Contrastive Learning 初步调研&了解
Contrastive Learning 初步调研&了解
1 | |
References
https://www.zhihu.com/zvideo/1296467630460039168
https://zhuanlan.zhihu.com/p/450561239
https://zhuanlan.zhihu.com/p/471018370
Ashish Jaiswal, Ashwin Ramesh Babu, et.al, A Survey on Contrastive Self-Supervised Learning.
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations.
Tian Li , Xiang Chen, et.al. CROSS-DOMAIN SENTIMENT CLASSIFICATION WITH CONTRASTIVE LEARNING AND MUTUAL INFORMATION MAXIMIZATIO.
Daniela N. Rim, DongNyeong Heo, Heeyoul Choi, Adversarial Training with Contrastive Learning in NLP.
1. 基础概念Overview
直觉非常符合人类,在分辨多种东西的时候不需要记住每个细节,需要记住最少的东西把这几个东西分开就可以了;
1.1 Motivation and Intuition
目标是在Unsupervised Learning(无监督学习即无标签)场景下的,把每个instance当成一个class。比如说有一根笔,还有另一根笔, 在分类的时候这两个是应该分类到一类的,在CL里面就是把每一个instance都分开。
为什么研究这个问题,在Supervised Learning(监督学习)中有很多问题:1)数据是非常高维的他是很难学的;2)另外拿到label是有cost的,生活中有很多数据但是label却没有那么多;3)有task specific solution,训练了一个猫狗分类器,现在又来了一个兔子就没法分开了,如果是Unsupervised,学到某个class的feature,这些feature是可重复利用的, 可能能用到很多种不同的task里面去;
主要可以分为两大类的方法,第一类是Generative(Predictive)生成的,第二类是Contrasitive(Discriminative)鉴别的。Generative主要是干比如VAE,reconstract sample,输入图片然后重构这个图片【之前看到关系抽取领域的Gaussian Graph Generator】,对于Contrasitive和Generative不一样的是不需要reconstract,而只是需要把不同的instance分开就可以了,好处是实际上不需要学的很细节,比如pixel level的可能就可以省去一些计算资源,另外pixel之间不应该是单独考虑的,应该学习到一些correlation的global的内容
1.2 Introduction
Notation:Anchor、Positive sample、Negative sample,拿一个纸盒子举例的话, 一个纸盒子两个不同角度拍两张照片,一个竖着一个横着,那么这个pair是属于同一个物体的,就一个当做anchor一个当做positive sample。然后给另外一个纸盒子拍照片,另外这个纸盒子就是一个negative sample。总结来说,是同一个类型的就可以是一个positive pair,不同类型的就是negative pair。这里背后隐含着 $ {score}(f(x),f(x^{+})) >> {score}(f(x),f(x^{-}))$
NCE Loss优化上来说类似于softmax的原理,对于一个anchor,softmax使得相关性越大的,在这种整体衡量上loss更小,使得anchor与所有positive sample之间的score更大?

为什么可以work,可以被解耦成两部分,positive sample和anchor尽量靠近,然后negative作为一个regularizer term分布更均匀

1.3 Contrastive Learning in NLP
有监督的学习需要大量的样本,面临着泛化能力差的问题。自监督学习(Self-supervised Learning)可以在大量无标签的数据上通过虚标的label去学习数据的通用表征方式,这种通用的表征方式可以作为特征提取器应用于各种下游任务。有了特征提取器后,在具体任务上使用较少的样本做fine-tune就能取得很好的效果,节约了标注成本。而且由于self-supervised或者说unsupervised任务的数据不需要标注特点,特征提取器可以在大量的样本上学习得到也增强了鲁棒性,提升模型泛化能力。
1 | |
自监督学习中,GAN这类的生成式模型获得了广泛应用,但是可能训练困难。更加敏捷的CL逐渐成为主流。
1 | |
1.3.1 Contrastive Learning定义
对比学习CL属于表征学习,本质是学习一种样本的表征方法,学习的目标是让样本与其对应的增强版本表征或者Embedding相距较近,不同样本的表征或者Embedding之间相距较远。给了一个例子是猴子图片和经过数据增强的猴子图片表征距离较近,而猴子图片和老虎图片的表征距离较远,被称作Pretext Task

1 | |
从训练范式上来说,就很像BERT那种预训练语言模型。梳理下流程感觉是data aug后首先输入Encoder得到一个初始embedding(对于图像可能是直接像素,对于NLP可能是一个初始的embedding),然后无标注的在data aug的作用下进行训练,通过contrasive学习来进行损失函数反向传播引导encoder参数更新////在迁移知识的时候,encoder直接进行编码就能编码到一个与类别相似的embedding,这样fine-tune就简单了很多,可能少量数据就可以;

1 | |
1.3.2 Pretext Task in NLP
自监督学习(self-supervised learning)中经常采用一种被称为Pretext Task自监督任务来训练模型,根据数据的特点构造虚标样本的技术。在NLP领域常用的用于构造Pretext Task的增强方法有:
- Center and Neighbor Word Prediction:典型代表就是训练Word2Vec的Skip-gram和CBOW 这个还不是很了解
- Next and Neighbor Sentence Prediction:句子级别的上下文预测,典型就是BERT中的NSP MLM没有写在这里,但是也算是一种?
- Autoregressive Language Modeling:单向的语言模型建模,代表作是GPT。暂时不太了解
- Sentence Permutation:在GAPT中被使用,将一定长度的文本中的句子打乱,然后预测句子的先后次序。这个听起来有点像NSP,但好像有个排序在里面?
Pretext self-supervised
1.3.4 架构


一个batch里面的负例太少了,从之前的一些batch拿过来;;;momentum (以batch为单位进行更新),第一个epoch中10个batch,到第9个batch的时候是用什么时候的参数,一直用epoch开始的参数,参数的波动太大了;;随机梯度下降,Momentum-SGD,借助于上一次更新的“速度”
- 第一种架构:端到端(End2End),只将batch内的不同样本组成的样本对作为负例,典型的代表就是SimCLR(A Simple Framework for Contrastive Learning of Visual Representations,下文2.1章节),这种方法需要强大的batch才能保证效果
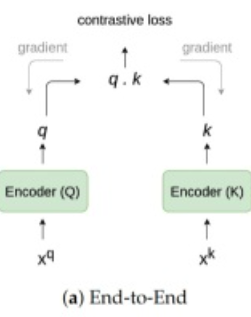
batch越大,2N-2越大,越可能在剩下的2N-2场景下出现实际上是正例的内容
- 第二种架构:TODO
看到这个架构后有点想到BBN那种把长尾数据做采样后分成两路输入的,但是这个是一对数据,那个是采样后的两张数据,分成两路训练然后融合;
1.3.5 Training Method
CL的中心思想是拉进相似的样本的表征,推开不相似的样本的表征,一般用余弦相似度来度量表征向量的距离或者相似度
$$
{\rm cos_sim}(A, B) = \frac{A \cdot B}{\left| A \right|\left| B \right|}
$$
CL一般使用NCE Loss来聚焦于对比正负样本对之间的距离或者相似度差异

如果负样本较多则采用NCE的一个变体InfoNCE
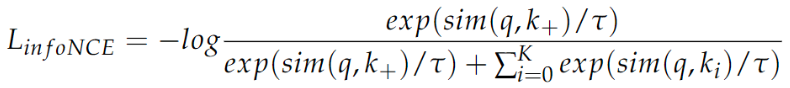
这里的$ \tau $ 有一种那个根号下dk的感觉?因为sim这个值域不是很确定或者做一个放缩来保证梯度?
这个形式上就很像softmax?
2. 论文阅读
2.1 A Simple Framework for Contrastive Learning of Visual Representations
2.1.1 abstract
SimCLR一个用于视觉对比表示学习的简单框架。简化了近期提出的对比自监督学习算法,而不需要专门的架构或存储库。为了了解是什么使得对比预测任务能够学习有用的表示,系统的研究了框架的组成部分:
1)数据增强的composition在定义有效的预测任务中起到关键作用;
2)在【表示】和【对比损失】之间引入【可学习的非线性变换】大大提高了学习表示的质量;
3)与监督学习相比,对比学习受益于更大的batchsize和训练步数;无监督的优势?
通过结合这些发现,我们能够大大优于以前在 ImageNet 上进行自我监督和半监督学习的方法。
2.1.2 结合博客论文对这篇文章的总结学习
https://zhuanlan.zhihu.com/p/389064413
SimCLR是一个比较“标准”的对比学习模型:
1)相较于之前的self-supervised模型效果有所提升;
2)采用对称结构,结构相对清晰;
3)奠定的结构,已经成为其他对比学习模型的标准构成部分;
如何构造正负例

对于某张图片,从可能的增强操作集合T中,随机抽取 t1T 与 t2T 两种,将其作用在原始图像上,形成 $ <x_1, x_2> $,两者互为正例,训练时Batch内任意其他的图像,都可以作为x1或者x2的负例
这个batch上是怎么个训练方法,用来测试的数据集上是什么数据?如果这样batch的话,只有两个正例,而负例可能有很多,会不会涉及到一些样本类别不均衡的问题?
对比表示学习希望学习到某个表示模型,能够将图片映射到某个投影空间(这里指的是一种embedding或者representation表示?) ,并在这个空间内拉近正例的距离,推远负例的距离。也就是说,迫使表示模型能够忽略表面因素,学习图像内在的一致结构信息,即学会某些类型的不变性(遮挡不变性、旋转不变性、颜色不变性等);;;SimCLR给出的图像增强方法难度提升,十分有效
在原始数据上的数据增强,后续可能有一些方法在数据表征层面做的一些数据增强
构造表示学习系统
指导原则:通过这个系统,将训练数据投影到某个表示空间内,采取某种方式使得正例距离比较近,负例距离比较远;

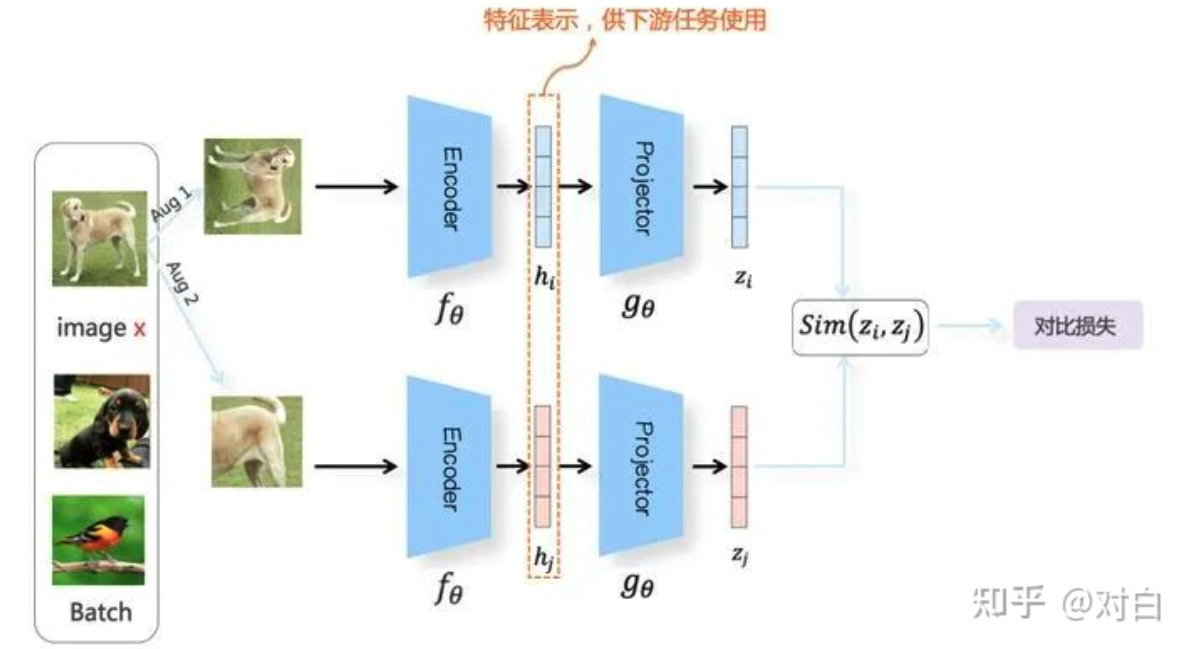
具体流程综合理解为如下,从文字描述来看有些难理解,还是看一下算法流程图:
对于batchsize为N的一个集合,对于每个元素,执行aug1和aug2,并分别过两次f和g得到h和z的representation
这样有aug1集合有N张,aug2集合有N张,两者相对应的,比如1和2是一个源数据得到的两种增强(3和4是下一个源数据得到的两种增强),这样的话除去这两张图片,剩下的2N-2是负样本;;在这2N样本中两两计算相似度,以备损失函数度量过程中使用;;;在损失函数度量上,使用的好像就是上文提到的L_infoNCE,在正样本对之间进行度量,假设1作为anchor的时候,就是1和2这个sim 比上 1和2N(除了自己)的sim这样的;;;交换anchor后,得到两种加在一起的;;;
为什么用z来进行sim度量,好像是一种经验性的做法,然后h是得到的representation,经过这样的Contrastive Learning后,得到f用于表征
作者给了很大的batch size,那么这种感觉会不会让这个类似的softmax的式子有某种变化?比如说更加难以优化,但是泛化性更强?
原始方法提出的效果只有在大batch_size的时候效果才好;;BERT就是一个典型的自监督方式,通过预训练得到的一个模型;;;大部分把自监督看做无监督,或者说虽然不需要人工标注数据,其实是自己给自己构建了label自动化的方法;
2022.7.12_补充这里loss的一些细节:https://www.jianshu.com/p/c33a79603f43


向量层面的数据增强,representation,近三年(2020)的ACL EMNLP,找几个引用比较多的,现在主要是用作表征的,先看通用一些的;;;看BERT/Transformer的实现-形成一个,代码层面定位到训练参数;;;;BERT/Transformer的论文仔细读一下,Attention is all you need,positional embedding相对绝对?哪些点是有助于模型这些效果

d_model 是什么然后根号下
到8月写实习生考勤表的时候,细化到每周做了什么,