Transformer积累阅读
Transformer是Google的研究者在2017年《Attention Is All You Need》论文中提出的用于seq2seq任务的模型,它没有RNN的循环结构或CNN的卷积结构,在机器翻译等任务中取得了一定的提升。
主要的motivation在于RNN、LSTM、GRU类的序列结构中的固有顺序属性阻碍了训练样本之间的并行化,对于长序列,内存限制将阻碍对训练样本的批量处理。
Transformer中完全依赖于注意力机制对输入输出的全局依赖关系进行建模。因为对依赖的建模完全依赖于注意力机制,Transformer使用的注意力机制被称为自注意力(self-attention)
References:
https://zhuanlan.zhihu.com/p/85864250
http://jalammar.github.io/illustrated-transformer/
A High-Level Look
把整个Transformer当做一个黑盒,在机器翻译任务中,一种语言作为Transformer的输入,另外一种经过翻译后的语言作为Transformer的输出。
略微细化下,我们看到Transformer架构由Encoding组件,Decoding组件,还有Encoding Decoding两个组件之间的连接组成。
其中的Encoding组件是一个由encoders组成的栈。Decoding组件是一个由和encoders相同数目的decoders组成的栈。
编码器在结构上都是相同的(但是互相之间不共享权重)。每一层分为两个子层,分别是Self-Attention机制和Feed Forward Neural Network
编码器的输入首先要通过一个self-attention层,一个帮助编码器在编码特定单词时查看输入句子中其他单词的层。将在之后进一步分析。
self-attention层的输出反馈给前馈神经网络(feed forward neural network),完全相同的前馈网络独立应用于每个位置。
解码器具有这两个层,但在这两个层之间有一个Encoder-Decoder注意力层,帮助解码器关注输入句子的相关部分(类似于seq2seq模型中注意力的作用)。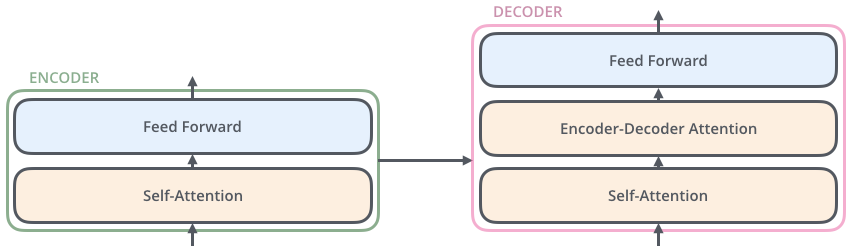
Bringing The Tensors Into The Picture
首先使用embedding算法将每个输入字词转化为向量。使用这种小型的vectors来进行表示。(在SUMBT中,这一步对应了哪一步?为什么这里每个输入字词会变为vectors?)
embedding只发生在最底层的编码器中。所有编码器都有一个共同的抽象概念,即它们接收一个大小为512的向量列表——在底部编码器中是word embedding,在其他编码器中则是直接位于下方的编码器的输出。这个列表的大小是我们可以设置的超参数,基本上是训练数据集中最长句子的长度。
在输入序列中word embedding后,每个单词都会流经编码器的两层。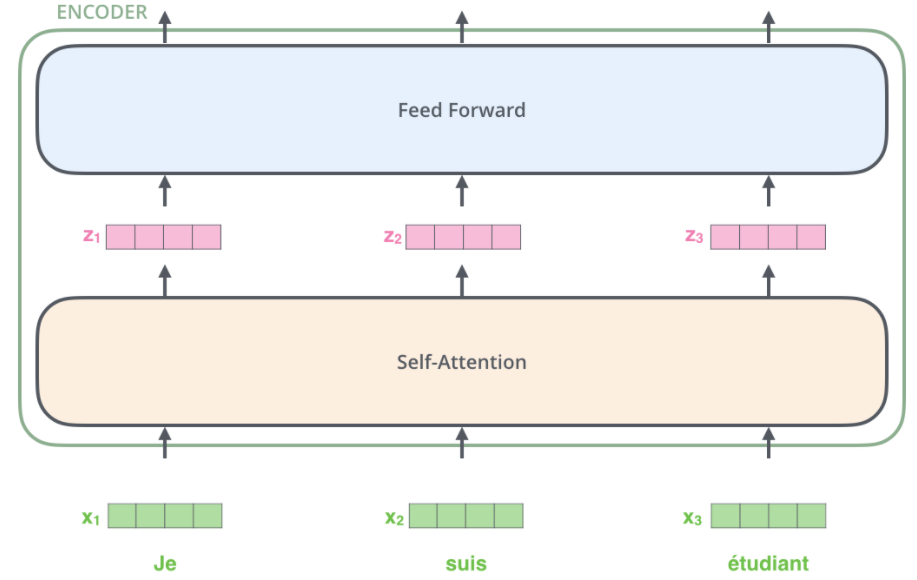
在这里,我们看到Transformer的一个关键属性,即每个位置的字在编码器中通过自己的路径流动。在self-attention层中,这些路径之间存在依赖关系。然而前馈层(feed forward layer)没有这些依赖关系,因此在流经前馈层时,可以并行执行各种路径。
接下来,把示例切换到一个较短的句子,并查看编码器的每个子层中放生了什么。
Now We’re Encoding!
正如我们已经提到的,编码器接收向量列表作为输入(在SUMBT中就是bert embedding后的那些内容)。它通过将这些向量传递到self-attention层,然后传入前馈神经网络,然后将输出向上发送到下一个编码器来处理该列表。
每个位置的单词都经过一个自我注意过程。然后,它们各自通过一个前馈神经网络——一个完全相同的网络,每个向量分别通过它。
Self Attention at a High Level
不要被我胡说“self-attention”这个词所愚弄,因为这是每个人都应该熟悉的概念。在阅读《Attention Is All You Need》这篇论文之前,博客作者从未想到过这个概念。让我们总结一下它的工作原理。
假设以下句子是我们要翻译的输入句子:
1 | |
在这一句子中,“it”指代的是什么?是指代的street还是animal?对于人类这是简单的,但是对于算法这是复杂的
当我们的模型在处理“it”这个单词的时候,self-attention允许把“it”和“animal”联系起来
当模型在处理每个单词的时候(输入语句的每个位置处),self-attention允许其关注输入语句的其他位置来寻求线索,并得出一种对于这个word更好的encoding
如果对RNN足够熟悉,请考虑如何维护hidden state,使得RNN能够将其已处理的先前单词/向量的表示形式与其正在处理的当前单词/向量结合起来。self-attention是Transformer用来将其他相关单词的“理解”bake到我们当前正在处理的单词中的方法。
当我们在编码器#5(堆栈中的顶部编码器)中对单词“it”进行编码时,部分注意力机制将注意力集中在“动物”上,并将其表示的一部分烘焙到“it”的编码中。
这里需要更加明确self-attention机制的输入输出分别是什么,从个人理解来说是3个输入,1个输出?Self-Attention in Detail
让我们先看看如何使用向量计算自我注意,然后继续看看它是如何实际实现的——使用矩阵
计算self-attention的第一步是从编码器的每个输入向量中创建三个向量(在本例中,是每个单词的embedding),所以对于每个单词,我们创建Query vector,一个Key vector, 和一个Value vector。这些向量是通过将embedding乘以我们在训练过程中训练的三个矩阵来创建的
突然注意到768 / 64 = 12请注意,这些新向量的维数小于嵌入向量,它们的维数为64,而且如和编码器输入/输出向量的维数为512。它们不必更小,这是一种架构选择,可以使用MultiHeadAttention(多头注意力机制)来使得计算保持不变(这里是指维度?)
将x1乘以WQ权重矩阵生成q1,即与该单词相关联的“查询”向量。我们最终创建了输入句子中每个单词的“查询”、“键”和“值”投影。
(差一张手画的图插进来)
什么是query key value向量?
根据师兄的解释,query感觉可以理解成一个自己的内容信息,而key理解成一个别人的信息,这样在和别人进行比较的时候就是上是用自己的q和别人所有的k进行比较它们是用于计算和思考注意力机制的抽象概念,继续阅读下面的注意力是如何计算的,就会知道关于每个向量所扮演角色的几乎所有内容。
计算self-attention的第二步是计算分数,假设我们正在计算本例中第一个单词“Thinking”的自我关注度。我们需要给输入句子中的每个单词打分。分数决定了当我们在某个位置对一个单词进行编码时,要把多少注意力放在输入句子的其他部分上。
分数是通过将query向量的点积与我们正在评分的各个单词的key向量相结合来计算的。因此,如果我们处理位置#1的单词的自我注意,第一个分数将是q1和k1的点积。第二个分数是q1和k2的点积。(点积将会得到一个分数)

第三步和第四步是将分数除以8(论文中使用的关键向量维数的平方根–64。这会导致更稳定的梯度。这里可能有其他可能的值,但这是默认值),然后通过softmax操作传递结果。Softmax将分数标准化,使其全部为正值,加起来等于1。
此softmax分数确定每个单词在此位置的表达量。很明显,这个位置上的单词将具有最高的softmax分数,但有时关注与当前单词相关的另一个单词会很有用。
第五步是将每个值向量乘以softmax分数(准备将他们相加)。这里的直觉是保持我们想要关注的单词的完整值,并忽略不相关的单词(例如,将它们乘以0.001这样的小数字)
第六步是对加权值向量求和。这将在该位置(对于第一个单词)生成自我注意层的输出。
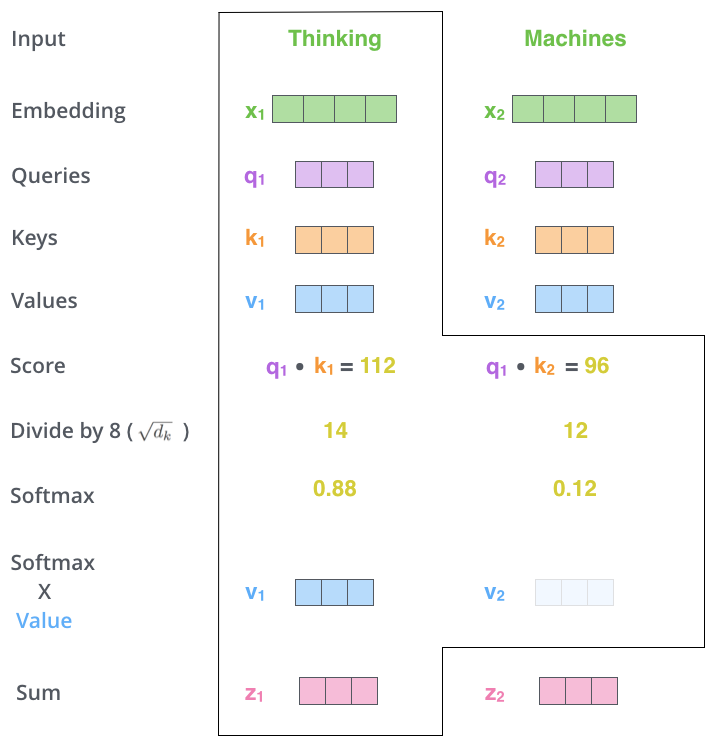
自我注意力计算到此结束。结果向量是我们可以发送到前馈神经网络的向量。然而,在实际实现中,这种计算是以矩阵形式进行的,以加快处理速度。现在我们来看一下,我们已经看到了单词级计算的直觉。
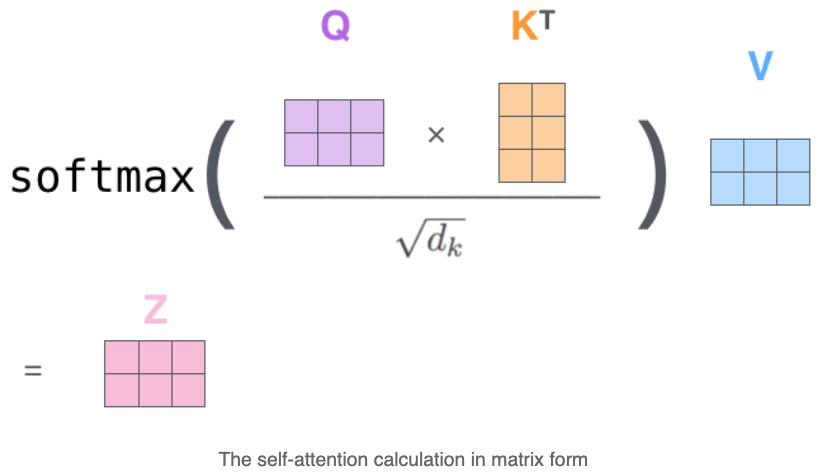
Matrix Calculation of Self-Attention
第一步是计算查询、键和值矩阵。我们通过将嵌入项打包到矩阵X中,并将其乘以我们训练的权重矩阵(WQ,WK,WV)来实现这一点。
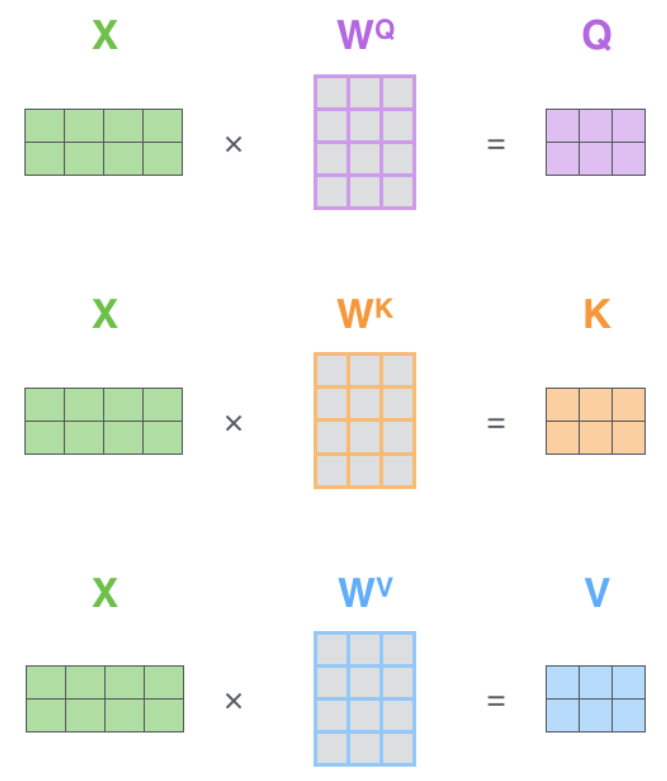
X矩阵中的每一行对应于输入句子中的一个单词。我们再次看到嵌入向量(512,或图中的4个框)和q/k/v向量(64,或图中的3个框)的大小差异
最后,由于我们处理的是矩阵,我们可以将第二步到第六步浓缩成一个公式来计算自我注意层的输出。
The Beast With Many Heads
本文通过添加了一种称为“Multi-Head”注意力的机制,进一步细化了self-attention层。从这两个方面提高了注意层的性能:
它扩展了模型关注不同位置的能力。是的,在上面的例子中,z1包含了一些其他单词所产生的编码,但是它可能被更加实际的单词本身所支配(这里是指权重比较高?)。如果我们翻译一句话,比如“动物没有过马路是因为它太累了”,我们会想知道“它”指的是哪个词。
它为注意力层提供了多个“表示子空间”(有一种增大参数量的感觉?)。正如我们接下来将要看到的,对于multihead-attention,我们不仅有一组,而且有多组query/key/value权重矩阵(Transformer使用8个attentionhead,因此每个编码器/解码器有8组)。这些集合中的每一个都是随机初始化的。然后,在训练之后,使用每个集合将输入embedding(或来自较低编码器/解码器的向量)投影到不同的表示子空间。

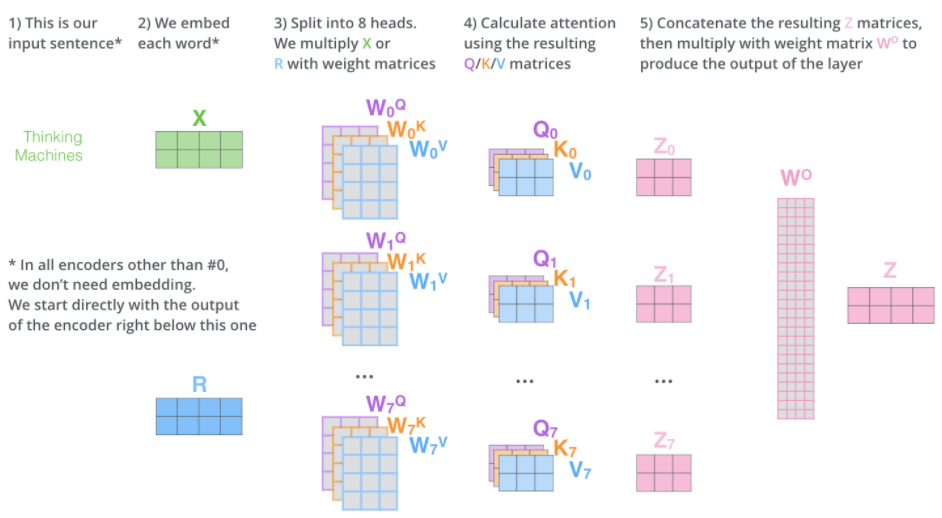
通过multihead-attention,我们为每个head维护单独的Q/K/V权重矩阵,从而产生不同的Q/K/V矩阵。和前面一样,我们用X乘以W^Q/W^K/W^V矩阵,得到Q/K/V矩阵。
如果我们做上边所述的同样的self-attention计算,只需使用不同的权重矩阵进行八次不同的计算,我们最终得到八个不同的Z矩阵。
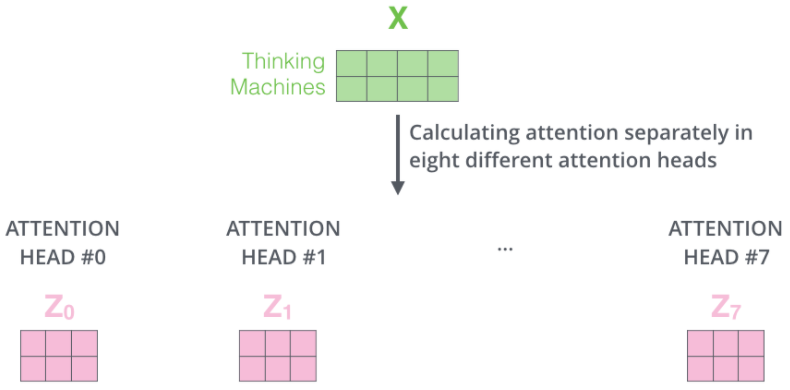
这给我们留下了一点挑战,前馈层不需要八个矩阵,它需要一个矩阵(每个单词对应一个向量(自:这里说的是z?))。所以我们需要一种方法把这八个元素压缩成一个矩阵。
我们怎么做?我们将矩阵合并(concatenate),然后将它们乘以一个额外的权重矩阵W^O。
这里感觉是concate表示了的不行,还要把这些融合到一起才行?或者说要保证输入的X和输出的Z是shape相同的? multi-head如果是这样的操作的话就是一种增加参数量的作用? 其亮点还主要在于“平权”的对待各个位置处,起到一种self-attention的作用。
这几乎就是multi-head attention的全部内容。这是相当多的矩阵,如果把他们放在一个图表示就可以更直观的看到这个过程。
既然我们已经谈到了multihead attention,那么让我们回顾一下之前示例,看看在我们的示例语句中对单词“it”进行编码时,不同的注意力头集中在哪里。

当我们对“它”这个词进行编码时,一个注意力集中在“动物”身上,而另一个注意力集中在“疲劳”身上——从某种意义上说,模型对“它”这个词的表达同时包含了一些“动物”和“疲劳”的表达。
然而,如果我们把所有的注意力都放在画面上,事情就更难解释了:
