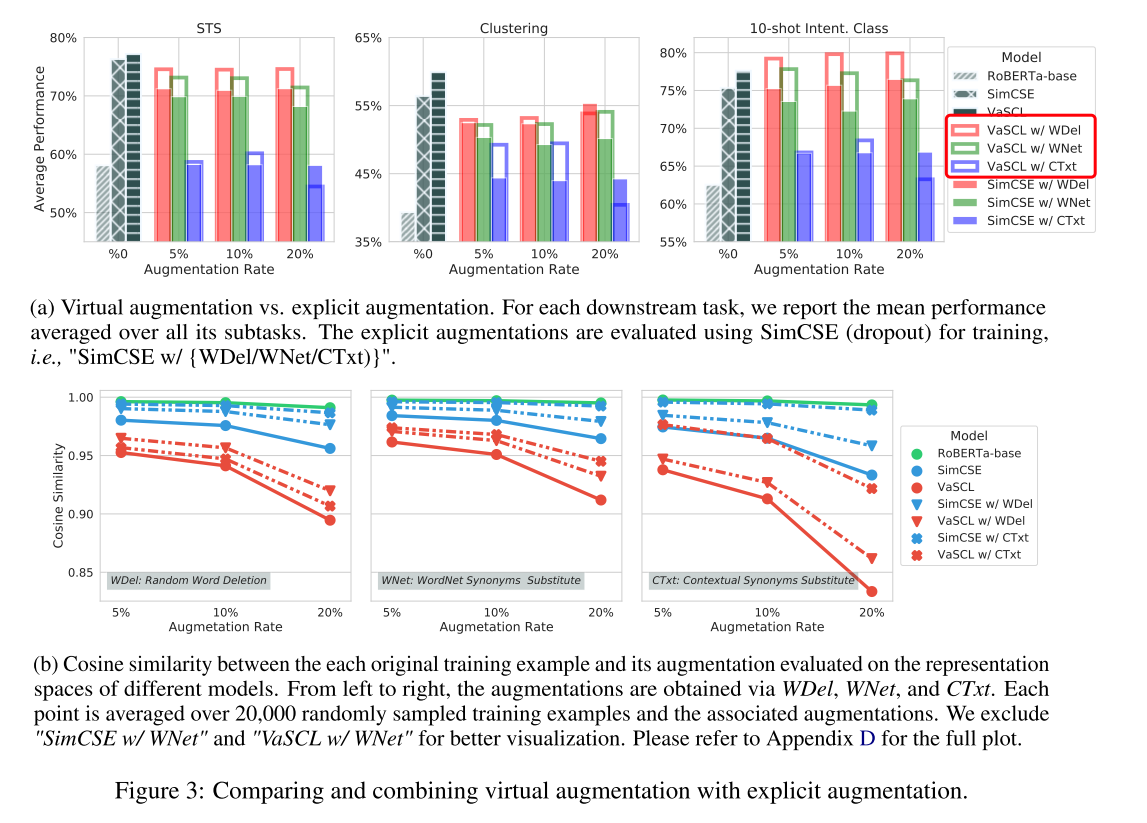
VaSCL Outperforms SimCSE:图3a也从经验上表明,无论是否存在明确的文本增强,VaSCL都优于SimCSE。唯一的例外是当明确的增强强度过大时,即每个文本中20%的词被扰动。一个可能的解释是,对离散文本的大扰动会直接产生不希望有的噪音,这可能会违反邻域所保持的连贯性,从而使VaSCL难以产生有效的虚拟增强。
New Linguistic Patterns Are Required For A Win-Win Performance Gain:要想获得双赢的业绩,需要新的语言学模式
从图3a中得出的另一个观察结果是,SimCSE和VaSCL在与明确的文本增强相结合时,在大多数下游任务上的表现都比较差。尽管VaSCL在大多数情况下确实提高了显式扩增的性能,但这是不可取的,因为我们期望一个双赢的结果,即适度的显式扩增也能提高VaSCL的性能。我们假设,为了达到预期的性能增益,缺少新的但又有信息的语言模式。
为了验证我们的假设,在图3b中,我们报告了每个原始训练例子与其在不同模型的表示空间上评估的增强的余弦相似度。我们的观察是双重的。首先,由RoBERTa诱导的表征和用同义词替换训练的表征(”SimCSE w/ CTxt”)在所有三种情况下都非常相似,这也解释了为什么 “SimCSE w/ WDel “在下游任务中获得了与RoBERTa类似的性能。我们将此归因于这样一个事实,即CTxt利用转化器本身来生成增量,从而携带有限的未见过的有效语言模式。其次,正如图3b中相对较小的相似度值所表明的那样,为了验证我们的假设,在图3b中,我们报告了每个原始训练例子与其在不同模型的表示空间上评估的增强的余弦相似度。我们的观察是双重的。首先,由RoBERTa诱导的表征和用同义词替换训练的表征(”SimCSE w/ CTxt”)在所有三种情况下都非常相似,这也解释了为什么 “SimCSE w/ WDel “在下游任务中获得了与RoBERTa类似的性能。我们将此归因于这样一个事实,即CTxt利用转化器本身来生成增量,从而携带有限的未见过的有效语言模式。其次,正如图3b中相对较小的相似度值所表明的那样,显式增量的加入【收紧了SimCSE和VaSCL的表达空间】,这也反过来导致下游任务的性能下降。一个可能的解释是,所有三个显式增强都是弱的和嘈杂的,这损害了实例的识别力和每个邻域的语义相关性。