emnlp2021_Raise a Child in Large Language Model论文阅读
emnlp2021_Raise a Child in Large Language Model论文阅读
Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning
中文翻译为:在大型语言模型中培养Child:实现有效且通用的fine-tune
个人总结贡献如下:
- 一种有些即插即用感觉的fine-tune操作,称为CHILD-TUNING技术,基本原理是在back propagation的时候随机mask掉一些,这个方法与之前的其他tuning方法是正交的,如果用在一起可能可以进一步提升性能;
- CHILD-TUNING_F:task-free的方法,与任务无关,伯努利分布每个W按照p_F mask掉一些;
- CHILD-TUNING_D:task-driven方法,任务相关,Fisher信息来选择任务最关键的,此外只在最开始初始化一次;
- 和模型剪枝还是有区别的,这种保留了模型的全部前向能力,motivation是不希望大幅度改变bert那种预训练模型的表征从而导致的灾难性遗忘;
References
- 知乎论文解读:https://zhuanlan.zhihu.com/p/433636342
- github code:https://github.com/alibaba/AliceMind/tree/main/ChildTuning,代码结构为什么这么简单
TODO-list
- backward过程中,掩码掉一部分的梯度是如何被决定的?作者有两种方式,CHILD-TUNING_F和CHILD-TUNING_D,分别代表task-free和task-driven的方式,
- 从理论上或者说感官上这种方法为什么能起到作用?
- 读下来abstract后感觉在下游fine-tune是一个即插即用的方法?但是目标场景是什么,是所有fine-tune的任务都可以,还是说只针对少量数据微调那种gap比较大的?
- 作者提出来的这个mask,在实现上是怎么做的?每个nn.Linear都要配上一个mask?
- CHILD-TUNING_D在代码上那个Fisher信息是怎么搞出来的?
0. Abstract
近期的预训练语言模型从数百万个参数扩展到数十亿个参数。因此,在各种下游任务中,需要使用有限的训练语料对超大预训练模型进行微调。2022.7 BigScience Large Open-science Open-access Multilingual Language Model(BLOOM):https://huggingface.co/bigscience/bloom
在本文中,我们提出了一种直接且有效的微调技术,CHILD-TUNING,它通过在backward process中策略性的掩码非子网络的梯度来更新大型预训练模型的参数子集(称为子网络)(这里指的应该是back-propagation?这个地方掩码掉一些部分是被如何决定的,从理论上或者感官上来说为什么这种方法能起到作用?) 。在GLUE基准测试中的各种下游任务上的实验表明,在四种不同的预训练模型中,CHILD- TUNING始终以1.5 ∼ 8.6的平均分超越了vanilla微调,并以0.6 ∼ 1.3分超越了先前的微调技术。
此外,关于领域转移和任务转移的实证结果表明,CHILD-TUNING能够以较大的幅度获得更好的泛化性能。
读下来abstract后感觉在下游fine-tune是一个即插即用的方法?但是目标场景是什么,是所有fine-tune的任务都可以,还是说只针对少量数据微调那种gap比较大的?一些博客中提到可以作为trick使用
1. Introduction
一般来说
最近,预训练语言模型PLM对自然语言处理NLP领域产生了显著影响。预训练和微调已经成为NLP的一个范式,主导了大量的任务,
尽管它取得了巨大的成功,但如何将这种具有百万到数十亿参数的大规模预训练语言模型适应于各种场景,尤其是训练数据有限的情况下,仍然是一个挑战。由于容量极大,标注数据有限,传统的迁移学习倾向于积极的微调(aggressive fine-tuning),导致
1)由于过拟合,测试数据的结果退化了;
2)转移到域外数据或者其他相关任务中的概括能力差;
防止fine-tune后的模型偏离预训练的权重太多(即较少的知识遗忘)被证明是有效的,以减轻上述挑战(这里见过的方法是把bert那些层和后面fine-tune那些层设置不同的学习率,bert那边设小一点慢调,后面设大一点开始快调) 。例如RecAdam在微调权重和预训练权重之间引入了L2距离惩罚。此外,Mixout在微调过程中使用预训练的权重随机替换了部分模型参数,他们背后的核心思想是利用预训练的权重来规范微调模型。
在本文中,我们提出从一个新的角度来缓解积极微调的问题。**基于在微调过程中没有必要更新大尺度模型中的所有参数这一观察 **,我们提出了一种有效的微调技术,CHILD-TUNING,他通过战略性的掩码掉非子网络的梯度,直接更新一个参数子集(称为子网络),如图1所示。请注意,他与模型修剪不同,因为他仍然在整个模型上进行前向传播,从而充分利用了隐藏在预训练权重中的知识。
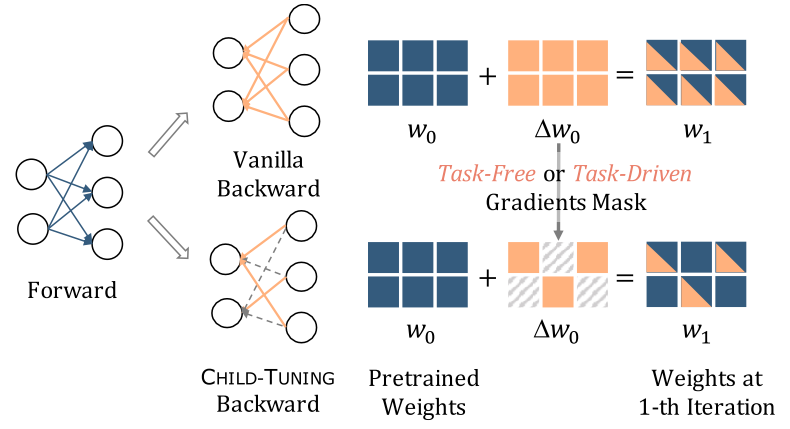

Figure1:CHILD-TUNING的示意图。左图:在前向传播forward的时候在整个网络上,然而在backward反向传播的时候在网络的一个子集上(举例:child network)。右图:为了实现这一点,对非子网络的梯度进行无任务或者任务驱动的mask,将其重置为0(灰色网格)。(自己理解上面这个图来说的话,delta就是那个梯度,w=w+lr*deltaw,于是把其中一些的梯度设置为0,他们的参数在反向传播的过程中则不会更新)
具体来说,我们提出了两个变体,CHILD-TURNING_F和CHILD-TURNING_D,分别以无任务(task-free)和任务驱动(task-driven)的方式检测子网络。CHILD-TURNING_F在没有任务数据的情况下,通过伯努利分布选择出子网络。它为全部梯度引入了噪声,起到了正则化的作用,从而防止了对小数据集的过度拟合,导致了更好的泛化(更好泛化是因为一定程度上保留了pretrainmodel的能力?) 。进一步的,CHILD-TUNING_D利用下游任务数据检测与任务最相关的参数作为子网络,并将非子网络的参数冻结在其预训练的权重上。它通过应用于全梯度的特定任务掩码减少了模型的假设空间,有助于有效地使大规模预训练模型适应各种任务,同时极大地保留了其原有的泛化能力。选择性的梯度裁剪?目前从这段文字还暂时有点不清楚这两个的区别和具体是怎么实现的
我们在GLUE基准上的大量实验表明,CHILD-TUNING在微调不同的PLM方面可以更加出色,与vanilla微调相比,在CoLA/RTE/MRPC/STS-B任务上平均得分提高了8.60分(将在3.3节进一步详述)。此外,它在转移到域外数据和其他相关任务中实现了更好的泛化能力(将在3.4节进一步详述)。实验结果还表明,CHILD-TUNING产生的改进始终比最先进的微调方法大。更重要的是,由于CHILD-TUNING与这些先前的方法是正交的,将CHILD-TUNING与它们整合在一起甚至可以导致进一步的改进(将在4.1节进一步详述)。总而言之,我们的贡献有以下三个方面:
- 我们提出了CHILD-TUNING,这是一种直接而有效的微调技术,只更新子网络的参数。我们探索以无任务和任务驱动的方式检测自网络。从motivation解释来说,好像就是在fine-tune过程中没有必要更新所有的,选一部分子网来更新,同时也保证了泛化能力,增强fine-tune效果,并且与之前的方法是正交的 ;
- CHILD-TUNING可以有效地使大规模训练模型适应各种下游场景,从域内到域外,以及跨任务transfer学习;
- 由于CHILD-TUNING与先前的微调方法是正交的,将CHILD-TUNING与它们整合在一起可以进一步提高微调性能;
2. Methodology
作者选择把methodology放在第二章来写了,这章公式比较多也比较硬核
为了使大规模预训练的语言模型更好的适应各种下游任务,我们提出了一种简单而有效的微调技术,即CHILD-TUNING。我们首先在backward过程中引入梯度掩码,以达到更新一个参数子集的目的(i.e. child network),伴随着在前向forward过程中仍然利用整个大模型的知识(将在2.1节详述)。然后,我们探讨了两种检测CHILD-NETWORK的方法(i.e. 生成不同的梯度掩码),CHILD-TUNING_F是一种task-free的方式(将在2.2节详述),CHILD-TUNING_D是一种task-driven的方式(将在2.3节详述)。
2.1 Overview of CHILD-TUNING
在介绍CHILD-TUNING的时候,我们首先给出了一个vanilla微调过程中反向传播的一般表述。我们把第t次迭代时的参数模型表示为w_t(w_0代表预训练模型的weights)。vanilla微调计算损失函数L(w_t)的梯度,然后对所有参数应用梯度下降法,可以表述为:

其中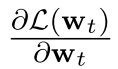 代表模型针对参数w_t的梯度, $\eta$代表学习率。这里就是普通的梯度下降
代表模型针对参数w_t的梯度, $\eta$代表学习率。这里就是普通的梯度下降
CHILD-TUNING也像标准微调一样,反向的计算所有可训练学习参数的梯度。然而,关键的区别在于,CHILD-TUNING在第t次迭代时确定了一个子网络C_t,并且只更新这部分参数。为了实现这一点,我们首先定义一个与w大小相同的0-1掩码,如下所示:
这个从代码上是怎么实现的,看起来还挺好懂的,每个nn.Linear都配上一个M?
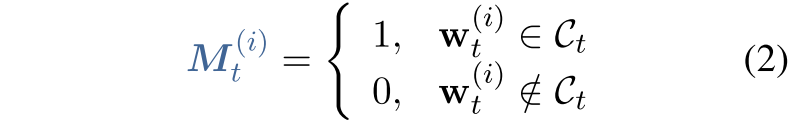
其中$M_{t}^{(i)}$和$w_{t}^{(i)}$分别代表mask M_t的第i个元素和第t轮次训练迭代的参数w_t。在第t个turn时,w这个向量的第i个位置是否属于C_t,注意W是向量,比如nn.Linear()这样的一个矩阵 。然后,我们通过简单地用以下等式替换等式1来正式定义CHILD-TUNING技术:
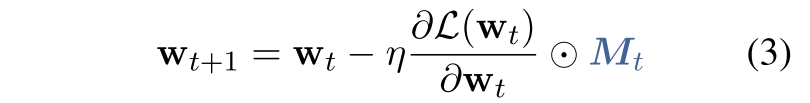
当应用于广泛使用的Adam优化器时,Algorithm1提供了CHILD-TUNING的伪代码。主要区别在于插入了第5-7行。

这里也是说CHILD-TUNING_F是每次初始化一个新的C?每次optimizer.optimize的时候的时候初始化一个C!这样干掉一些梯度
2.2 Task-Free Variant: ${\rm CHILD-TUNING}_{F}$
在本节中,我们首先探讨不需要任何下游任务数据的子网络选择,即称为CHILD-TUNING的task-free技术。具体来说,CHILD-TUNING_F在第t次迭代时候生成一个0-1mask M_t,该mask M_t来自概率为p_F的伯努利分布按照下面的定义,是1的概率就是p_F,即mask掉了1-p_F的 。**p_F是保留下来的!!! **


p_F越高,子网络规模越大,因此更新的参数也就更多。当p_F=1时,CHILD-TUNING_F退化为vanilla的微调方法。请注意,我们还将剩余的梯度扩大了1/p_F,其保持梯度的期望值。
我们从理论上证明了 CHILD-TUNING_F的有效性。我们用∆w代表每次迭代的更新量。
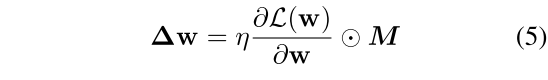
直观的说,定理1表明梯度的方差是p_F的严格递减函数。因此CHILD-TUNING_F改善了梯度的方差,探索和开发之间的权衡可以通过调整p_F来控制。p_F扩大,梯度的方差减小,即保留下来的越多,梯度方差越小

定理2所示,随着方差的增大,模型可以收敛到更平坦的局部最小值(定理2中的ρ较小)。受到研究表明平坦的最小值倾向于更好的泛化的启发,我们可以进一步证明CHILD-TUNINGF降低了泛化误差的界限。

因此,CHILD-TUNINGF可以被看作是优化过程的一个强大的正则化。它使模型能够跳过损失景观中的鞍点,并鼓励模型收敛到一个更平坦的局部最小值。有关所述定理和证明的更多细节,请参考附录E。
每次都是一个地方梯度最大,但是每次把那个地方都mask掉,就不收敛;;;证明了能收敛,然后能收敛到更平滑的,实现了一个无监督的剪枝?
训练时:前向的时候走了所有的,反向的时候只把子网络的参数更新;预测推理时?
2.3 Task-Driven Variant: ${\rm CHILD-TUNING}_{D}$
考虑到下游的标记数据,我们提出了CHILD-TUNING_D,它可以检测出对目标任务最重要的子网络。具体来说,我们采用Fisher信息估计法来寻找与特定下游任务高度相关的参数子集。Fisher信息是一个很好的方法,可以提供一个随机变量携带多少关于分布参数的信息的估计。对于一个预训练模型,Fisher信息可以用来衡量网络中的参数对下游任务的相对重要性。
这里也是对其中的数学原理不太了解,
形式上,模型参数w的Fisher信息矩阵(Fisher Information Matrix, FIM)定义如下:
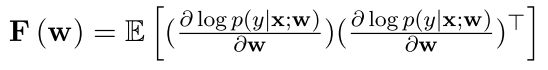
其中x和y分别代表input和output 这里E是期望的意思 。它也可以被看作是对数似然的梯度相对于参数w的协方差。按照Kirkpatrick等人(2016)的说法,给定特定任务的训练数据数据D,我们使用经验FIM的对角线元素来点估参数的任务相关重要性。从形式上看,我们得出第i个参数的Fisher信息如下这里第i个参数,就是w这个向量中的第i个位置 :
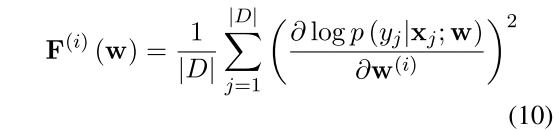
自己再尝试理解下这个公式:在已知xj和w的情况下,获取yj的概率越大,那么代表wi可能有没有都无所谓了?
换句话说,当已知xj和w的时候,获取yj的概率很小,那么wi的梯度会很大,求和后平均,认为wi是很关键的?
这个CHILD-TUNING_D不知道在代码上的大概是怎么实现的
我们认为,参数对目标任务越重要,它所传递的Fisher信息就越高。因此,子网络C是由信息量最大的参数组成的。子网络的比例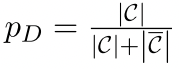 $\in (0, 1]$,其中
$\in (0, 1]$,其中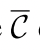 代表non-child网络(非子网络部分)。随着pD的上升,子网络的规模也在增加,当pD=1时,它就退化为vanilla的微调策略。
代表non-child网络(非子网络部分)。随着pD的上升,子网络的规模也在增加,当pD=1时,它就退化为vanilla的微调策略。
由于获得任务驱动(task-driven)的子网络的开销比无任务(task-free)的子网络的开销要大,我们在微调开始时简单地得出CHILD-TUNING_D的子网络,并在微调期间保持不变。(i.e. 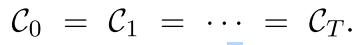 ) 这里也是说CHILD-TUNING_F是每次初始化一个新的C?每次optimizer.optimize的时候的时候初始化一个C!这样干掉一些梯度
) 这里也是说CHILD-TUNING_F是每次初始化一个新的C?每次optimizer.optimize的时候的时候初始化一个C!这样干掉一些梯度
通过这种方式,CHILD- TUNINGD极大地减少了大规模模型的假设空间,从而缓解了过拟合。同时,将非子网冻结在预训练的权重上,可以从根本上保持泛化能力。
3.Experiments
3.1 Datasets
GLUE benchmark:跟随以前的研究,我们在GLUE排行榜的各种数据集上进行了实验,包括语言上的可接受性(Linguisitc Acceptability任务,CoLA数据集)、自然语言推理(Natural Language Inference任务,RTE、QNLI、MNLI数据集)、释义和相似性(Paraphrase and similarity任务,MRPC、STS-B、QQP数据集)、情感分类(Sentiment Classification任务,SST-2数据集)。
CoLA和SST-2是单句分类任务,其他任务涉及一对句子。详细可见附录A中的说明。
按照大多数以前的工作,我们在训练集上对预训练模型进行微调,并使用最后一个检查点直接报告设计集的结果,因为测试结果只能通过排行榜访问,有提交数量的限制。
NLI datasets:在本文中,我们还进行了实验以探索基于几个自然语言推理任务的微调模型的概括能力。在阅读SimCSE论文的时候对这个数据集有一些了解,一句前提对应蕴含、中立、矛盾的多句话,但是对评价指标还没什么了解,应该是给两句推理他们之间的关系吧
我们额外介绍了三个NLI数据集,即SICK(Marelli等人,2014)、SNLI(Bowman等人,2015)和SciTail(Khot等人,2018)。我们还报告了与GLUE一致的dev集的结果
其他章节的experiment暂时跳过,粗读着重读一下方法
4. Analysis and Discussion
这个部分挑一些自己觉得重点的记录一下,背后有一种motivation的感觉;
4.1 Comparison with Prior Methods
不仅超过了vanilla fine-tune,还超过了一些专门的fine-tune方法;
4.2 Result in Low-resource Scenarios
we explore the effect of CHILD- TUNING with only a few training examples,还是比vanilla效果好
这表明,尽管当训练数据处于极端低资源的情况下,过拟合现象相当严重,但CHILD-TUNING仍然可以有效地改善模型的性能,特别是对于CHILD-TUNINGD,因为它减少了模型的假设空间
It suggests that although overfitting is quite severe when the training data is in extreme low-resource scenarios, CHILD-TUNING can still effectively improve the model performance, especially for CHILD-TUNINGD since it decreases the hypothesis space of the model
4.3 What is the Difference Between CHILD-TUNING and Model Pruning?
Model Pruning有一种模型剪枝,或者缩减模型大小那个感觉,这个原理上还是很不一样的
CHILD-TUNINGD以任务驱动的方式检测最重要的子网络,在微调过程中只更新子网络中的这个参数,其他参数冻结。它很可能与模型修剪相混淆,后者也是检测模型中的子网络(但随后删除其他参数)。
实际上,”CHILD-TUNING “和模型修剪 在目标和方法上都是不同的。就目标而言,模型修剪的目的是提高推理效率,同时保持性能,而CHILD-TUNING的提出是为了解决过拟合问题,并在微调时提高大规模语言模型的泛化能力。根据不同的方法,模型修剪在推理过程中放弃了不重要的参数,而不属于子网络的参数在训练和推理过程中仍然保留给CHILD-TUNING。通过这种方式,隐藏在预训练权重中的非子网络的知识将得到充分的利用。模型裁剪可能性能就降下来了?而这里的CHILD-TUNING更像是一个regulazation方法
为了更好地说明CHILD-TUNINGD与模型修剪相比的有效性。TUNINGD与模型修剪相比,我们将所有不属于子网络的参数设置为零,这在表5中被称为Prune。表中显示,一旦我们放弃了子网络中的参数,在四个任务(CoLA/RTE/MRPC/STS-B)上的得分就急剧下降了33.89分,模型甚至在CoLA任务上崩溃了。这也表明,在儿童网络中的参数,非儿童网络中的参数也是必要的,因为它们可以提供在预训练中学习到的一般知识。
4.4 Is the Task Driven Child Network Really that Important to the Target Task?
CHILD-TUNINGD通过选择对下游任务数据具有最高Fisher信息的参数来检测特定任务的子网络。在本节中,我们将探讨检测到的任务驱动的子网络对任务是否真的那么重要。
为此,我们介绍了两项消融研究 为CHILD-TUNINGD:1)随机。我们随机选择一个子网络,在微调期间保持不变;2)最低信息。我们选择那些具有最低Fisher信息的参数作为子网络,与CHILD TUNINGD中采用的最高Fisher信息形成对比。
如表5所示,随机选择子网络甚至可以胜过vanilla微调,平均得分提高0.18。这支持了我们的主张,即没有必要更新大型PLM的所有参数,减少假设空间可以减少过拟合的风险。然而,仍然值得寻找一个合适的子网络来进一步提高性能。如果我们选择Fisher信息最低的参数(Lowest Fisher),与选择CHILD-TUNINGD中采用的Fisher信息最高的参数相比,平均得分急剧下降6.65。因此,我们可以得出结论,CHILD-TUNINGD检测到的Child net对下游任务确实很重要。
4.5 What is the Relationship among Child Networks for Different Tasks?
如我们所料,类似的任务往往有较高的子网络重叠率。
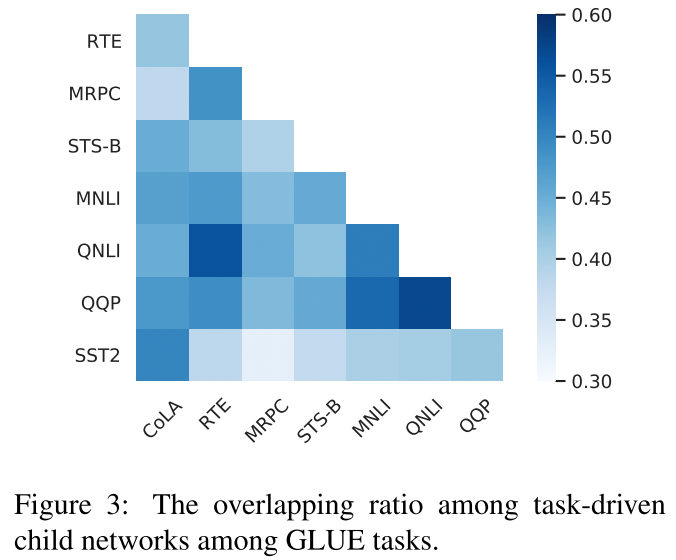
GLUE任务中任务驱动的子网络之间的重叠率。
6. Conclusion
为了缓解过拟合问题并提高微调大规模PLM的通用性,我们提出了一种简单而有效的微调技术–CHILD-TUNING,它在微调过程中只通过战略性地掩盖非子网络的梯度来更新子网络。引入了两个变体:CHILD-TUNING_F和CHILD-TUNING_D,它们分别以无任务和任务驱动的方式检测子网络。在各种下游任务上的大量实验表明,在四种不同的预训练语言模型中,这两种方法都能以较大的收益超过vanilla微调和先前的工作,同时在很大程度上提高了微调模型的泛化能力。由于CHILD-TUNING与大多数先前的微调技术是正交的,因此将CHILD-TUNING与它们结合起来可以进一步提高性能。
代码学习
对于CHILD-TUNRING_F应该在optimizer那块简单换一下就可以直接用
1 | |
可以和如下的对比,但这里感觉有些不一样的,作者把一个functional中的for i, params in enumerate(params):合并到一块写了的感觉
1 | |
https://pytorch.org/docs/1.8.0/_modules/torch/optim/adamw.html#AdamW
每次只更新固定的参数,因为CHILD在一开始固定住了
taskfree的时候,为什么这样做就能让更好?task-driven的时候还可以用bert学习率要小一些那套理论来解释
取出来12个CLS,接一个映射层 /// 模型蒸馏,12层->6层,fast-BERT,横着剪枝;;drop纵着减
对于CHILD-TUNING_D,看起来像是在开始的时候跑了一遍,然后给到了一个gradient_mask
1 | |

整体感觉上应该还是相对比较即插即用的