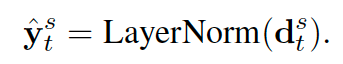DST论文阅读-SUMBT
SUMBT: Slot-Utterance Matching for Universal and Scalable Belief Tracking论文阅读笔记
SUMBT: 槽-话语匹配的对话状态跟踪器,用来进行通用和可扩展的信念跟踪
References:
Lee H, Lee J, Kim T Y. SUMBT: Slot-Utterance Matching for Universal and Scalable Belief Tracking[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 5478-5483.
对话状态跟踪学习笔记:https://blog.csdn.net/zerozzl01/article/details/112215175
注:分段和作者的文章不一定相同
一些基础概念的个人笔记补充
简介
对话状态跟踪(dialogue state tracking)是任务型(task-oriented)对话系统中的一部分。更具体的来说,是对话管理中的一部分。对话状态是从对话开始到当前对话的用户目标的总结,通常表现为多组槽-值(slot-value)的组合的形式,有时也会包括对话所属的领域、用户意图等信息。对话状态跟踪是指结合对话历史、当前对话、前一轮对话状态等信息,推断并更新当前对话状态的过程
关键概念
1)领域(domain):可以理解为业务场景,如hotel、train、restaurant等。
2)意图(intention):用户话语的目的,如请求信息、提供信息、确认信息等。
3)槽(slot):槽指某种信息,与完成任务所需要获得的某种信息相对应。比如在预定酒店这个任务中,相关的槽有name、area、price range等。餐馆示例:[area, food, price range]
4)本体(ontology):数据集中,涉及到的所有领域、意图、槽以及相关的所有值构成的数据字典,称为该数据集的本体。
评价指标
1)联合目标准确率(joint goal accuracy)/ 联合状态准确率(joint state accuracy):一般也简称joint accuracy。对于每轮对话,将预测的对话状态和真实的对话状态进行比较,当且仅当对话状态中所有的(domain,slot,value)预测正确时,才认为对话状态预测正确。
问题记录:
这里需要结合论文所给出的代码查看下联合目标准确率的具体含义,到底是不是一次对话过程中,全部状态正确才算正确?
2)槽位准确率(slot accuracy):单独比较每个(domain,slot,value),当预测值与真实值匹配时,认为预测正确。
3)推断时间复杂度(inference time complexity, ITC):ITC的计算方式是完成一次对话状态预测,需要inference多少次。ITC越小越好。
Abstract
在面向目标(goal-oriented)的对话系统中,信念跟踪器(belief trackers)预测每个对话回合时的槽值对概率分布。以前的神经网络方法已经为领域(ontology)和槽依赖的belief trackers进行了建模,导致领域本体配置缺乏灵活性。
问题记录: 以往的方法,建模的跟踪器都是领域/槽位依赖的,所以欠缺领域本体设置的灵活性。作者把这些以往的方法统称为slot-dependent methods。这个地方怎么理解,欠缺设置的灵活性?在本文中,作者提出了一种新的通用(universal)并可扩展(scalable)的信念跟踪器方法,被称作slot-utterance matching belief tracker(槽-话语匹配的对话状态跟踪器,SUMBT)。模型通过基于上下文语义的注意力机制来学习领域槽类别(domain-slot-types)与对话中出现的槽-值对之间的关系。更进一步的,模型通过一种非参数的方法预测槽-值对的值。
这里所说的“基于上下文语义的注意力机制”类似就是用BERT作为tokenizer的这个感觉?根据作者在两个对话语料库WOZ2.0和MultiWOZ上的实验结果,与槽依赖的方法相比,该模型的性能有所提高,并达到了最先进的joint accuracy。
还要通过后文的阅读,理解这里作者所说的槽依赖(slot-dependent)的方法到底和作者所提的方法有什么不同。Introduction
随着会话代理的广泛使用,面向目标的系统越来越受到学术界和工业界的关注。面向目标的对话系统帮助用户实现目标,如在对话结束时预定餐厅或预定航班。随着对话的进行,系统需要更新对话状态的分布,对话状态包括用户的意图、可信息的槽位、和可请求的槽位。这被称作belief tracking(信念跟踪)或者被称作dialogue state tracking(对话状态跟踪, DST)。
问题记录: 这里对应到数据集上到底在预测什么,除了槽值对外,看起来还有很多需要记录的地方?例如,对于给定的域(domain)和槽类型(slot-types),(例:‘restaurant’ domain 和 ‘food’ 槽类型),这个任务估计了在领域本体中预定义的,相对应的候选槽值对(slot-value)概率(例:‘Korean’和‘Modern European’)
由于系统使用DST的预测输出,根据对话策略(Policy Learning环节?)选择下一个操作,因此DST的准确性对于提高系统整体性能至关重要。此外,对话系统应该能够以灵活的方式处理新添加的域和槽,因此开发可伸缩的对话状态跟踪器是不可避免的。 关于这一点,Chen等人提出一种从意图-话语对中捕捉关系的模型,用于意图扩展。
问题记录: 这里说以灵活的方式处理新添加的域和槽,这个不应该都是已定义好的,为什么会能增加,作者一直在围绕着可扩展性讲故事。(相对于去雾类的论文中的一些idea,这些想法是否属于在NLP领域中直观的想法)传统基于统计方法的belief trackers容易受到词汇和形态变化的影响,因为他们依赖于手动构建的语义词典。随着深度学习方法的兴起,一些neural belief trackers(NBT)被提出,并通过学习单词的语义神经表征来提高性能。然而,可扩展性仍然是一个挑战,先前提出的方法要么对每个域、槽单独建模,要么难以添加本体中未定义的新槽值。
在本文中,我们致力于开发一个“可伸缩”和“通用”的belief tracker,其中只有一个信念跟踪器用于处理任何域和槽类型。为了解决这个问题,我们提出了一种新的方法,称为slot-utterance matching belief tracker(槽-话语匹配的对话状态跟踪器),他是一种与域和槽独立的对话状态跟踪器,其结构如figure 1所示。
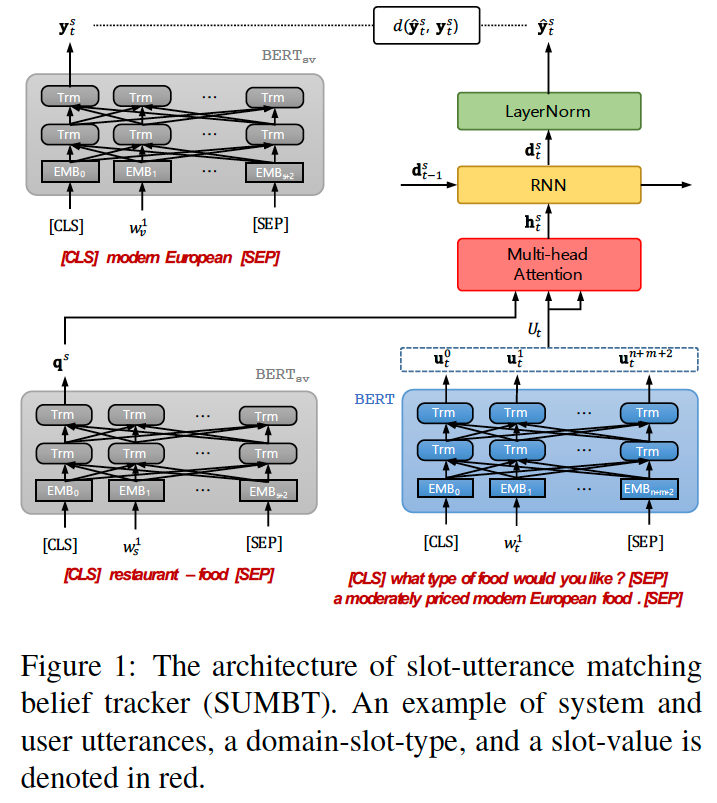
灵感来自机器阅读理解技术,SUMBT考虑domain-slot type这个组合(例如 ‘restaurant-food’)将其视为一个问题,并在一对用户和系统话语中找到相应的槽值对,假设话语中存在期望的答案。
SUMBT使用最近提出的BERT对系统和用户的话语(utterance)进行编码,BERT提供句子的语境化语义表示。此外,domain-slot-types 和 slot-values也使用BERT进行字面编码
上边的意思是,这几个地方都会被BERT编码: [CLS] what type of food would you like? [SEP] a moderately priced modern European food.[SEP][CLS] restaurant - food [SEP]
[CLS] modern European [SEP]
然后SUMBT根据上下文语义向量,学习与话语词中domain-slot-type相关的“参加方式(the way where to attend)”。该模型基于某些度量以非参数方式预测slot-value的标签,从而使模型体系结构在结构上不依赖于域和slot-types。因此,单个SUMBT可以处理一对domain-slot-type和slot-value,还可以利用多个域和槽之间的共享知识
或许这篇文章是比较早把BERT结合进来的操作?作者在两个目标面向的对话语料库:WOZ2.0 和 MultiWOZ 上通过实验证明该提议模型的有效性。还将定性分析该模型的工作原理。并将其实现公开发布。
SUMBT
所提出的模型由4部分组成,就像图1中所示的。
① BERT encoders,用来对【槽】,【值】,【话语】进行encoding(图中的灰色和蓝色部分)
② 一个 slot-用户话语匹配的network(图中的红色部分)
③ 一个对话状态跟踪器(图中的橙色部分)
④ 一个无参数的鉴别器(discriminator,图中的最上端虚线连接)
Contextual Semantic Encoders
对于句子编码器,我们采用了预训练的BERT模型,这是一个双向Transformer编码器的深层堆栈。与普通的词向量相比,这种方式提供了上下文带有语义化的词向量。更进一步的,它提供了词句和句子等词序列的聚合表示,因此我们可以获得由多个词组合的slot-types或slot-values。
这里主要记录下:
slot-values: [[area_slot1, area_slot2, area_slot3…], [food_slot1, …], [price_range_1, …]]
slot-types: [area, food, price range]
经过一系列操作处理后:
y_vt label_token_ids根据v_t slot-values得到: [torch.Size([7, 32]), torch.Size([xx1, 32]), torch.Size([xx2, 32])],这里xx1,xx2分别代表food和price range的标签数目
q_s slot_token_ids根据s domain-slot-types得到: torch.Size([3, 32]),因为在WOZ这个数据集中只有3个label
Slot-Utterance Matching
为了从话语中检索与domain-slot-type(area,food,price range)对应的相关信息,该模型使用注意力机制。把domain-slot-type经过encoder的encoded vector q^s作为一个query,将其与【每个each】单词位置的上下文语义向量u相匹配,然后计算注意力分数。
这里,作者采用了multi-head attention的注意力机制。多头注意力机制将查询矩阵Q、key矩阵K和value矩阵V映射为不同的线性h投影,然后在这些矩阵上执行缩放点积注意力机制。slot s 和 t处的话语之间的有注意上下文向量hst是:

Belief Tracker 对话状态跟踪器
随着对话的进行,每个回合的belief state由之前的对话历史和当前的对话回合决定。这个对话流可以被RNN类的LSTM和GRU,或者Transformer decoders建模(例如:left-to-right uni-directional Transformers)
在本项工作中,上下文向量h_t,还有RNN的上一个state被送入到RNN中,这是用来学习与目标的slot-values相接近的语义向量
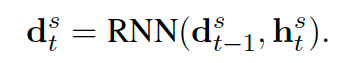
作者考虑到BERT是使用layer normalization进行nomal化的,RNN输出的d_t也被送入到一个layer normalizaiton层,来帮助训练训练收敛。