正则表达式学习
在刷LeetCode的时候发现很多恶心的字符串规则判断题目都可以转化成正则表达式来做,也正好通过这些题来熟悉下正则的用法,未来还是希望能自己在不查的情况下凭空写出来正则的~
另外作为一个nlp的同学,正则不会还是差点意思啊哈哈哈,这个博客可能以后会不断扩充吧~
菜鸟工具在线正则表达式验证工具:https://c.runoob.com/front-end/854/
正则总结
匹配数字相关
\d 是匹配一个数字(0到9),在程序实现上一般需要再用 \ 转义一下,即 \\d
如果要匹配多个数字的话,就使用 \\d+,这里 + 代表一个或者多个
如果要匹配小数,中间带着小数点 . 的话,就是 \\d+.\\d+,注意这里还没有加入正负号的匹配
加号 + 与乘号 *
* 表示匹配前面的字符0个或多个
+ 表示前面的字符1个或多个
问号 ?
直接跟在表达式后面,表示匹配前面的一次或者零次,类似于{0, 1}的用法,[+-]{0,1}\\d+.\\d+ 和 [+-]?\\d+.\\d+ 应该是等价的意思,匹配前面有没有+-这些符号
指数符^ 和 dollar符 $
^ 用来匹配起始位置,$ 用来匹配结束位置,配合使用一般用作检验,比如检验一段文本是否只包含数字 ^[0-9]*$
如果 ^ 使用在中括号中,则有一种not的感觉
小括号 ()
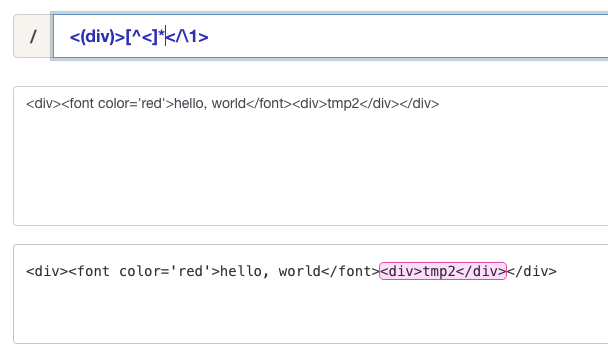
小括号起到了一种组的概念,首先可以按照顺序使用 \\1,\\2 进行访问匹配,例如在html/xml标签的匹配中,可以用 <(div)>[^<]*</\\1> 来进行匹配div标签,这样中间 [^<]* 的意思就是匹配不是 < 的任意字符,后边的 </\\1> 能够自动对应到尾部标签去;注意这样的可能存在的嵌套关系匹配替换,可以每次循环迭代把内层的不断替换成一些特殊字符或者空,直到匹配不到为止;
1 | |
中括号 [] 与竖线 |
中括号用来匹配单个字符,是否属于中括号中的一个字符 [0-9] [A-Z] 这样都也是可以的,注意如果待正则匹配的内容中已经具有中括号(其他括号也是同理),需要用 \[ 把其他待匹配的做一个转义的感觉
竖线 | 就是一个或的意思,虽然不知道为什么要和中括号写在一个类别hhh,感觉使用场景上来说还是很灵活的
大括号 {}
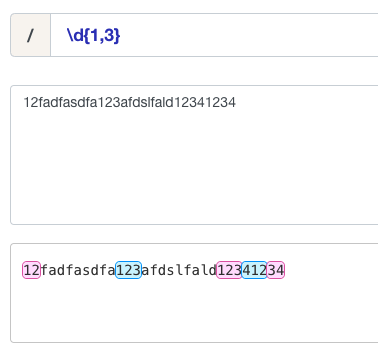
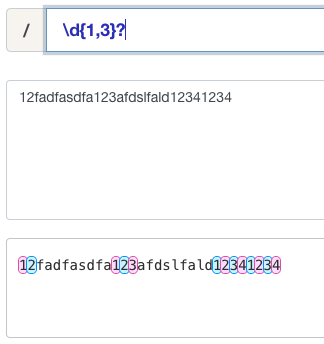
匹配出现几次那种感觉,例如 \\d{1,3} 就是匹配出现一段文本中1次到3次的数字,这里还可以补充一下问号 ? 的作用,有一种最小匹配的感觉
好了,1+1=2学会(废)了!开始搞题!
BJUTACM OJ 2017年12月蓝桥杯预选赛题目ip地址判断
题目大意
于是由于各种各样的原因, 出现了一个叹号。
我们都已经看到了工具下载及比赛规则的地址是 http://172.21.17.211/
下面你就来判断一下一个网址是否符合 http://a.b.c.d/ 的格式吧。 (a, b, c, d 均为长度在 [1, 5] 且由数字 0-9 构成的字符串)
输入
一行字符串。 长度小于50。
输出
如果输入符合要求。 输出 “Yes”。
否则输出 “No” 。
(输出不含引号)
样例输入
1 | |
样例输出
1 | |
分析和解答
这个题对自己影响是真的大,当年蓝桥预选赛靠着这个题在大一上从毫无基础的小白就到学校预选赛的前30名,用C语言一条规则一条规则的适配,AC的那一刻真是最难忘的会议之一~
现在再来做这个题的话,过了这么多年了,发现用非常简单的正则就能写出来,也就把题总结在这里了~
1 | |
65.有效数字
题目大意
有效数字(按顺序)可以分成以下几个部分:
- 一个 小数 或者 整数
- (可选)一个
'e'或'E',后面跟着一个 整数
小数(按顺序)可以分成以下几个部分:
- (可选)一个符号字符(
'+'或'-') - 下述格式之一:
- 至少一位数字,后面跟着一个点
'.' - 至少一位数字,后面跟着一个点
'.',后面再跟着至少一位数字 - 一个点
'.',后面跟着至少一位数字
- 至少一位数字,后面跟着一个点
整数(按顺序)可以分成以下几个部分:
- (可选)一个符号字符(
'+'或'-') - 至少一位数字
部分有效数字列举如下:["2", "0089", "-0.1", "+3.14", "4.", "-.9", "2e10", "-90E3", "3e+7", "+6e-1", "53.5e93", "-123.456e789"]
部分无效数字列举如下:["abc", "1a", "1e", "e3", "99e2.5", "--6", "-+3", "95a54e53"]
给你一个字符串 s ,如果 s 是一个 有效数字 ,请返回 true 。
示例1:
1 | |
示例2:
1 | |
示例3:
1 | |
提示:
1 <= s.length <= 20s仅含英文字母(大写和小写),数字(0-9),加号'+',减号'-',或者点'.'。
分析和解答
这个题要分两部分考虑,首先考虑单独表示一个整数或者小数,然后再考虑科学计数法的内容,科学计数法就是 e-5 或者 e10 这样的
单独考虑整数: [+-]{0,1}\\d+
解释:+- 号可以出现0次或者1次(也可以用 ? 替代), {0,1},\\d+ 匹配整数;
考虑小数,情况1: [+-]{0,1}\\d+\\.\\d+
解释:+- 号可以出现0次或者1次(也可以用 ? 替代),后面是 x.x 形式的小数;
考虑小数,情况2: [+-]{0,1}\\d+\\.
解释:后面是 x. 形式的小数;
考虑小数,情况3: [+-]{0,1}\\.\\d+
解释:后面是 .x 形式的小数;
然后考虑科学计数法,即 从e开始后面的位置 ,情况有:
[eE][+-]?× -> 不能带小数点,因为不能是e2.5次方这样的,所以正则的写法为 ([eE][+-]?\\d+)? ,这里只能匹配一次,所以要把整体的带上括号
※合并上述内容,前边的必须有,科学计数法不一定要有:
(([+-]?\\d+)|([+-]?\\d+\\.\\d+)|([+-]?\\d+\\.)|([+-]?\\.\\d+))([eE][+-]?\\d+)?
※这里还有个坑的内容,例如对于 3. 这种case,如果把整数的匹配写在前面,那么只会优先匹配到 3 了,所以要把小数写在前面,整数写在后面
(([+-]?\\d+\\.\\d+)|([+-]?\\d+\\.)|([+-]?\\.\\d+)|([+-]?\\d+))([eE][+-]?\\d+)?
※补充还有个坑的地方,就是说 1+3 这种case,在后面的话小数部分应该写成 ([eE][+-]?\\d+)? ,而不能写成多一个问号 ([eE]?[+-]?\\d+)? 只有出现了e或者E,才能让+-出现0或1次
非转义的final写法: (([+-]?\d+\.\d+)|([+-]?\d+\.)|([+-]?\.\d+)|([+-]?\d+))([eE][+-]?\d+)?
代码如下所示,这里的注意点是
re.compile(ur'')就可以不用转义各个字符了,转义还是个考虑的重点问题;- 替换成一个特殊字符
#,最后可以用这个特殊字符做一些判断,避免单个e一类的问题;
1 | |
591.标签验证器
题目大意
给定一个表示代码片段的字符串,你需要实现一个验证器来解析这段代码,并返回它是否合法。合法的代码片段需要遵守以下的所有规则:
- 代码必须被 合法的闭合标签包围 。否则,代码是无效的。
- 闭合标签 (不一定合法)要严格符合格式:
<TAG_NAME>TAG_CONTENT</TAG_NAME>。其中,<TAG_NAME>是起始标签,</TAG_NAME>是结束标签。起始和结束标签中的 TAG_NAME 应当相同。当且仅当 TAG_NAME 和 TAG_CONTENT 都是合法的,闭合标签才是 合法的 。 - 合法的
TAG_NAME仅含有大写字母,长度在范围 [1,9] 之间。否则,该TAG_NAME是不合法的。 - 合法的
TAG_CONTENT可以包含其他 合法的闭合标签 ,cdata (请参考规则7)和任意字符(注意参考规则1)除了不匹配的<、不匹配的起始和结束标签、不匹配的或带有不合法 TAG_NAME 的闭合标签。否则,TAG_CONTENT是不合法的 。 - 一个起始标签,如果没有具有相同 TAG_NAME 的结束标签与之匹配,是不合法的。反之亦然。不过,你也需要考虑标签嵌套的问题。
- 一个
<,如果你找不到一个后续的>与之匹配,是不合法的。并且当你找到一个<或</时,所有直到下一个>的前的字符,都应当被解析为 TAG_NAME(不一定合法)。 - cdata 有如下格式:
<![CDATA[CDATA_CONTENT]]>。CDATA_CONTENT 的范围被定义成<![CDATA[和后续的第一个]]>之间的字符。 CDATA_CONTENT可以包含 任意字符 。cdata 的功能是阻止验证器解析CDATA_CONTENT,所以即使其中有一些字符可以被解析为标签(无论合法还是不合法),也应该将它们视为 常规字符 。
合法代码的例子:
1 | |
不合法代码的例子:
1 | |
注意:
- 为简明起见,你可以假设输入的代码(包括提到的 任意字符 )只包含
数字,字母,'<','>','/','!','[',']'和' '。
分析和解答
这个题还是挺难的,也是一种正则表达式的练习吧,总之对正则表达式又熟了一分,想法和题解就写在代码的注释里了
1 | |