emnlp2021_SimCSE论文阅读
emnlp2021_SimCSE论文阅读
**SimCSE: Simple Contrastive Learning of Sentence Embeddings **普林斯顿&清华大学
SimCSE,个人总结文章的亮点如下:
1)一种无监督的方法,只简单使用BERT中的dropout,一句话过同一个bert两次,生成的两种representation之间构成positive pair;
2)一种有监督的方法,使用NLI数据集内部包含的一个前提,以及前提对应的蕴含文本、中立文本、矛盾文本,其中和蕴含文本构成positive pair,和矛盾文本构成negative pair,还可以通过权重额外增强negative pair;
3)提出了从理论分析的角度,alignment和uniformity证明这种简单dropout有效的;
4)进行了多项ablation实验,寻求细节处的最有设置
reference
文本语义相似度:https://www.zhihu.com/question/22004262/answer/2565474940
github 代码:https://github.com/princeton-nlp/SimCSE
TODO-list
- 公式(1)中positive pair是否包含在分母中?个人感觉应该是包含的吧,没有写j!=i;包含
- 对 Aligenment and uniformity的理解还不是很到位,可能需要去看下ICML2020那篇Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere,不过有些过于数学了;
- 还是有些不理解使用一个而不是两个Encoder的motivation是什么,如果使用两个那么后面是要丢弃掉一个吗?除了从实验效果上来说,两个编码器的为什么相较于共用一个表现不好?;
- 因为是修改[CLS]token这种感觉,CL大多数的任务都是专注于句子级别的?比如句子分类还有句子情感分析相似度计算等,但是对于NER那类的任务会不会就不适用了?
- [CLS]token这块的含义:
0. Abstract
本文介绍了SimCSE(simple contrastive learning framework for sentence embedding ),一个简单的对比性学习框架,大大推进了最先进的句子嵌入技术。
我们首先描述了一种无监督的方法,它接受一个输入句子并在对比性目标中预测其本身,仅使用标准的dropout作为噪声。这种简单的方法出奇的好,与以前的有监督方法相当。我们发现,dropout作为最小的数据扩充,删除它会导致representation崩溃。
然后我们提出了一种有监督学习方法,将来自自然语言推理数据集的注释对合并到我们的对比表示学习框架中,使用“entailment(蕴含,这里翻译成相近比较好)”对代表positive并使用“contradiction(矛盾)”对代表negative。
我们在标准语义文本相似性(STS)任务上评估了SimCSE,我们使用BERT-base的无监督和有监督模型分别实现了76.3和81.6%的Spearman相关性,与之前的最佳结果相比,分别提高了4.2%和2.2%。我们还从理论和经验上证明,对比学习目标将预训练嵌入的各向异性空间正则化为更单一的形式,并且当有监督信号可用时,它可以更好地对齐正对。
在这里翻了下后面的ablation,似乎没有对比发表在ACL2021上的那篇韩国团队用BERT-CLS搞的,看起来实验结果比那篇好一些,然后也比较广泛流传,而且对比来说那一篇从可信性和换数据集的脆弱性上也不一定
这个作者说的“将预训练embedding的各向异性空间正则化为更单一的形式,并且当有监督信号可用时,它可以更好地对齐正对”不理解,这里可能有一些数学原理在里面
1. Introduction
学习通用的句子嵌入是自然语言过程中的一个基本问题,在一些文献中已经得到了广泛的研究。在这项工作中,我们提出了最先进的句子嵌入方法,并证明了对比目标与预训练的语言模型如BERT和RoBERTa相结合可以非常有效。我们提出了一个简单的对比句子嵌入框架SimCSE,它可以从未标记或标记的数据中生成更好的句子嵌入。
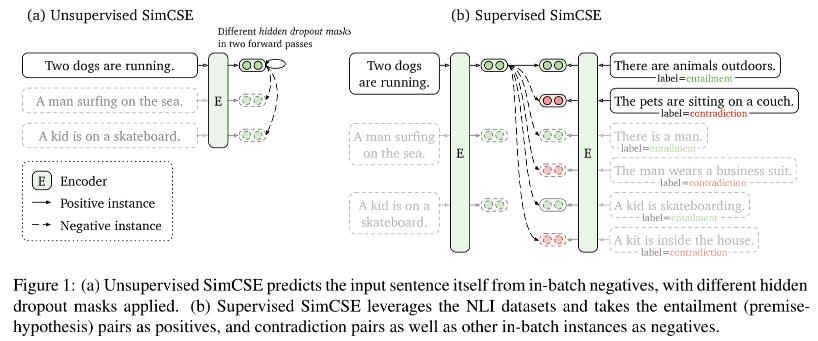
- 我们的无监督SimCSE简单的预测输入句子本身,只将dropout作为噪声(Figure1-a),换句话说我们将同一个句子传递给预训练的编码器两次,通过应用两次的dropout,我们可以获得两个不同的embedding作为positive pair。这个还是真的很巧妙,中间多层dropout确实提供了同一个句子不同embedding表示相对的不同差异? 然后我们在同一个mini-batch中选择其他句子作为negative sample, and the model predicts the positive one among negatives.这句英文有点没看懂 ;;虽然他可能看起来非常简单,但这种方法大大优于训练目标,例如预测下一个句子和离散数据增强(例如单词删除和替换),甚至与以前的有监督方法相媲美。*通过仔细分析,我们发现dropout作为隐藏表示的最小数据增强,而删除他会导致表示崩溃。
- 我们的有监督SimCSE在最近成功使用自然语言推理(Natural Language Inference, NLI)的基础上,并将带注释句子对纳入对比学习中(Figure1-b,图中entailment意思是蕴含,Two dogs are running和There are animals outdoors两句话是一种蕴含关系? ,contradiction的意思是矛盾,Two dogs are running和The pets are sitting on a couch是矛盾的关系 )。与之前将其转化为三向分类任务(蕴含、中立和矛盾)的工作不同,我们利用了蕴含对可以自然地用作positive pairs的事实。我们还发现,添加对应的矛盾对作为hard negative进一步提高了性能。与以前使用相同数据集的方法相比,这种简单使用NLI数据集的方法实现了实质性的改进。我们还与其他标记句子对数据集进行了比较,发现NLI数据集对于学习句子嵌入特别有效。
为了更好地理解SimCSE强大的性能,我们借用他人的分析工具,该工具采用语义相关正对之间的对齐和整个representation空间的一致性来衡量学习embedding的质量。通过实证分析,我们发现我们的无监督SimCSE从本质上提高了一致性,同时通过dropout噪声避免了退化对齐,从而提高了表示的表达能力。同样的分析还表明,NLI训练信号可以进一步改善positive pair之间的对齐并产生更好的句子嵌入,我们还与最近的研究结果联系起来,即预训练的词嵌入存在各向异性,并通过光谱的角度证明了对比学习目标“压平”了奇异值分布 句子嵌入空间,从而提高一致性。
我们对七个标准语义文本相似性 (STS) 任务和七个transfer task进行测试。在STS任务上,我们的无监督和有监督模型使用BERT-base分别实现了76.3和81.6的平均spearman相关性,与之前的最佳结果相比提高了4.2%和2.2%。我们还在transfer任务上取得了有竞争力的表现。最后,我们在文献中确定了一个不连贯的评估问题,并整合了不同设置的结果,以用于评估未来的句子嵌入评估工作。
2. Background: Contrastive Learning
这里主要介绍的是CL方面的相关工作,和其他一些paper有可能还介绍一些fine-tuneBERT、sentence embedding什么的还不太一样
对比学习旨在通过将语义上相近的邻域聚在一起并将非邻域分开来学习有效的表征。它设置了一组成对的示例 $D = {(x_i, x_{i}^{+})}{i=1}^{m}$,其中$x_i$与$x{i}^{+}$具有语义相关的性质。我们遵循Chen等人提出的contrastive framework (SimCLR),并使用cross-entropy损失函数作为训练目标with in-batch negatives 后面这个with in-batch negatives有点没理解,下面这个公式来说像是softmax的感觉又好像不包含positive pair在式子中。 $h_i$和$h_{i}^{+}$代表$x_i$与$x_{i}^{+}$的representation,一个训练的mini-batch中有N对$(x_i, x_{i}^{+})$组合,公式如下:
自己理解这个公式来说,positive pair应该还是包含在分母中的吧,要不怎么来像是softmax衡量那个感觉?另外没有写j!=i,另注这个公式是针对每单个样本的!对于所有样本一般先求和后再平均

$\tau$代表一个温度超参数(个人理解有点像MHSA那块除一个根号dk,这样来放缩softmax的指数大小) ,${\rm sim(h_1,h_2)}$用来衡量相似性,作者这里使用的是cosine similarity $\frac{h_{1}^{Τ}h_{2}}{\left| h_{1} \right| \cdot \left| h_{2} \right|}$向量点乘除以模长乘在一起,这个应该就是$cos \theta$吧,这个数值是1代表两个向量十分接近,即完全能投影在另外一个向量上,夹角为0度;而如果是0则代表两个向量正交90° 。在这项工作中,我们使用预训练的语言模型(如BERT或RoBERTa)对输入句子进行编码:h=fθ(x),然后使用对比学习目标(式1)。
2.1 positive instances 正实例
对比学习中的一个关键问题是如何构建$(x_i, x_{i}^{+})$对(positive pair)。在视觉表示中,一个有效的解决方案是对同一图像进行两次随机变换(例如,裁剪、翻转、失真和旋转)来获取$x_i$与$x_{i}^{+}$。最近在语言表示中采用了类似的数据增强技术(如单词删除、重新排序和替换)。然而由于其离散性,非线性规划中的数据扩充本质上是困难的。在第3节中我们将看到,在中间层的表征中使用标准的dropout优于这些离散的算子。离散算子discrete operators大概指的就是这些传统数据增强操作。
在自然语言处理中,人们在不同的语境中探索了相似的对比学习目标。在这些情况下,$x_i$与$x_{i}^{+}$是从有监督数据集例如question-passage pair中获取的。由于$x_i$与$x_{i}^{+}$的不同性质,这些方法总是使用双编码器框架,例如为$(x_i, x_{i}^{+})$使用两个独立的encoder$f_{\theta_1}$和$f_{\theta_2}$。对于句子embedding,Logeswaran和Lee(2018)也使用了双编码器方法的对比学习,将当前句子和下一个句子形成为$(x_i, x_{i}^{+})$。
2.2 Aligenment and uniformity 同向性和均匀性
最近,Wang和Isola([ICML2020](Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere))确定了对比学习两个重要的属性,alignment(对齐、结盟) and uniformity(均匀性、单调),并建议使用它们来衡量表征的质量。给定positive pair的distribution$p_{pos}$,alignment计算成对实例embedding之间的预期距离(假设representation已经过规范化):
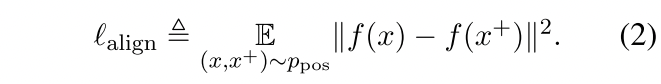
从另一方面来说,uniformity衡量嵌入表征的均匀分布如何:
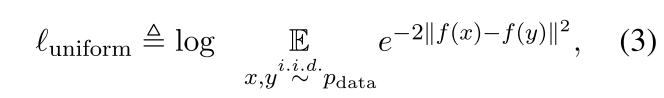
其中$p_{data}$代表data distribution。这两个指标与对比学习的目标很好的一致:positive实例应该保持紧密,随机实例的embedding应分散在hypersphere。在以下部分中,我们还将使用这两个指标证明我们方法的内部工作。
关于这块数学的推导还没有研究太深,还需要之后深入研究一下
3. Unsupervised SimCSE
无监督SimCSE的思想非常简单:我们收集了一些句子${x_{i}}{i=1}^{m}$并且使用$x{i}^{+}=x_{i}$。对于本项工作的关键因素是通过完全相同的获取方法获取positive pair,通过对于$x_i$和$x_{i}^{+}$独立的使用采样dropout mask。在Transformer的标准训练过程中,在fully-connected layers和attention probabilities层中使用了dropout mask(默认的p=0.1)。
我们表示$h_{i}^{z}=f_{\theta}(x_i,z)$,其中$z$是一个dropout的random mask。我们只需要将相同的输入送入编码器两次,就能得到两个具有不同dropout mask $z,z’$的embedding嵌入表征。而SimCSE的训练目标变成了:
这个公式就是上面式1那个感觉,同样和上面的一样,这单个公式是对于单个样本的!然后因为分母那边没有写j!=i,所以positive pair也是包含在分母中的

对于一个包含N句话的mini-batch。注意$z$只是一个标准的包含在Transformer中的dropout mask,我们没有添加其他的dropout。
3.1 Dropout noise as data augmentation
这种论文写作的方法是不是不太常见?感觉还在method章节就把实验拿进来了,也可能是因为这个章节方法太简单了没什么说的,就要多写一些实验分析相关的?
我们把dropout看做一种最小形式的数据增强:positive pairs采用完全相同的句子,它们的嵌入只在dropout mask上有所不同。我们将这种方法与STS-B development set上的其他训练目标进行比较[角标注释2:我们从Englist Wikipedia中随机采样了10^6的句子,并且使用lr=3e-5 N=64的参数来进行BERT-base的fine-tune,没有STS 的training sets被使用]。表1将我们的方法与常见的数据增强技术进行了比较,如裁剪、单词删除和替换,这些技术可以被视为$h=f_\theta(g(x),z)$,其中$g$是一个作用于$x$的随机离散运算符(理解为数据增强法) 。我们注意到,即使是删除一个词one word也会损害性能,而且没有一个离散的数据增强方法能超过dropout噪声。是不是如果使用其他方法的话,如果不是作者这种简单的dropout方法,那么其他方法的dropout是固定住的吗?
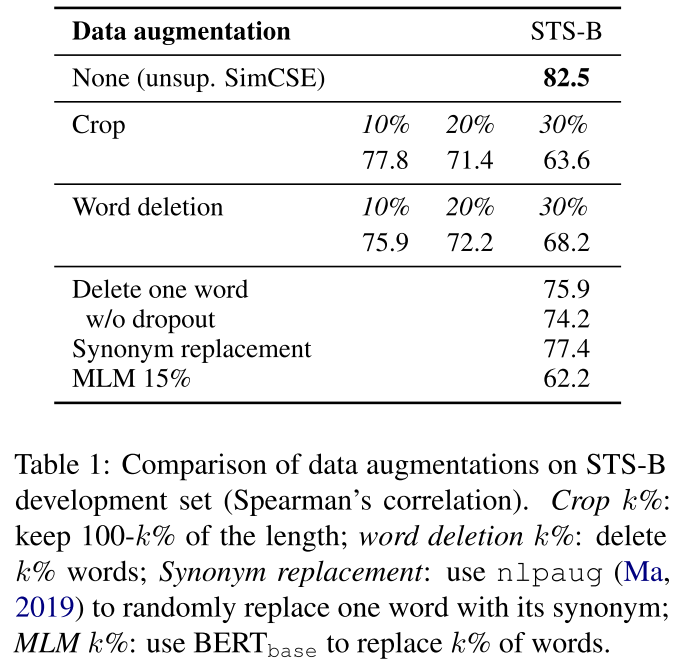
Table1:不同数据增强方法在STS-B develoment set上的比较(Spearman’s correlation)。Crop k%代表保留了100-k%的长度;word deletion k%代表删除掉k%的词;Synonym replacement同义词替换使用了nlpaug(Ma2019)来随机替换同义词;MLM k%代表使用BERT_base替换k%的words。
我们还将这个self-prediction的自我训练目标与Logeswaran和Lee使用的下一句话目标进行比较,采取一个编码器或两个独立的编码器。我们发现SimCSE的表现比next-sentence目标好得多(在STS-B上为82.5vs67.4),使用一个编码器而不是两个编码器使我们的方法有了很大的不同。对于使用两个编码器做dropout的话,那么最终是丢弃一个?

Table2:不同无监督学习目标的比较(STS-B development set,Spearman’s correlation)。两列标识了我们使用同一个encoder还是两个独立的encoder。Next 3 sentences:随机从下面3句话中采样一句话;delete one word:随机从句子中删除一个词。
3.2 Why does it work?
为了进一步了解dropout在无监督SimCSE中发挥的作用,我们在表3中尝试了不同的dropout rate,发现所有的变体都低于Transformer中默认设置的p=0.1。

我们发现两个极端case特别有趣:“no dropout”(p=0)和“fixed 0.1”(使用默认的dropout p=0.1但是在一对中使用同样的mask)。在这两个case中,所产生的pair的embedding完全相同,这导致了性能的急剧下降。在训练过程中,我们每个10个step对这些模型取checkpoint,并在Figure2中展示了alignment和uniformity指标,以及一个简单的数据增强模型“delete one word”。**[角标注释3:我们将STS-B指标score大于4的pair作为$p_{pos}$,并把所有STS-B中的sentences作为$p_{data}$]**

如图所示,从预训练的checkpoint开始,所有模型都大大改善了uniformity。然而,两个特殊变体的alignment也急剧下降,而我们的无监督SimCSE则保持了稳定的aligment,这主要归功于dropout噪声的使用。这也表明,从预先训练好的checkpoint开始是至关重要的,因为它提供了良好的初始aligment。最后,“delete one word”提供了良好的初始aligment,但在uniformilty指标上取得了较小的收益,并最终低于无监督SimCSE的表现。
4. Supervised SimCSE
我们已经证明,添加dropout噪声能够使得positive pair保持良好的aligment $(x, x^+)~p_{pos}$。在本节中,我们研究是否可以利用监督数据集来提供更好的训练信号,以优化我们方法的alignment一致性。前人的研究工作已经证明,有监督的自然语言推理(Natural Language Inference, NLI)数据集对于学习句子embedding是有效的,它可以预测两个句子之间的关系是相近的(entailment)、中性的(neutral)、还是矛盾(contradiction)关系。
在我们的对比性学习框架中,我们直接把从有监督数据集中拿到的$(x_{i}^{+},x_{i})$对,然后用他们优化公式1。

4.1 Choices of labeled data
我们首先探究哪些监督数据集特别适合构建positive pair$(x_{i}^{+},x_{i})$。我们在一些带有句对示例的数据集进行实验,包括
- QQP:Quora questions pairs;
- Flickr30k:每张图片都有5个人工撰写的标题,我们认为同一张图片的任何两个标题都是正面的一对;
- ParaNMT:一个大规模的back-translation的dataset;
- NLI:SNLI和MNLI;
我们在不同的数据集通过公式1训练对比学习模型,并在table4中比较结果。为了进行公平的比较,我们还用相同的#训练对进行训练。在所有的选项中,使用NLI(SNLI+MNLI)数据集的表现最好。我们认为这是合理的,因为NLI数据集包括高质量的、来自crowd-sourced pairs。另外,人类注释者要根据前提手动写出假设,而且两个句子的词汇重叠度往往较低。例如,我们发现entailment(相关)对的词汇重叠度(两个word bag之间的F1)为39%,而QQP和ParaNMT的词汇重叠率为60%和55%。


4.2 Contradiction as hard negatives 对于hard-negatives的矛盾
最后,我们进一步利用NLI数据集的优势,将其矛盾(contradiction)对作为硬性否定句。在NLI数据集中,给定一个前提,注视着需要首先出一个绝对真实的句子(entailment),一个可能是真实的句子(neutral),以及一个绝对错误的句子(contradiction)。因此,对于每个前提和它的entailment假设,都有一个伴随的contradiction假设。[脚注7:事实上,一个前提可以有多个矛盾的假设。在我们的实施中,我们只抽出一个作为硬性否定,我们没有发现使用更多的会带来区别]
再次把这个图给贴过来,一个前提对应的entailment和contradiction

形式上,我们将$(x_{i}^{+},x_{i})$扩展为$(x_{i}, x_{i}^{+}, x_{i}^{-})$,分别代表前提(premise)蕴含(entailment)和矛盾(contradiction)。训练目标被表示为如下的:
这个式5和其他地方还是不太一样的,我们希望hi和hi+尽量接近,分母那边意会上也是说,hi不仅需要与hj+相远离、也需要与hj-相远离,这里j可以等于i

如table4所示,添加hard negatives可以进一步提高性能(84.2->86.2),这就是我们最终有监督的SimCSE。我们还试图加入ANLI数据集或将其与我们的无监督SimCSE方法相结合,但没有发现有意义的改进。我们还考虑在有监督的SimCSE中采用双编码器框架,但它损害了性能(86.2->84.2)。
为什么两个encoder就会有问题,这个地方背后获取存在着什么解释吗?
5. Connection to Anisotropy 与各向异性的联系
这个章节相对数学内容比较多,暂时跳过,如果需要看的话可能还要再理解一下ICML2020那篇
6. Experiment
这里记录一些Experiment中比较关键的内容,也为之后看代码积累下
6.1 Evaluation Setup
我们对7项语义文本相似性(Semantic Textual Similarity)任务进行了实验。请注意,我们所有的STS实验都是无监督的,没有使用STS的训练集。即使是有监督的SimCSE,我们也只是意味着我们采取额外的标记数据集进行训练,遵循以前的工作。我们还评估了7个Transfer学习任务,并在附录E中提供了详细的结果。我们与Reimers和Gurevych(2019)有类似的看法,即句子嵌入的主要目标是将语义相似的句子聚在一起,因此将STS作为主要结果。

6.1.1 Semantic textual similarity tasks
We evaluate on 7 STS tasks: STS 2012–2016、STS Benchmark(STS-B)、SICK- Relatedness(SICK-R)
这里还说了一些和别人公平比较的设置:
(a) whether to use an additional regressor -> 选择no additional regressor
(b) Spearman’s vs Pearson’s correlation -> 选择Spearman corrleation
(c) how the results are aggregated -> “all” aggregation
6.1.2 Training details
我们从BERT(uncased)或者RoBERTa(cased)的checkpoint开始训练(作者之前在method中的实验也提到了:It also demonstrates that starting from a pre-trained checkpoint is crucial, for it provides good initial alignment) ,并将[CLS]表示法作为句子嵌入的方法(后续实验中有提到不同pooling method的对比)。我们在英语维基百科中随机抽样的10^6个句子上训练无监督的SimCSE 这里的10^6就是1M,前面有个表格写到了 。并在MNLI和SNLI数据集的组合上(314k)训练有监督的SimCSE。**[脚注9:在BERT原版的实现中[CLS]token后有MLP layer,我们保持并将保持随机初始化]**
Appendix A:

这里除了表格里写的实验设置之外,还说了下面这段话:我们再引入一个可选的变体,它增加了一个Mask Language Modeling目标作为辅助损失添加到式1中,$\ell + \lambda·\ell^{mlm}$。这有助于SImCSE避免对token级别的知识的灾难性遗忘。正如我们在表D.2这种显示的,我们发现增加这个词可以帮助提高transfer任务的性能(而不是句子级sts任务)。
因为是修改[CLS]token这种感觉,CL大多数的任务都是专注于句子级别的?比如句子分类还有句子情感分析相似度计算等,但是对于NER那类的任务会不会就不适用了?
6.2 Main Results
主要介绍和哪些前人的工作进行了对比和Main Results
6.3 Abalation Studies ※
我们研究了不同的pooling方法和hard negative的影响。本节中所有报告的结果都是基于STS-B development集合。我们在附录D中提供了更多的消融研究(normalization、temperature、MLM objectives)。
6.3.1 Pooling methods
一些研究者表明采取预训练模型的平均embedding(特别是来自第一层和最后一层的embedding)会导致比[CLS]更好的性能。(这里一方面自己想记录一下[CLS]token的理解,我觉得[CLS]token就是一个指定上的内容,我们希望这个token学习到整个句子的特征表示,在self-attention中聚合了来自其他token的表示。另外来说这里好像写的不是很清楚,取的是第一层和最后一层的[CLS]?) Table6显示了再无监督和有监督的SimCSE中不同集合方法的比较。对于[CLS]的表示,原始的BERT实现在其之上采取了一个额外的MLP层。
在此,我们考虑了[CLS]的三种不同设置
- 保持MLP层
- 没有MLP层
- 在训练时候保留MLP,在测试时删除它
我们发现,对于无监督的SimCSE,在训练过程中只用MLP的[CLS]表征效果最好(上述设置3)。对于有监督的SimCSE,不同的pooling方法并不重要。默认的情况下,对于无监督的SimCSE我们使用[CLS]+MLP(train),对于有监督的SimCSE使用[CLS]+MLP。

6.3.2 Hard negatives
直观的说,将hard negatives与其他in-batch的negatives区分开来可能是有益的(这里背后的motivation是x x+ x-三个组成一组的时候,那么xi和xi-是最应该原理的,而且应当比xi和xj+ xi和xj-都更远) 。因此,我们扩展了公式5中定义的训练目标,以纳入不同的负面因素的权重。

其中$1_{i}^{j}$是一个指示器,只有当i=j的时候会是1。其他情况是0,那么$\alpha$的0次方永远都是1,和alpha就没什么关系了,而只有对hard-negatives才会有关系
我们用不同的α值训练SimCSE,并在STS-B的开发集上评估训练好的模型。我们还考虑将中性假设作为硬性否定。如表7所示,α=1的表现最好,中性假设不会带来进一步的收益。

这里有个问题,这么微小的波动,实验是真的会训练多次然后取平均吗,如果seed不一样就很容易造成这样的误差吧
6.3.3 different temperatures(Appendix D)

6.3.4 MLM training objective

在Transfer任务上使用MLM会好一点点
这个paper,写的introduction,前导理论,还有一些实验什么的写的比较到位。学一下人家提出来一个想法的时候,一步步引出来这个问题,再加上ablation
方法比较简单但是细节比较多:dropout起到了作用,同一条数据进模型两次,但是用不同的dropoutmask的,用了dropout后一种子网络的感觉,用了两个完整网络的不同子网络,同一条文本数据的embedding
为什么dropout取两个子网络,就好? 另外一种方法比如取1357层、2468层,效果不如这个好?用dropout就相对于剪枝了一些的,随机mask,0.1 0.2 ;;;一条数据经过dropout一定是一样的?—— dropout为什么起作用hinton:dropout在训练的时候起作用,原来神经元10个,现在0.1随机mask掉一个9个,训练过程的时候任意9个神经元完成一个任务,强制的使得模型对特征的表达更好,但即使这样还是随机的,剪枝是一个有向的希望剪枝前后尽可能相近的;;;worddropout?;;;,
dropout-随机化的剪枝 有偏的,说不定把最重要的mask掉了,无向
正常的剪枝:梯度比较小了,不重要了,就剪枝掉;;希望剪枝前后尽可能相近的,剪枝后略有精度损失;;
是不是可以用剪枝的思路也实现一下,从剪枝的角度梳理了一下思路;;BERT-base-12层,12层的特征,比如取出来每一层的[CLS],每一层提到了不同的特征,底层句法特征,上层语义特征,12个CLS赋权重,textCNN网络,每个CLS给个权重,映射层后面加dropout,映射层参数小于encoder,大大降低参数量,不同层不同权重 dropout加在encoder层/dropout加在后面层
※用CLS作为默认的,但是其他有很多思路认为用CLS不一定是效果最好;;;[CLS] token的理解,用CLS做sentence embedding只是一个经验主义,但是可解释性不强;;;sift hog;;;token embedding加起来做平均/第一层和最后一层加起来更好/…
调整embedding space,使得sentence embedding更好,sentence representation
加一些思考,有没有什么可改进的;
9. Conclusion
在这项工作中,我们提出了SImCSE,一个简单的对比学习框架,它大大改善了最先进的句子嵌入的语义文本相似性任务。
我们提出了一种无监督的方法,该方法预测输入的句子本身有dropout噪声。还有一种有监督的方法,利用NLI数据集。
我们通过分析SimCSE与其他baseline模型的一致性和统一性,进一步证明了我们方法的内部工作原理。
我们相信,我们的对比目标,特别是无监督的目标,在NLP中可能有更广泛的应用。它为文本输入的数据扩充提供了一个新的视角,并且可以扩展到其他的连续representations,并整合到语言模型的预训练中。
部分代码
模型的主要代码在这个相对路径下, SimCSE-main/simcse/models.py
https://github.com/princeton-nlp/SimCSE/blob/main/simcse/models.py
156行经过pooler后,得到一个[batchsize, num_sentence, hidden]长度的tensor,[0] [1]之间是一个positive pair,[2]是在有监督学习场景下给进去的hard-negative(意思可能最为离谱相反的)
代码结构,看到主要模块在什么地方,什么地方怎么改:比如负例的权重,实现原始结果:可能google drive;;;数据规模缩小一点
有个中文版的对于unsupervised写了一版,看起来比较好理解些?
这里每句话重复了两次,构建一句话输入进去两次bert,然后在这里算损失函数
1 | |