acl2021_CLINE论文阅读
acl2021_CLINE论文阅读
总结贡献:
- 用同/反义词构造正负例,三个损失:①MLM;②预测每个token是否被替换,0/1二分类;③对比损失,即正例拉近,反例远离
reference
https://blog.csdn.net/qq_33161208/article/details/123631813 # ACL2021 | 对比学习8篇论文一句话总结
0. Abstract
尽管预训练的语言模型已被证明有助于学习高质量的语义表征,但这些模型仍然容易受到简单的扰动。
这个受到简单的扰动该怎么理解:从作者在Introduction章节给出一个图的例子中解释来说,进行简单的同义词替换模型预测可能会相反,而进行简单的反义词替换模型可能还会保持原来的预测,反映出模型在与语义鲁棒性上的不足
近期旨在提高预训练模型鲁棒性的工作,主要集中在从具有类似语义的扰动实例中进行对抗性训练,而忽略了对不同甚至相反语义的利用。与图像处理领域不同的是,文本信息是离散的,几个字的替换就能引起重大的语义变化;
为了研究由小的扰动引起的语义变化的影响,我们进行了一系列的试点实验,并令人惊讶的发现对抗性训练(adversarial training)对于模型检测这些语义变化是无用的,甚至是有害的;
为了解决这个问题,我们提出使用语义负例进行对比学习(Contrastive Learning with semantIc Negative Examples, CLINE),它在无监督的情况下构建语义负例,以提高在语义对抗性攻击下的稳健性;
这个语义对抗性攻击也可以理解为,我只是简单替换一些同义词模型可能预测结果就变了,我可能替换了一些反义词模型结果还是不变
通过在相似和相反的语义例子之间进行比较,该模型可以有效地感知由小的扰动引起的语义变化。实证结果表明,作者的方法在一系列的情感分析、推理和阅读理解任务中产生了实质性的改善。而且,CLINE还确保了同一语义下的紧凑性和句子级不同语义的可分离性。
TODO 还要看看这个语义紧凑性、句子级不同语义的可分离性作者是怎么解释的
1. Introduction
自己对Introduction章节的理解是综述研究背景,综述一下别人的方法和存在的不足,最后再说一下自己的方法和主要贡献,大概就按照这几个方面总结一下Introduction章节
1.1 研究背景
预训练语言模型,例如BERT和RoBERTa的出现可以有效各项自然语言处理任务的表现。然而近期的研究发现BERT模型在遇到对抗性的例子时鲁棒性很差。作者举例如下“creepy but ultimately unsatisfying thriller(令人毛骨悚然但最终不尽人意的惊悚片)”这句本意的话,label被标注为Negative的,预测也是Negative的,从人类角度应该可以看出这句话的核心集中在“unsatisfying”上,但是只是简单替换“ultimately”->“lastly”(同义词替换)就使得bert这个模型预测错了,同样的完全 反义词替换 “unsatisfying”->“satisfying”模型也预测错了,作者给出的表述是“the BERT model can be fooled easily just by replacing ultimately with a similar word lastly.”

1.2 已有的研究工作和存在的不足
为了提高PLM的稳健性,一些研究工作试图在PLM上进行对抗性的训练,即在训练的过程中对词嵌入进行基于梯度的扰动,或者在训练阶段增加高质量的对抗文本实例。这些对抗性的方法主要目标是在输入发生微小变化时保持标签不变,通过构建高质量的扰动实例并产生对抗机制,产生了有希望的性能;
对这两块工作还是有点不太了解,这里特别强调了一个高质量可能是为了引出CL方法self-supervised的不需要手工构筑大量标签的意思?
或者说这里想说的也有点生成对抗那个地方的感觉?生成对抗那边目前理解和CL比较大的区别是多出来一个生成步骤,generator需要生成一个例子那种感觉,然后discriminator来辨别这个示例,多引入的生成就多出了很多的问题,包括生成可靠性等?
然而,由于自然语言的离散性,在许多情况下,小的扰动就会引起句子语义的重大变化,就像上面那个例子展示的,只是改变了一个词,模型就将gt为Negative的预测为Positive了。一些近期的研究工作创建了对比集合(Contrastive sets),以小而有意义的方式手动扰动测试实例,从而改变了gt label。在本文中,作者把没有改变语义的扰动实例表示为对抗性例子,把改变了语义的例子表示为对比性的例子,motivation也考虑到大多数PLM鲁棒性的研究工作主要把方法集中在对抗性例子的研究中,而较少有考虑到语义负面的例子。
这里结合作者说的abstract也能想到简单的“数据增强”或者被称作“数据扩充”方法,执行同义词替换就可以简单的收集到很多的对抗性例子,执行反义词替换就可以简单的收集到很多对比性的例子,之前SimCLR中的aug1 aug2那种感觉
现有研究现象(较多考虑到对抗性例子,而较少考虑到对比性的例子)让作者开始想要探究,能否通过使用对抗性和对比性的例子来训练一个既能够抵御对抗性攻击,又能通过使用对抗性例子和对比性例子对语义变化敏感的BERT。为了解决这个问题,需要评估目前的vanilla模型(可以翻译为香草模型,也可以翻译为稳健模型)是否同时具有语义敏感性。在进行的几组对比vanilla PrLM 和 经过对抗性训练的PrLM中发现,虽然对抗性训练提高了PLM应对对抗性攻击的能力,但其在对比性的例子上表现却下降了

这里IMDB是一个影评数据集从文章里给的这个例子来看,蓝色那些地方应该是换了一些对比性(也就是反义)的词汇?
对抗性的例子:执行一些同义词扰动替换,但是不改变原来句子的含义
对比性的例子:执行一些反义词的扰动替换,同时改变了橘子的含义

1.3 作者自己方法的简述
为了训练一个具有语义健壮性的PLM,提出基于语义反义示例的对比学习方法(Contrastive Learning with semantIc Negative Examples,CLINE)。这是一种简单有效的方法可以产生对抗性和对比性的例子,并从两个例子中进行对比性的学习。
许多工作证明了对比性的学习已经在学习句子表征方面取得了有效性的研究进展,然而这些研究忽略了负面实例的生成。在CLINE中,作者引入了WordNet的外部语义知识,通过无监督地替换少数有代表性的标记来产生对抗性和对比性的例子。通过替换标记检测和对比性目标,作者的方法收集了具有可理解语义的相似性句子,和具有不同甚至相反语义的分散句子,该方法通过替换标记检测和对比目标,收集具有语义相似的句子,分散具有不同甚至相反语义的句子,同时提高了PLMs的鲁棒性和语义敏感性。
负面实例的生成,这里替换标记检测和对比目标应该是指loss那边,替换标记检测指的是判断每个token是否是被替换的,而对比性目标就是CL相关的loss
如果作者这么描述的话,有个问题是真的能检测出来token是被替换的吗,因为只是换了相同或者相反词性的词,也可能这样就会对语义连贯性一些造成影响?
实验证明,在几个对比性测试集上取得改善,在几个对抗性测试集上也取得改善,也就是说CLINE同时获得了对抗性攻击的鲁棒性,和语义变化的敏感性
以往的方法只能获得对抗性攻击的鲁棒性,但是对语义变化的敏感性就有所不足
2. Pilot Experiment and Analysis
这个章节在之前很少见,预实验及分析,可能未来一些内容可以参考下这个写法
为了研究对抗性训练方法在对抗性集合和对比性集合上的表现,我们首先进行试点实验(Pilot Experiment)并在本节中进行详细分析。
2.1 Model and Datasets
其中我们选择了一种流行的方法,TextFooler(Jin等,2020),作为词级的对抗性攻击模型来构建对抗性例子。
选择之前研究者构建的IMDB、SNLI作为对比集
我们选择了一种对抗性训练方法FreeLB(Zhu等,2020)作为我们的试点实验。我们对vanilla的BERT(Devlin等,2019)和RoBERTa(Liu等,2019)以及FreeLB版本在对抗性集合和对比性集合上进行了评估。
2.2 Result analysis
与vanilla版本相比,对抗性训练方法FreeLB在对抗性测试集上取得了更高的准确率,但在对比性测试集上却有相当大的性能下降,特别是对于BERT。这些结果与第1节中的直觉一致,同时也证明了对抗性训练不适合于对比性集合,甚至会带来负面的影响。
直观地说,对抗性训练倾向于保持标签不变,而对比性集合倾向于进行小的但改变标签的修改。对抗性训练和对比性例子似乎构成了一个天然的矛盾,揭示了需要在训练阶段应用额外的策略来检测语义的细微变化
2.3 Case Study
上面table3那个例子进一步分析(被BERT的vanilla版本预测正确,但被FreeLB版本预测错误)
对于标签3中的例子,我们可以观察到,许多部分在句子中表达了积极的情绪(红色部分),而少数部分则表达了消极的情绪(蓝色部分)。总的来说,这个例子表达的是负面情绪,而vanilla BERT可以准确地捕捉到整个文档的负面情绪。然而,FreeLB版本的BERT可能会将负面情绪的特征作为噪音,并将整个文档预测为正面情绪。这一结果表明,经过对抗性训练的BERT可以以与传统对抗性训练相反的方式被愚弄。这里的理论性不是很强吧,一个这样的例子说明不太了什么?
从这个案例研究中,我们可以看到,对抗性训练方法可能不适合这些语义改变的对抗性例子,而且就我们所知,目前还没有针对这种对抗性攻击的防御方法。因此,探索适当的方法来从语义负面的例子中学习变化的语义是至关重要的。
3. Method
CLINE,一种简单而有效的方法来生成对抗性和对比性的例子,并从它们中学习。

3.1 对抗性(Adversarial)与对比性(Contrastive)实例的生成
希望通过对比具有相同和不同语义的句子,对语义变化更加敏感。采用了对比学习的思想,拉进positive pair之间的学习表征而推开negative pair之间的学习表征,因此定义如何配对是非常重要的。在本文中将具有相同语义的句子视为正向对,将具有相反语义的句子视为负向对。
一些研究试图利用数据增强(如同义词替换、回译等)来生成正面实例,但很少有作品关注负面实例。而且,要获得文本实例的相反语义立场是很困难的。直觉上,当我们用反义词替换句子中的代表词时,句子的语义很容易与原始句子无关甚至相反。如图1所示,假设句子“Batman is an fictional super- hero written by”,我们可以用反义词“real-life”替换“fictional”,然后我们得到一个反事实的句子“Batman is an real-life super-hero written by”。后者与前者相矛盾,并与之形成负对。
如图所示的,$ x^{syn} $是对抗的例子,$ x^{ant} $ 是对比的例子,我们从原始input $ x^{ori} $生成这两个语义大不相同,但是词汇却没有几个不同的句子,其中对抗的例子$ x^{syn} $在语义上与$ x^{ori} $接近,而对比的例子$ x^{ant} $的语义与$ x^{ori} $大大相反。具体来说,作者使用了spaCy这个工具对原始句子进行分割和词性(POS)提取动词、名词、形容词和副词。$ x^{syn} $是通过用同义词、超义词和形态变化替换提取的词而产生的,$ x^{ant} $是通过用反义词和随机词替换它们产生的。对于$ x^{syn} $大约有40%的标记被替换。对于$ x^{ant} $,大约20%的标记被替换。
具体怎么制作对抗和对比的实例操作在上面这个地方,这个应该就是self-supervised的那个感觉了,自己能够构建出标签来
这个地方听起来还是挺硬性的
3.2 Training Objectives
CLINE的目标是训练neural text encoder(deep transformers)$ E_{\phi} $,其中$\phi$代表网络的参数;类似于BERT那种感觉,对于输入$x = [x_{1},…,x_{T}]$来输出一个$h = [h_{1},…,h_{T}]$,其中每个$h_{i} \in \R^{d}$,d代表hidden_size的维度;

3.2.1 Masked Language Modeling Objective
作者也使用到了BERT那个MLM,随机将一些token用[MASK]替换掉,然后对这些token进行预测,表示为$\ L_{MLM}$

3.2.2 Replaced Token Detection Objective

把h过线性层后,再过sigmoid激活函数(这里因为是多分类问题,所以是sigmoid激活函数而不是softmax激活函数那个感觉),过完sigmoid后实际上是对每个位置得到了一个logit(或者说score),然后通过类似交叉熵损失函数度量 $\ L_{RTD}$

3.2.3 Contrastive Objective(与对比学习更加相关?)
CLINE的直觉是准确地预测当原始句子被修改时,语义是否发生了变化,从距离度量上来说,要使得 $ h^{ori} $和 $ h^{syn} $尽量接近,而使得$ h^{ori} $和 $ h^{ant} $尽量远离。于是在对比学习的操作上,把$(x^{ori}, x^{syn})$看做positive pair,把$(x^{ori}, x^{ant})$看做negative pair,使用[CLS]那个token $ h_{c}$于是通过下面这个函数计算相似度
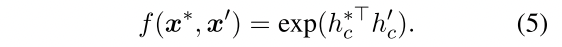
这里有个问题是为什么这样能通过两个向量点积计算相似度,同样也是BERT中Q·K^T的那个地方的疑问:两个向量点乘就是用来计算相似度的,u·v如果u和v是向量的话,那么点乘起来就是|u||v|cosθ,反应一个向量在另一个向量上的投影,如果越大代表两个向量越相似
然后通过下面这个InfoNCE loss来度量,注意因为这里是一对一对的,分母那里就没有求和了,作者的解释是:请注意,与一些通常随机抽取多个反面例子的对比策略不同,我们只利用一个反面例子作为训练的对象。这是因为我们预训练的主要目标是提高语义对抗下的鲁棒性。而且,我们只关注为我们的目标而产生的负面样本(即xant),而不是任意地从预训练语料库中抽取其他句子作为负面样本。

3.2.4 最终的损失函数
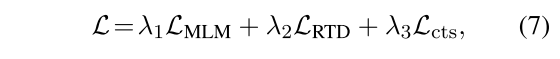
大概能明白这个损失函数的意思,但是每个损失函数具体怎么得到还需要再整理下
4. Experiments
这个地方implement details比较重要,不知道他这里说的32块32G显卡指的是他还是之前的pretrain
To better acquire the knowledge from the existing pre-trained model, we did not train from scratch but the official RoBERTa-base model.
The model is pre-trained on 32 NVIDIA Tesla V100 32GB GPUs. Our model is pre-trained on a combination of BookCorpus (Zhu et al., 2015) and English Wikipedia datasets, the data BERT used for pre-training.
前面预测token有没有被替换这个任务的时候,bert encoder的参数是不是被更新了?是不是共用的bert encoder?